







分词作为自然语言处理中的一项基本内容,是很多任务的基础,任何一门自然语言,分词难度参差不齐。比如中文分词与英文分词就存在很大的差别。在英文中,使用空格来进行分词,可以完成大部分的英文文本的分词任务;然而,对于中文而言,分词是一项极具挑战性的任务,没有特定的符号来标识某个词的开始或者结尾,而分词结果的好坏,对于语义理解的正确性有重要影响,比如下面这句话的分词结果:
南京市长江大桥==>南京市/长江大桥,或者==>南京市长/江大桥。不同的分词结果,语义天壤地别。那么如何能够合理的把词从句子中正确的切分出来呢?目前方法非常多,对于中文分词任务而言,可以粗分为基于规则的方法,这类方法通常需要编写词典;经典的浅层机器学习的方法;基于深度学习的分词技术。
首先,来看看对于词典在分词中的使用。对于词典,最简单也最常用的方法,就是构造一个常用词的候选集合,比如,词”我“、”爱“、”学习“这些词构成的集合,对于句子”我爱学习“,如果要进行句子分词,只需要从头到尾遍历这个句子,如果词在候选词集中出现过,则切分该词,这样很容易对原句进行切分,这样的方法逻辑简单,实现容易。所以在工程中,常采用list这种数据结构来进行候选词的存储。但是,如果对于大量的词来进行词典的建设,效率就非常低了,不仅涉及到词的存储,还要进行查找操作,无论是时间复杂度还是空间复杂度,都是线性的。如何更加高效的存储和查找呢?成为了提升算法性能的关键因素。从数据结构和算法的角度来分析,树型结构具有相比线性结构更加明显的优势,因此出现了Trie树这种方法,Trie树也成为了自然语言处理词库建设中常用的方法。
在计算机科学中,Trie树又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串类型。Trie树也经常被搜索引擎系统用于文本词频统计。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
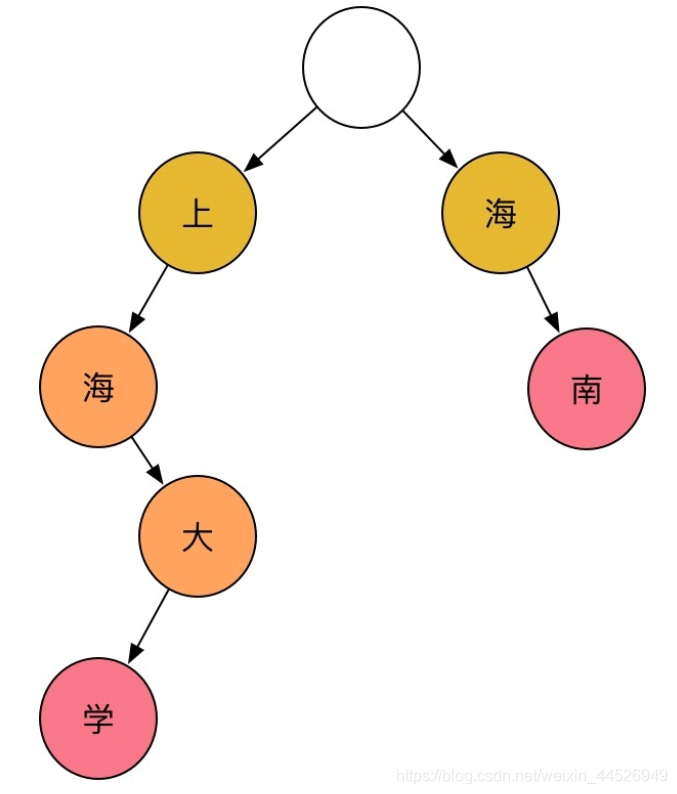
上图中包含三类节点:根节点、内部节点、叶子节点,利用Trie树存储后,根据一条路径,来存储一个词典中的词比如”上海大学“,当然中间节点也可以作为一个词的结尾来进行保存,比如”上海“,常用的中文汉字不到5000,大概只需要一个一层分支为2**12的Trie树来保存所有的中文词库信息。对于树形结构,保证了高效的存储和查找方法,遍历一个句子时,只需要依次向树下一层访问,如果无法访问到下一节点,则进行切分,如到叶子节点,也进行切分即可,这就是基于Trie树的最长匹配法,分词性能的好坏完全依赖于词库。目前的jieba分词软件就是基于这种思想来完成的。
虽然基于Trie树的分词方法能够满足大部分应用场景,但是该方法严重依赖于词典,而且有时效果也非常一般,对于大规模的语料库而言,词库建设的工作量又非常大。面对这种情况,采用机器学习的方法可以使得分词效果得到改善,比如基于隐马尔科夫模型的分词方法、基于条件随机场的分词方法等浅层机器学习方法来完成分词任务。
隐马尔科夫模型包括隐状态序列、观察值序列、状态转移矩阵、条件概率矩阵、初始化概率。给定一个分词任务:
隐状态序列:指的是句中词的几种状态,比如常见的方法,会将句中的词分为四种状态:词的开始位置标记状态,记为“S”(Start的简写);词的中间位置标记状态,记为“M”(Middle的简写);词的末尾标记状态,记为“E”(End的简写);单独成词的标记,简写为“W”(Whole的简写)。比如词“太极拳“,被标记为“SME”,”爱“被标记为”W“,”喜欢“被标记为”SE“。比如句子”我爱打太极拳“,相应的观察标记为”我/爱/打 /太极拳“,其隐状态序列被标记为”W/W/W/SME“。
观察值序列:指的是带切分的词,如:我爱打太极拳。
状态转移矩阵:是隐马尔可夫模型中非常重要的一个概念。隐马尔可夫模型一个很重要的假设,称为马尔可夫假设,当前时刻的状态只与前一个时刻的状态有关,这个关系可以使用状态转移矩阵来进行数学上的刻画,对于”我/爱/打/太极拳“这句话来说,需要用到4阶方阵。
条件概率矩阵:在HMM中,观察值只取决于当前状态值(假设条件),条件概率矩阵主要建模在SMEW下各个词的不同概率,和初始化概率、状态转移矩阵一样,我们需要在语料中计算得到对应的数据。
初始化概率:指的是S、M、E、W这四种状态在第一个字或者词的概率分布情况。
为了方便理解,举个例子,比如”我爱打太极拳“,我们初始化一个矩阵,大小为W[4][6],则矩阵的第一列值为初始化条件概率分布,依次为:P(S)P(我|S),P(M)P(我|M),P(E)P(我|E),P(W)P(我|W)。然后根据转移概率计算下一个字的状态概率分布,依次到最后即可,即可计算句子中所有词的状态分布,然后确定好边界对比条件,即可计算出对应的状态序列。HMM是中文分词中一种很常见的分词方法,根据上述的描述和解释,我们知道,其分词状态主要依赖于语料的标注,通过语料初始化概率、状态转移矩阵、条件概率矩阵的计算,对需要分词的句子进行计算,简单来说,是通过模型学习到对应词的历史状态经验,然后在新的矩阵中使用。HMM的优势在于,模型计算简单,且通常非常有效,对于词典中未出现的词有比较好的效果。而另外一种机器学习模型——CRF,即条件随机场,也是一种高效的分词模型,与HMM类似,将分词任务作为一项序列标注任务,将上面提到的四种状态(SMEW)标注到句子中的不同词上,相对于HMM,CRF能够利用更多的特征,而且,从本质上来讲,HMM属于生成模型,描述的是已知量和未知量的联合概率分布,而CRF则是直接进行条件概率建模。而且CRF特征更加丰富,可通过自定义特征函数来增加特征信息,通常CRF能建模的信息应该包括HMM的状态转移、数据初始化的特征。CRF在理论和实践上通常都优于HMM,CRF主要包括两部分特征:1、简单特征,只涉及当前状态的特征;2、转移特征,涉及到两种状态之间的特征。特征模板在工程实践中是经常使用的一项技术。
除了浅层机器学习方法之外,火热的深度学习方法也经常用于传统的这些标注任务,比如用于自然语言处理的深度学习模型LSTM和传统机器学习方法CRF的结合,让模型标注的结果取得了质的飞跃,其基本结构如下图所示:
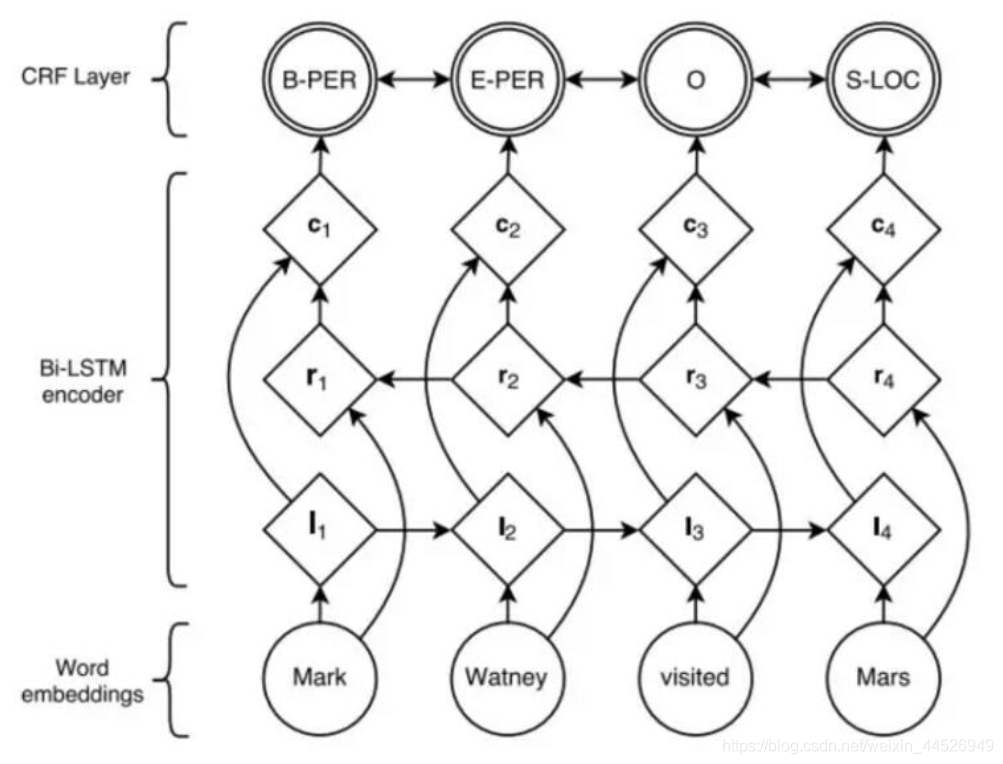
其基本做法是:首先,训练词向量,使用word2vec技术对语料库中的字词训练固定维度的词向量,然后引入一个双向LSTM(Bi-LSTM),用来建模句子本身的语义信息,最后引入一个CRF完成序列标注工作。这种考虑了上下文的方法是优于传统方法的一个重要原因。
近年来,深度学习方法,已经成为了自然语言处理任务的首选方法,并且大多数情况,效果都会比浅层机器学习方法要好,特别是最近预训练模型的涌现,推动了自然语言处理领域的快速发展,很多模型都被新模型所取代,但是,传统方法仍然是非常重要的,是很多模型的基础,正如”没有免费的午餐“定理所说,脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义,因为若考虑所有潜在的问题,则所有学习算法都一样好。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











