







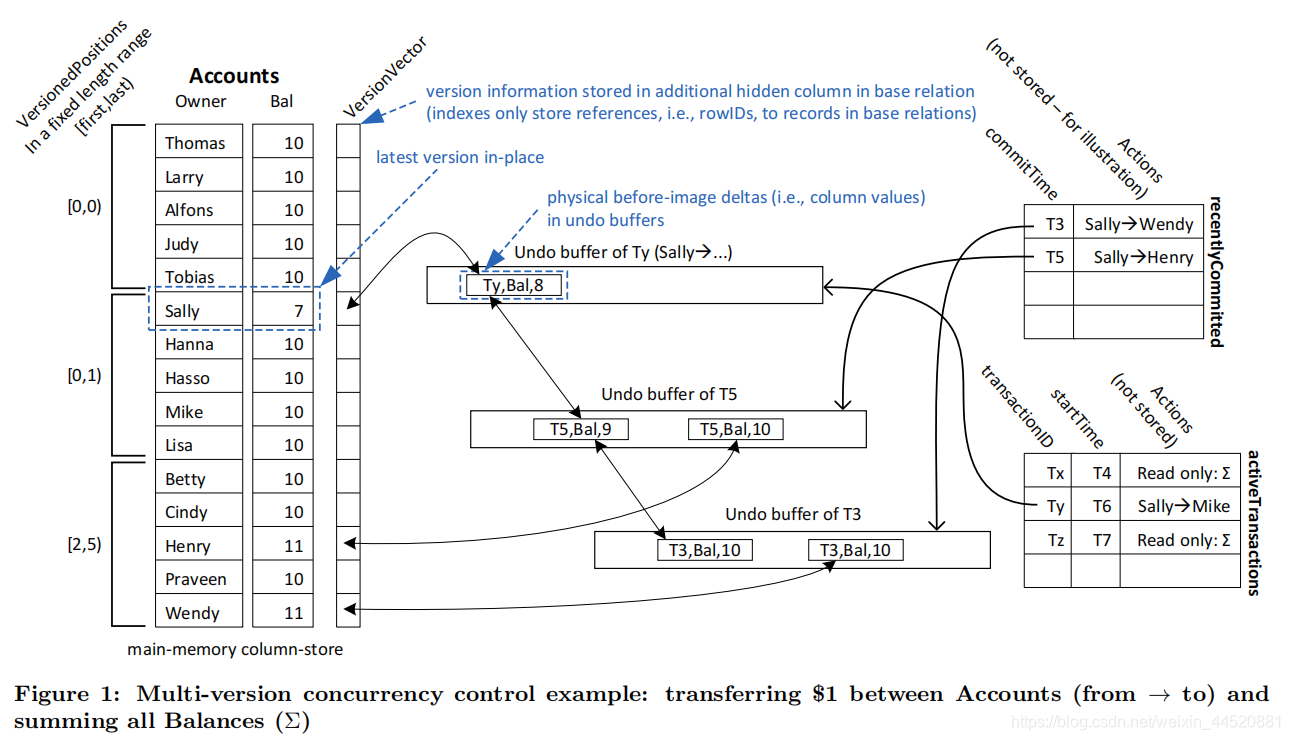
这篇论文是说一个内存数据库上实现的SI(快照隔离级别)和SSI(可串行化快照隔离级别)的MVCC。版本链是像Figure 1中的undo buffer的形式存储。Figure 1中,左边Accounts表示数据库中唯一存在的一个表,只有两个attributes,为owner和balance。图里表示的讨论的操作是存在A->B转账和查询总所有owner的总余额两种操作。另外,Figure1中的 VersionedPositions 在论文的Efficient Scanning章节里有介绍,可以后面再管它。
- 一个事务有自己的事务ID和start timestamp,提交的时候会获得一个新的timestamp,为了将事务ID和start-timestap区分开,事务id的取值范围是2^63 ->…, timestamp的取值范围是[0,2^63),新创建的版本标记成事务ID, 提交时候申请一个commit-timestamp这个和start-time一起递增的。
- 读数据时候按照从row的VersionVector的第一个指针开始访问undobuffer,直到满足下列条件,其中,prev是指向下一个undo的指针,T是当前事务的ID,三个并列条件中,(1)表示是第一个数据,没有更老的版本了(有点疑惑如果是新事务刚写的不也访问到了?)(2)这个版本是自己创建的(3)这个版本在当前事务之前(如果别的事务没提交,则用的是别的事务的Id,这个ID是大于timestamp的(2^63…)
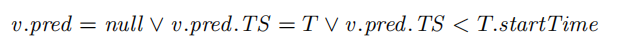
到此位置依然不能保证可串行化操作,这篇论文添加了一个Serializability Validation phase
- 在某些数据库版本中,比如Hekaton,posgressql为了保证串行化,会track所有read set,在事务提交时候检验re-checked读集,开销非常大。
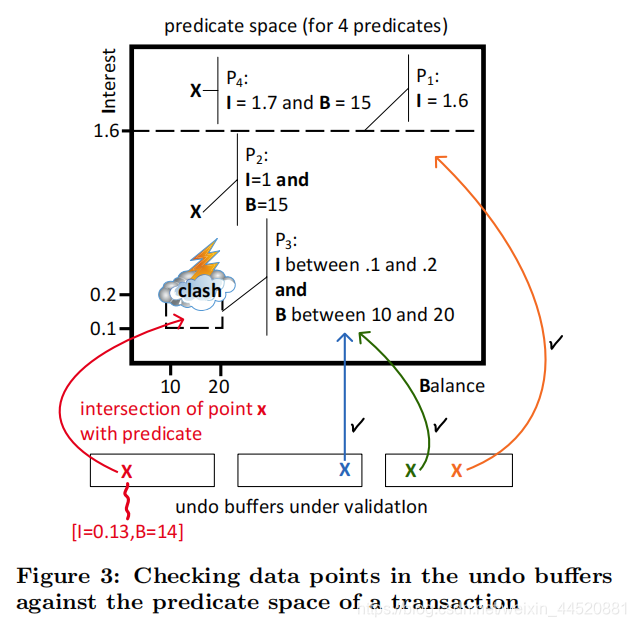
这篇论文采用了"precise locking",(谓词锁?),如图3,思想很简单,事务T使用P1,P2,P3,P4谓词分别进行过读取,那么提交的时候会检查目前undo buffef是否与T的P1,P2,P3,P4相交就OK了,比如图中红色部分对应的undo buffer,显然I=0.13和B=14和P3撞上了,那么冲突abort->restat。其他细节比如要存储最近刚提交的事务,就掠过论文细节,再完成validate之后写redolog,完事。看到这里感觉这篇论文真的挺牛批,直接实现了串行化(幻读也就不存在了)
Garbage Collection 和 Handling of Index Structures作者说的挺简略的,辣鸡回收的时候检查active 事务然后标记删除那一套,说了先不删除,防止目前被其他指针引用。处理索引时候如果是修改,就先删除后插入,如果插入的时候已经有了其他元素,则abort,索引里也有垃圾需要定期清理,细节就不深究了。
Efficient Scanning
利用了Figure 1中的versionPositions加速,这里我没怎么看懂啊啊啊啊啊
后面还有形式化证明串行化和实验,略过,作者牛逼!
RELATED WORK
这一章里的Serializability提一下,很多实现SI(快照隔离)级别的都实际上不支持(SSI)的,后来posgress解决了(看论文),但是性能也不比加锁好到哪里去(这里的加锁是指锁整个表?),我挺好奇mysql究竟是怎么实现SSI的。(面试官应该很喜欢吧。。。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









