






经过上一篇总结了关于数据结构与算法的基础知识数据结构与算法两者之间的关系。我们知道了数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或者多种特定关系的数据元素的集合。而大部分数据结构的实现都需要借助C语言中的指针和结构体类型。
下面对常见的数据结构和常用算法知识进行总结。
我们知道数据结构研究对象可以分为逻辑数据结构和存储(物理)数据结构两种。但对数据结构进行分类,数据结构可分为很多种,如按照数据的逻辑结构对其进行简单的分类,可以分为线性结构和非线性结构,而且还可以对这两种结构进行细分,那就是平时所说的常见的人八大数据结构。
一、常见的数据结构:
(1)数组(Array)
数组是一种聚合数据类型,它将具有相同类型的若干个变量有序地组织在一起的集合。数组可以说是最基本的数据结构,在各种编程语言中都有对应。一个数组可以分解为多个数组元素,按照数据元素的类型,数组可以分为整型数组、字符型数组、浮点型数组、指针数组以及结构数组等。数组还可以有一维、二维以及多维等表现形式。
(2)栈(Stack)
栈是堆栈的简称,是一种特殊的线性表,它限定只能在一个表的一个固定端进行数据节点的插入与删除操作。在表中,允许插入和删除的一端称作“栈顶”,另一端称作“栈底”。通常将元素插入栈顶的操作称为“入栈”(进栈或压栈),称删除栈顶的操作为“出栈”。栈按照后进先出的原则来存储数据,简单点来讲就是,后面来的数据反而能最先走,所以我们说它是“蛮不讲理的堆栈”。(出入栈如图)
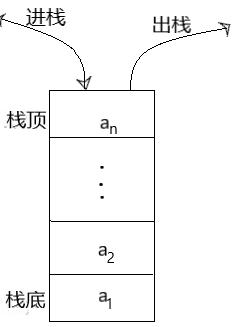
栈的基本运算:
(1)StackInit()初始化堆栈
(2)StackEmpty(s)判断栈s是否为空
(3)StackLength(s)求堆栈s的长度
(4)GetTop(s)获取栈顶元素的值
(5)Push(s,e)将元素e进栈
(6)Pop(s),出栈(删除栈顶元素)
栈的存储结构:(两种存储结构)
(1)顺序栈——采用顺序结构存储
(2)链栈——采用链式结构存储
(3)队列(Queue)
队列简称为队,是一种特殊的线性表。队列是限定只能在表的一端插入运算,而在另一端进行删除操作。其特点为“先进先出”。在表中,允许进行插入操作的一端称为队尾,允许进行删除操作的一端称作队首(队头)。通常将元素插入队尾的操作称作入队列(或入队),称删除队首元素的操作为出队列(或出队)。队列中没有元素时,称为空队。(出入队如下图)
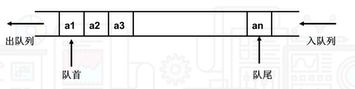
队列的存储结构:(两种结构)
(1)顺序结构——采用顺序结构存储
(2)链式结构——采用链式结构存储
(4)链表(Linked List)
链表是一种数据元素按照链式存储结构进行存储的数据结构,这种存储结构具有在物理上存在非连续的特点。也就是说链表不是地址连续的空间,它的插入和删除不需要移动元素,它看到内存有空余地址就可以毫无顾忌地挤进去,所以我们叫它“调皮的链表”。链表由一系列数据节点构成,每个数据节点包括数据域和指针域两部分。指针域保存了数据结构中下一个元素存放的地址。链表结构中数据元素的逻辑顺序是通过链表中的指针连接次序来实现的。链表分为双链表和单链表,单链表中构成表的节点只有一个指向直接后继结点的指针域。其结构特点:逻辑上相邻的数据元素在物理上不一定相邻。
(5)树(Tree)
树是典型的非线性结构,它是由n(n≥0)个节点组成的有限集合T。如果n=0,称为空树;如果n>0,则满足。有一个特定的称之为根(root)的节点,它只有直接后继,但没有直接前驱;除根以外的其它节点划分为m(m>0)个互不相交的有限集合T1,T2,…,Tm,每个集合又是一棵树,并且称之为根的子树(subTree)。每棵子树的根节点有且仅有一个直接前驱,但可以有0个或多个直接后继。
树的基本术语:
节点(node):包含一个数据元素及若干个指向其子树的分支
节点的度(degree):节点的子树的个数
树的度(degree):树中节点度的最大值
叶子(leaf):度为零的节点
分支(branch):度不为零的节点
孩子(child):某节点的各子树的根
双亲(parent):该节点的直接前驱节点
兄弟(sibling):具有相同双亲的节点
有序树和无序树:如果树中每个节点的各个子树是从左到右有次序
森林:m(m>=0)根互不相交的树的有限集合
树的深度:树中所有节点的最大层数,也称高度(height)
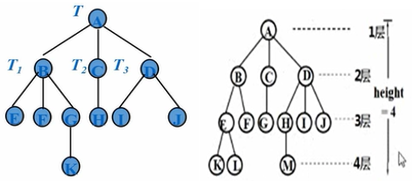
(6)图(Graph)
图结构是一种比树型结构更复杂的非线性数据结构,任意一个节点都可以有任意多个前驱和后继。在图结构中,数据节点一般称为顶点,而边是顶点的有序偶对。如果两个顶点之间存在一条边,那么就表示这两个顶点具有相邻关系。
图的基本术语:1.邻接点、相关边 2.顶点的度、入度和出度 3.完全图、稠密图、稀疏图 4.子图 5.路径 6.连通图、连通分量 7.强连通图、强连通分量 8.权、网 9.有向图、无向图
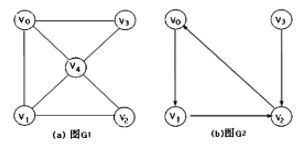
(7)堆(Heap)
堆是一种特殊的树型数据结构,一般讨论的堆是二叉堆。堆的特点是根节点的值是所有节点中最小或者最大的,并且根节点的两个子树也是一样的。
(8)散列表(Hash)
散列表(哈希表)源自于散列函数(Hash function),其思想是如果在结构中存在关键字和T相等的记录,那么必定在F(T)的存储位置可以找到该记录,这样就可以不用进行比较操作而直接取得所查记录。
二、数据结构常用算法
数据结构研究的内容:就是如何按一定的逻辑结构,把数据组织起来,并选择适当的存储表示方法把逻辑结构组织好的数据存储到计算机的存储器里。算法研究的目的是为了更有效的处理数据,提高数据运算效率。数据的运算是定义在数据的逻辑结构上,但运算的具体实现要在存储结构上进行。一般有以下几种常用运算:
(1)检索:检索就是在数据结构里查找满足一定条件的节点。一般是给定一个某字段的值,找具有该字段值的节点。
(2)插入:往数据结构中增加新的节点。
(3)删除:把指定的结点从数据结构中去掉。
(4)更新:改变指定节点的一个或多个字段的值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









