




 本文介绍了一种在查询数据时,如何通过特定字段筛选所需信息的方法。以认领人字段为例,展示了如何区分已认领和待认领状态的数据,实现精准查询。
本文介绍了一种在查询数据时,如何通过特定字段筛选所需信息的方法。以认领人字段为例,展示了如何区分已认领和待认领状态的数据,实现精准查询。
根据某个字段来查询筛选数据
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
开发工具与关键技术:Visual Studio
作者:李继金
撰写时间:2019年7月24日
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
在一些查询中往往需要我们筛选出某些特定的数据,那么我们在写查询语句的时候就要对数据进行筛选,查询出符合我们需要的数据,下面请看需要显示的数据:
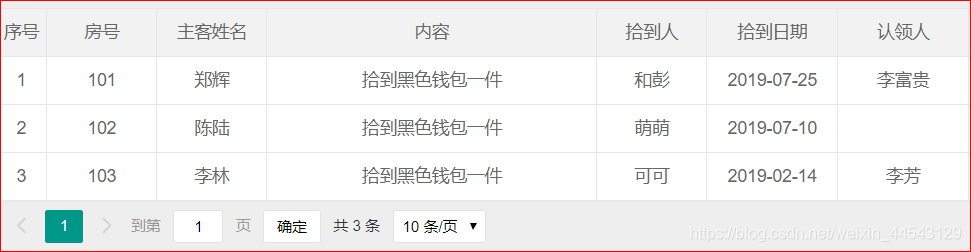
在页面的数据记录中可以看到数据应该分成两种记录分别是:认领人有数据的“已认领”和认领人没有数据的“待认领”,那么我们在查询加载数据的时候就需要通过“认领人”这个字段名来查询数据,下面开始进入查询“待认领”的代码:

查询的方法还是一样,首先联表把数据全部查询,最后在加上“Where”语句的条件筛选,这样我们就可以查询出来,接下来就是加载页面的总条数:
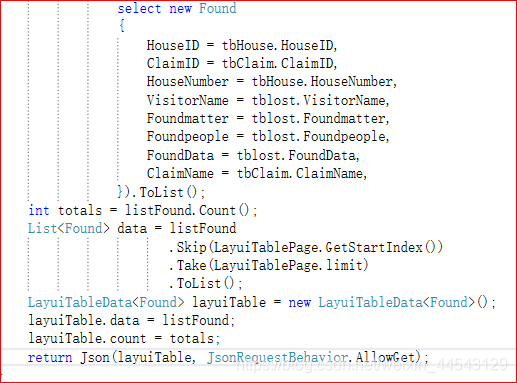
查询完毕就可以加载我们要筛选的数据效果:


















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









