






一、隔离性和隔离级别
ACID(Atomicity、Consistency、Isolation、Durability,即原子性、一致性、隔离性、持久性),今天我们就来说说其中 I,也就是“隔离性”。
当数据库上有多个事务同时执行的时候,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题,为了解决这些问题,就有了“隔离级别”的概念。
在谈隔离级别之前,你首先要知道,你隔离得越严实,效率就会越低。因此很多时候,我们都要在二者之间寻找一个平衡点。SQL 标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )。下面我逐一为你解释:
- 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化,顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
读未提交:别人改数据的事务尚未提交,我在我的事务中也能读到。
读已提交:别人改数据的事务已经提交,我在我的事务中才能读到。
可重复读:别人改数据的事务已经提交,我在我的事务中也不去读。
串行:我的事务尚未提交,别人就别想改数据。
图示展示隔离级别为:
- 若隔离级别是“读未提交”, 则 V1 的值就是 2。这时候事务 B 虽然还没有提交,但是结果已经被 A 看到了。因此,V2、V3 也都是 2。
- 若隔离级别是“读提交”,则 V1 是 1,V2 的值是 2。事务 B 的更新在提交后才能被 A 看到。所以, V3 的值也是 2。
- 若隔离级别是“可重复读”,则 V1、V2 是 1,V3 是 2。之所以 V2 还是 1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
- 若隔离级别是“串行化”,则在事务 B 执行“将 1 改成 2”的时候,会被锁住。直到事务 A 提交后,事务 B 才可以继续执行。所以从 A 的角度看, V1、V2 值是 1,V3 的值是 2。
在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。在“读提交”隔离级别下,这个视图是在每个 SQL 语句开始执行的时候创建的。这里需要注意的是,“读未提交”隔离级别下直接返回记录上的最新值,没有视图概念;而“串行化”隔离级别下直接用加锁的方式来避免并行访问。
二、隔离的实现 MVCC
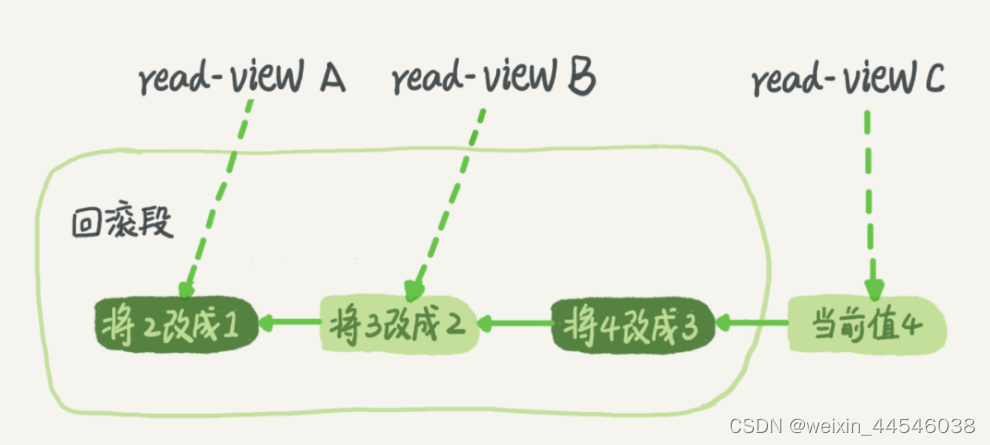
当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于 read-view A,要得到 1,就必须将当前值依次执行图中所有的回滚操作得到。
三、事务的启动
避免长事务:
长事务,运行时间比较长,长时间未提交的事务
set autocommit=0,这个命令会将这个线程的自动提交关掉。意味着如果你只执行一个 select 语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行 commit 或 rollback 语句,或者断开连接。所以设置set autocommit=1避免长事务。
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
查询长事务在information_schema表中

















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









