




 本文详细介绍了Alibaba开源的Canal组件,基于binlog的增量日志解决方案。涵盖Canal的工作原理、binlog的概念及作用、Canal的下载与配置流程、工作流程以及使用方法。同时,提供了Canal的Java客户端示例代码,帮助读者快速上手。
本文详细介绍了Alibaba开源的Canal组件,基于binlog的增量日志解决方案。涵盖Canal的工作原理、binlog的概念及作用、Canal的下载与配置流程、工作流程以及使用方法。同时,提供了Canal的Java客户端示例代码,帮助读者快速上手。
一: Canal概述
canal是由Alibaba开源的一个基于binlog的增量日志组件,其核心原理是canal伪装成Mysql的slave,发送dump协议获取binlog,解析并存储起来给客户端消费。
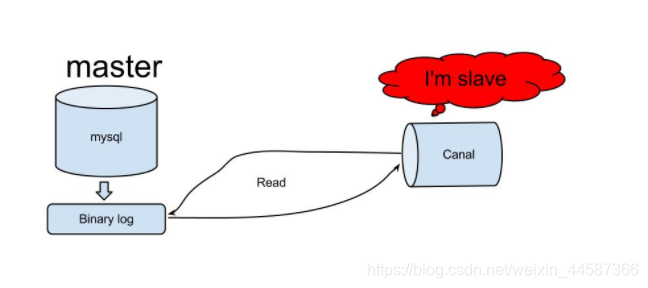
二: 什么是binlog?
- binlog日志用于记录所有更新了数据或者已经潜在更新了数据(例如,没有匹配任何行的一个DELETE)的所有语句。语句以“事件”的形式保存,它描述数据更改。
- 一般Mysql开启binlog功能主要用于两方面: 数据备份,主从复制
- binlog的三种格式:
Row:不记录sql语句上下文相关信息,仅保存哪条记录被修改。
优点:binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以 rowlevel的日志内容会非常清楚的记录下 每一行数据修改的细节。
缺点:日志量太大(canal对这种模式的binlog支持的比较好)
Statement:每一条会修改数据的sql都会记录在binlog中。
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提升性能。
缺点:容易出现主从不一致
Mixedlevel:两者的结合,MySQL 会根据执行的每一条具体的 SQL 语句来区分对待记录的日志形式,也就是在 statement 和 row 之间选择一种。
三: Canal下载
四: Canal工作流程
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流 )
 (个人大数据机器学习公众号,啊哈哈哈,你不关注一下吗?)
(个人大数据机器学习公众号,啊哈哈哈,你不关注一下吗?)
五: Canal使用
- 开启Mysql数据库binlog,并设置为row格式
- 为数据库创建用户,并赋予REPLICATION SLAVE, REPLICATION CLIENT的权限,否则用这些用户连接canal时,无法读取binlog. (默认的root账户肯定也可以)
- 解压下载的canal.deployer-1.1.1.tar.gz到指定的任意目录
mkdir canal
tar -zxvf canal.deployer-1.1.1.tar.gz4.解压下载的canal.deployer-1.1.1.tar.gz到指定的任意目录
vi canal/conf/example/instance.properties#################################################
## mysql serverId
canal.instance.mysql.slaveId = 1234
#position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp =
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#username/password,需要改成自己的数据库信息
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
canal.instance.defaultDatabaseName =
canal.instance.connectionCharset = UTF-8
#table regex
canal.instance.filter.regex = .\..
#################################################5.启动canal
sh bin/startup.sh6.查看日志是否正常启动
tail -300 logs/canal/canal.log具体instance的日志
tail -300 logs/example/example.log7.编写java client程序
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.1</version>
</dependency>
</dependencies>package com.mytest.canal;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import com.mytest.canal.bean.CanalStuMsgBean;
import com.mytest.canal.bean.CanalStuScoreBean;
import com.mytest.canal.bean.StudentMsgBean;
import com.mytest.canal.bean.StuentScoreBean;
import com.mytest.kafka.KafkaProduceUtils;
import com.mytest.utils.DateUtil;
import java.net.InetSocketAddress;
import java.util.ArrayList;
import java.util.List;
public class CanalClientTest {
private static KafkaProduceUtils kafkaProduceUtils;
public static StringBuilder builder = new StringBuilder();
public static void main(String args[]) {
// kafkaProduceUtils = new KafkaProduceUtils("my_test_topic");
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 12000;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} catch (Exception e) {
e.printStackTrace();
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}8.运行上述java程序
9.对mysql数据库进行操作,建表,插入数据,观察java client端是否有对应数据库日志打印出来
10.关闭java client, 关闭 canal server
sh bin/stop.sh官网相关链接: https://github.com/alibaba/canal/wiki
六: Canal一些需要注意的点
- 一个Canal可以又多个instances, 一般来说,每个instance对应一个mysql实例
- 理论上,每个Canal可以支持数十个instance,但是instance的个数最终会影响instance同步数据的效能。建议一个Canal尽量保持一个instance
- 每个Canal 集群应该至少有2个Canal实例,软硬件配置应该对等。我们不应该在同一个Cluster的多个节点上,配置有任何差异
- Canal高可用其实是以instance为最小粒度,每个Canal都会去争夺instance,争夺成功的机器写入zookeeper的znode,当某个instance挂掉之后,会重新争夺,后期会针对这一块专门进行研究,将会第一时间在博客和公众号发布。
公众号: 手把手的从零开发一些大数据项目
大数据机器学习分享


















 1962
1962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









