



同步发布于个人博客
基本步骤
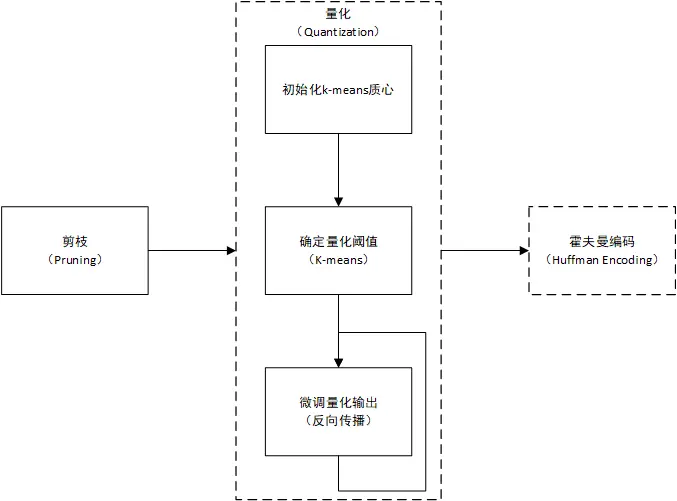
以上是Deep compression中所述的神经网络压缩方法,主要包括三个步骤:
- 剪枝:将部分很小的(认为不重要的)权值设为0,使权值矩阵转为一个稀疏矩阵
- 量化:将剪枝后保留的权值进行量化,使剪枝后保留的权值共享一些的使用一些值,这样可以减小保存权值使用的空间,进一步压缩所需要的存储空间
- 霍夫曼编码(可选):霍夫曼编码是一种编码形式,可以减小数据的保存需要的存储空间
经过以上的步骤,神经网络的存储空间可以被压缩到一个很小的值,同时提高预测运行的速度,降低功耗,且并几乎不损失准确率。
剪枝
剪枝的实现非常方便,即设定一个阈值,绝对值大于这个阈值的权值被保留,其他权值被置0,公式如下所示:
剪枝过后,权值矩阵由稠密矩阵转为稀疏矩阵(或由稀疏矩阵转为更稀疏的矩阵),由此权值矩阵可以使用存储稀疏矩阵的压缩存储方式存储,例如CSR(compressed sparse row) 或CSC(compressed sparse column)。该论文在CSR和CSC的基础上,将index上的值由绝对坐标转为偏移量,如下所示:
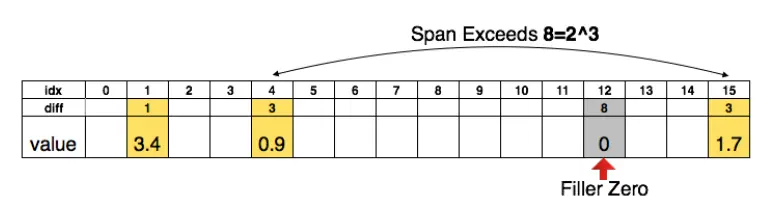
即原来的存储方式为:
| idx | 1 | 4 | 15 |
|---|---|---|---|
| value | 3.4 | 0.9 | 1.7 |
现在的存储方式为:
| diff(3bit) | 1 | 3 | 8 | 3 |
|---|---|---|---|---|
| value | 3.4 | 0.9 | 0 | 1.7 |
这样的好处是diff可以使用更少的bit为存储,若发生偏移量超过bit位可表示的范围时,插入额外的0以补齐偏移。
量化
量化是一种近似的过程,以适度的误差为代价,使无限精度(或很高精度)的数值可以使用较少的位数表示。这里的量化是指定一系列值,使所有的权值都从中进行选择,即完成所有权值的数值共享。该过程分为以下几个步骤:
- 初始化k-means质心:因为量化过程通过k-means实现,k-means质心的初值对结果的影响很大,有三种方法:均匀量化,随机量化和按密度量化,论文中证明使用均匀量化的初始化效果较好,均匀量化的量化输出为在权值的最大值和最小值之间隔均匀的去量化输出,如下所示,其中n为量化的位数:
- 确定量化阈值:即确定对于每一个权值使用哪个量化输出代替值,这一步通常使用一维的k-means确定,k-means的初值由上一步确定。一个簇内的权值均共享一个值(质心值)。需要注意的是,一旦某个权值指定了使用量化输出的值量化,这一选择关系不再发生改变,即使下一步量化输出微调后单个权值的量化误差变大。
- 进行微调:对k-means的质心再进行微调,参考为反向权值,如下图所示:
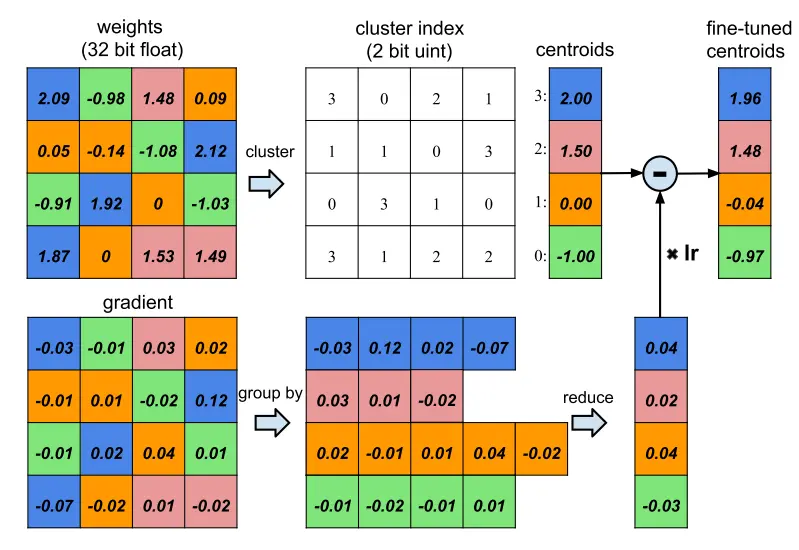
微调过程中,首先进行正常的前向传播和反向传播,注意由于由于剪枝的作用,矩阵已经成为稀疏矩阵,权值矩阵中为0表示该连接被移除,因此这些位置的梯度被舍弃(置0)。微调的对象为类聚质心即量化后的输出。上一步完成后,每一个权值对应的簇已经确定,在图中的cluster_index表示量化类聚的结果,同时该结果在weights和gradient的图中以颜色标注,例如weights中的2.09(第一行第一列)和2.12(第二行第四列)为同一簇,量化后使用同一值表示。
当生成梯度矩阵后,对类聚质心进行微调,微调的方式是对属于同一簇的所有权值对应的梯度进行求和,乘以学习率,再从质心中减去,公式如下:
其中为第n次微调后的结果,lr为学习率,为类聚属于k簇的所有权值构成的集合,表示权值w对应的梯度。微调过程的初值为k-means输出的类聚质心。
完成量化后,原来的稀疏矩阵变为一个稀疏矩阵加一个查找表,即原来的稀疏矩阵存储权值w的位置变为存储w所属簇编号k,簇编号k的位数小于权值w的位数,达到了压缩的目的。查找表索引为簇编号,值为该簇的类聚质心(量化输出)。还原一个矩阵的过程变为首先从稀疏矩阵中读出对应的簇编号,再从查找表中查找该类对应的值。如上图的例子,存储结果为:
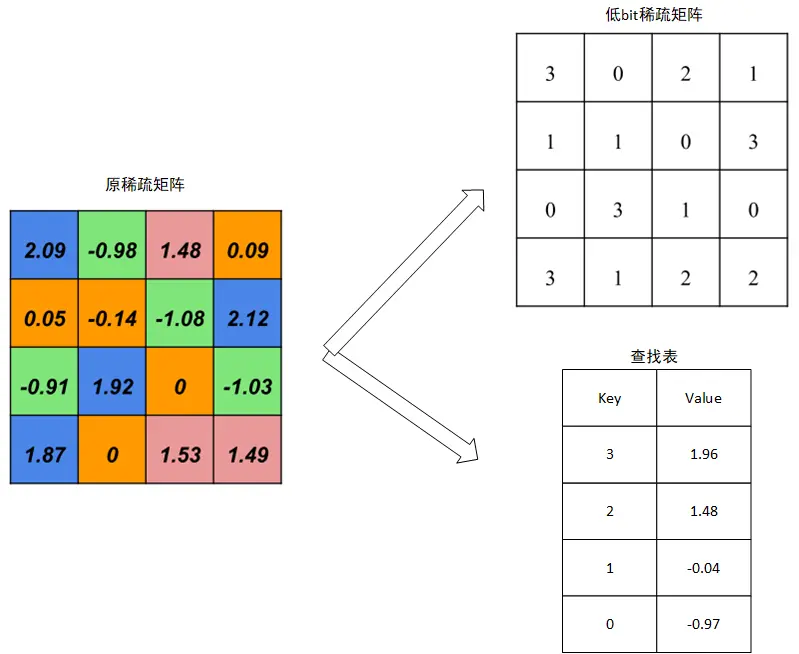
霍夫曼编码
霍夫曼编码是进一步压缩的方式,这种编码使用变长编码表进行编码,可以进一步压缩存储所需要的空间,在进行运算的过程中从霍夫曼编码的存储中解码出所需要的数据即可。
相关分析
量化过程
压缩比
这里的考虑的压缩比主要是量化带来的,因为剪枝的压缩比与权值的值情况密切相关,而量化的压缩比主要是由使用低bit的数表示高精度数带来的,公式如下:
其中n是权重的数量,b为未量化矩阵的位数,k为量化簇的数量。即每个权值量化后可以使用bit表示,这样所有的权值需要的bit数就是,初次之外,还需要一张有k个值的查找表,存储需要的bit数为
反向传播
反向传播过程中微调的对象是类聚质心,因此考虑量化误差为:
这恰好与k-means相符,因此使用k-means进行量化可以尽量减小量化误差。进行微调时,需要考虑量化质心对结果的影响,即量化质心对网络代价函数的影响,梯度传播公式如下:
其中为indicator函数(条件成立为1,否则为0),这一公式与量化的微调过程完全对应。
性能分析
压缩率vs准确率
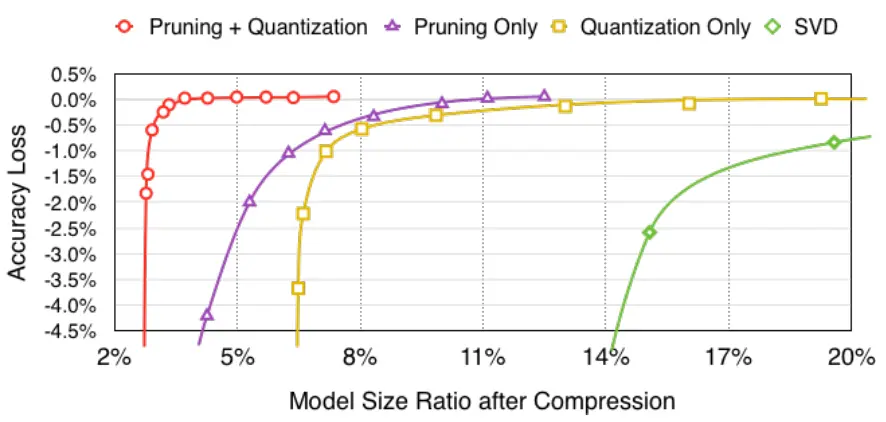
上图描述了压缩率和准确率的关系,在可以发现无论是单独使用量化与剪枝还是组合使用,都可以在一定的压缩率下达到不损失精度的压缩,同时效果均优于SVD
量化位数vs准确率
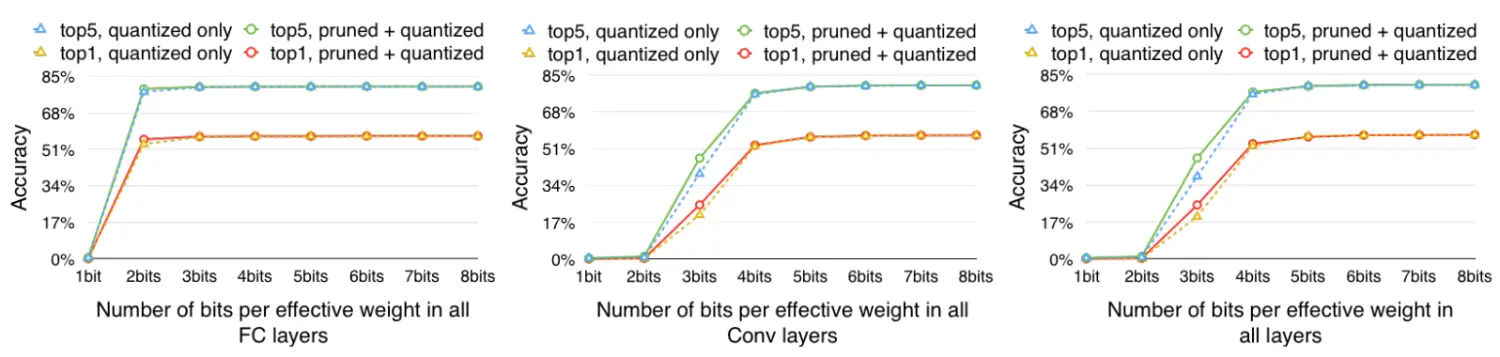
上图表明了量化位数对准确率的影响,同时也表示剪枝过程对量化的影响。可以发现对于论文评估的这种网络,全连接层使用2bit量化,卷积网络使用5bit量化就可以达到很好的结果,同时剪枝对量化的影响很小,可以认为两个过程互不干扰。
质心初始化方法
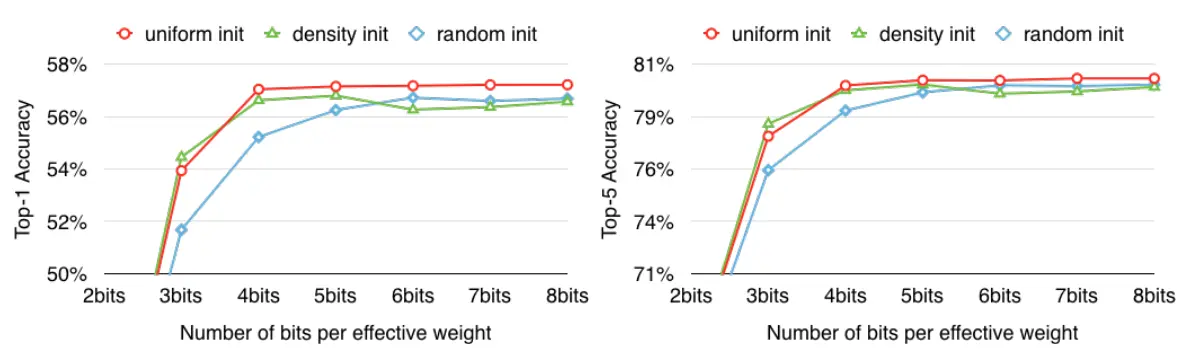
上图表示的是三种不同的初始化方式对压缩后的准确率的影响,可以发现线性量化的初始化方式比较优秀。论文中分析因为较大的权值对结果影响比较大,但是这种权值的数量较小,使用线性初始化的方式倾向于生成一些比较大的类聚质心。
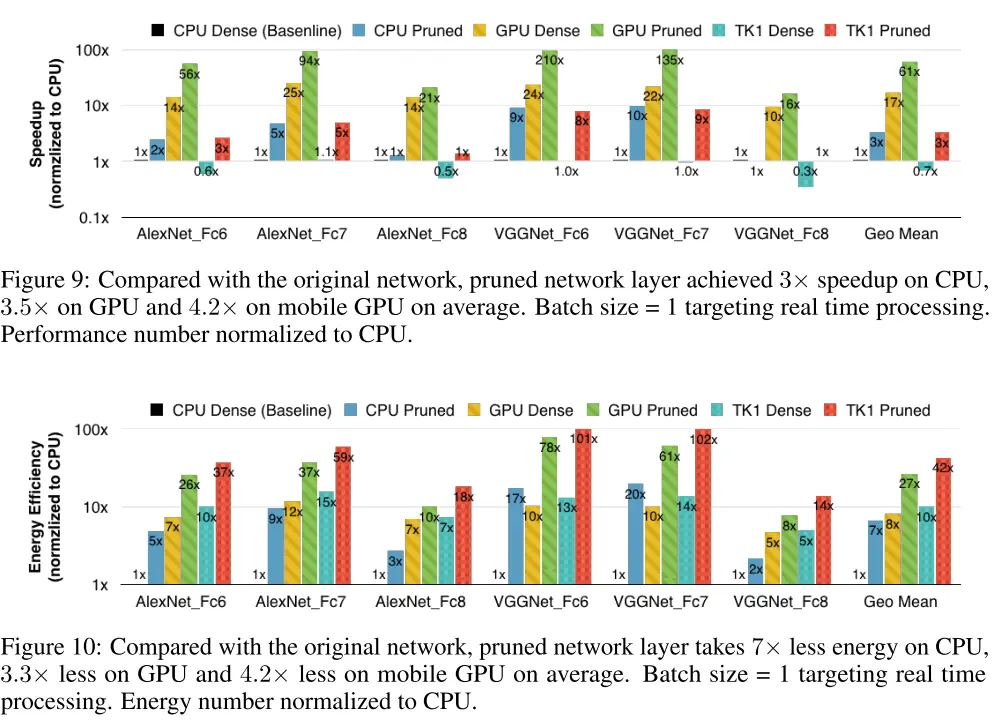
运行速度与功耗
总结
Deep compression的方法概括为剪枝+量化+霍夫曼编码,可以在不损失精度的情况将神经网络压缩,其中对于AlexNet可以压缩35倍,VGG-16可以压缩49倍,且推理时使存储的应用更有效。目前,剪枝/稀疏矩阵的运算已经广泛被各种框架支持,然而量化的支持很少,因此可以考虑重写CPU库或设计专用ASIC以实现量化网络的高效运算。

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









