









任务描述
在之前的lab中我们已经实现了kv存储系统,但是所有的put/get请求都打在leader上,leader的负载很大,因此在Lab4在此基础上进行改进,根据实验任务描述,通过一个master进行集群的配置,一个集群负责一部分碎片任务即shards,可以通过客户端管理master的配置信息,同时master的配置即表示了各个集群该完成什么样的任务,这样,比如对于kv存储系统固定的键的put和get操作都由不同的集群控制,同时客户端在拿到master中关于访问根据数据的hash,数据应该找哪个集群的配置信息后,应该缓存这些记录,这样就降低了master的压力,同时增加机器也可以线性的增加整个系统的性能。架构图如下。
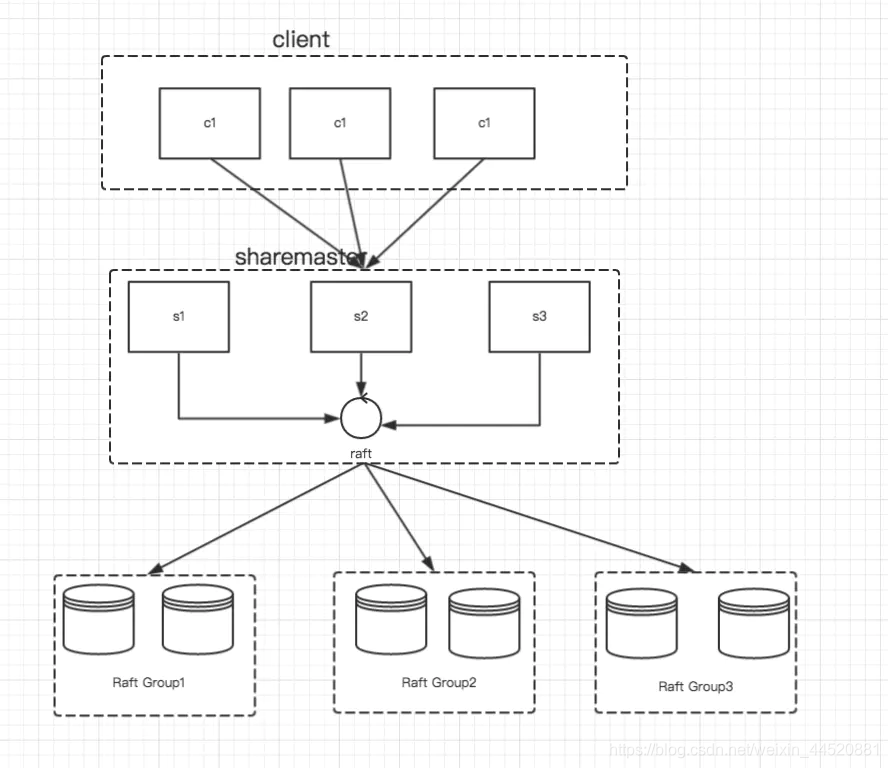
任务A非常容易,需要我们完成master的客户端和服务端的编写主要是完成Join()、Leave()、Move()、Query()四个rpc调用,同时注意要在负载均衡操作时尽可能的少改变shards,见下述原文,这个地方貌似go不像C++stl和java集合那样有方便的数据结构拿来即用,我是暴力遍历解决的,好在数据范围小,时间复杂度没啥影响。
“The new configuration should divide the shards as evenly as possible among the groups, and should move as few shards as possible to achieve that goal.”
起初我对任务A的理解有点迷惑。我是通过看了几遍文档和test_test.go以及给的代码框架中的结构体看明白的。如下。
// A configuration -- an assignment of shards to groups.
// Please don't change this.
type Config struct {
Num int // config number
Shards [NShards]int // shard -> gid
Groups map[int][]string // gid -> servers[]
}
type ShardMaster struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
// Your data here.
reqMap map[int]*OpContext //log index -> 请求上下文
seqMap map[int64]int64 //查看每个client的日志提交到哪个位置了。上下文
lastAppliedIndex int // 已应用的日志index
configs []Config // indexed by config num
}

遇到的问题
- 在func StartServer()中必须加入如下代码,不然会报错。如果你在rpc中传的是指针,则需要注册时加&,但是我在测试时发现会有莫名奇怪的数据竞争,因此连着lab3B的代码一起改了,RPC中的内容只传结构体变量,不传指针。
labgob.Register(Op{})
labgob.Register(JoinArgs{})
labgob.Register(LeaveArgs{})
labgob.Register(MoveArgs{})
labgob.Register(QueryArgs{})
后来在做lab4B时发现Hint里提到了这个问题。

- 因为每次修改配置都要记录拓展mv.configs数组,因此需要拓展原有数组的同时,复制原本已有的服务器和碎片分布,再次基础上修改,注意的是等于号复制map时浅拷贝,因此需要我们单独复制复制,而[]int数组不用担心浅拷贝的问题。
实现
客户端
把之前的代码拿来随便改改就行。
package shardmaster
//
// Shardmaster clerk.
//
import "../labrpc"
import "time"
import "crypto/rand"
import "math/big"
type Clerk struct {
servers []*labrpc.ClientEnd
// Your data here.
clientId int64
seqId int64
leaderId int
}
func nrand() int64 {
max := big.NewInt(int64(1) << 62)
bigx, _ := rand.Int(rand.Reader, max)
x := bigx.Int64()
return x
}
func MakeClerk(servers []*labrpc.ClientEnd) *Clerk {
ck := new(Clerk)
ck.servers = servers
// Your code here.
ck.leaderId = 0
ck.seqId = 0
ck.clientId = nrand()
return ck
}
// fetch Config # num, or latest config if num==-1.
func (ck *Clerk) Query(num int) Config {
args := &QueryArgs{}
// Your code here.
args.Num = num
args.ClientId = ck.clientId
args.SeqId = ck.seqId
ck.seqId++
//DPrintf("Client[%d] start Query(num), num = %v", ck.clientId, num)
for {
// try each known server.
var reply QueryReply
ok := ck.servers[ck.leaderId].Call("ShardMaster.Query", args, &reply)
if ok && reply.WrongLeader == false {
DPrintf("Client[%d] finish Query(%v) = %v", ck.clientId, num, reply.Config)
return reply.Config
}
ck.leaderId = (ck.leaderId + 1) % len(ck.servers)
time.Sleep(100 * time.Millisecond)
}
}
// add a set of groups (gid -> server-list mapping).
func (ck *Clerk) Join(servers map[int][]string) {
args := &JoinArgs{}
// Your code here.
args.Servers = servers
args.ClientId = ck.clientId
args.SeqId = ck.seqId
ck.seqId++
DPrintf("Client[%d] start Join(servers), servers = %v", ck.clientId, servers)
for {
// try each known server.
for _, srv := range ck.servers {
var reply JoinReply
ok := srv.Call("ShardMaster.Join", args, &reply)
if ok && reply.WrongLeader == false {
return
}
}
time.Sleep(100 * time.Millisecond)
}
}
func (ck *Clerk) Leave(gids []int) {
args := &LeaveArgs{}
// Your code here.
args.GIDs = gids
args.ClientId = ck.clientId
args.SeqId = ck.seqId
ck.seqId++
DPrintf("Client[%d] start Leave(gids), gids = %v", ck.clientId, gids)
for {
// try each known server.
for _, srv := range ck.servers {
var reply LeaveReply
ok := srv.Call("ShardMaster.Leave", args, &reply)
if ok && reply.WrongLeader == false {
return
}
}
time.Sleep(100 * time.Millisecond)
}
}
// Move(shard, gid) -- hand off one shard from current owner to gid.
func (ck *Clerk) Move(shard int, gid int) {
args := &MoveArgs{}
// Your code here.
args.Shard = shard
args.GID = gid
args.ClientId = ck.clientId
args.SeqId = ck.seqId
ck.seqId++
DPrintf("Client[%d] start Leave(shard, gid), shard = %v, gid = %v", ck.clientId, shard, gid)
for {
// try each known server.
for _, srv := range ck.servers {
var reply MoveReply
ok := srv.Call("ShardMaster.Move", args, &reply)
if ok && reply.WrongLeader == false {
return
}
}
time.Sleep(100 * time.Millisecond)
}
}
服务端
结构体的声明类似lab3B,直接拿来用,根据应用层的需要稍作修改,如下
const (
OP_TYPE_JOIN = "Join"
OP_TYPE_LEAVE = "Leave"
OP_TYPE_MOVE = "Move"
OP_TYPE_QUERY = "Query"
)
const Debug = 0
func DPrintf(format string, a ...interface{}) (n int, err error) {
if Debug > 0 {
log.Printf(format, a...)
}
return
}
type ShardMaster struct {
mu sync.Mutex
me int
rf *raft.Raft
applyCh chan raft.ApplyMsg
// Your data here.
reqMap map[int]*OpContext //log index -> 请求上下文
seqMap map[int64]int64 //查看每个client的日志提交到哪个位置了。上下文
lastAppliedIndex int // 已应用的日志index
configs []Config // indexed by config num
}
type Op struct {
// Your data here.
Index int //call start() return Index, Term
Term int
Args interface{} //Join/Leave/Move/QueryArgs
Type string //Join/Leave/Move/Query
ClientId int64
SeqId int64
}
// 等待Raft提交期间的Op上下文, 用于唤醒阻塞的RPC
type OpContext struct {
op *Op
committed chan struct{}
wrongLeader bool // 因为index位置log的term不一致, 说明leader换过了
// ignored bool // 因为req id过期, 导致该日志被跳过执行
Get操作的结果
//keyExist bool
config Config
}
对于 Join()、Leave()、Move()、Query()四个rpc调用进行简单封装,降低代码复杂度。
func (sm *ShardMaster) Join(args *JoinArgs, reply *JoinReply) {
// Your code here.
op := &Op{}
op.Args = *args
op.Type = OP_TYPE_JOIN
op.SeqId = args.SeqId
op.ClientId = args.ClientId
reply.WrongLeader, _ = sm.templateHandler(op)
}
func (sm *ShardMaster) Leave(args *LeaveArgs, reply *LeaveReply) {
// Your code here.
op := &Op{}
op.Args = *args
op.Type = OP_TYPE_LEAVE
op.SeqId = args.SeqId
op.ClientId = args.ClientId
reply.WrongLeader, _ = sm.templateHandler(op)
}
func (sm *ShardMaster) Move(args *MoveArgs, reply *MoveReply) {
// Your code here.
op := &Op{}
op.Args = *args
op.Type = OP_TYPE_MOVE
op.SeqId = args.SeqId
op.ClientId = args.ClientId
reply.WrongLeader, _ = sm.templateHandler(op)
}
func (sm *ShardMaster) Query(args *QueryArgs, reply *QueryReply) {
// Your code here.
op := &Op{}
op.Args = *args
op.Type = OP_TYPE_QUERY
op.SeqId = args.SeqId
op.ClientId = args.ClientId
reply.WrongLeader, reply.Config = sm.templateHandler(op)
}
//对Join/Leave/Move/Query四个RPC进行封装
func (sm *ShardMaster) templateHandler(op *Op) (bool, Config) {
wrongLeader := true
config := Config{}
var isLeader bool
op.Index, op.Term, isLeader = sm.rf.Start(*op)
if (!isLeader) {
return true, config
}
opCtx := &OpContext{
op: op,
committed: make(chan struct{})}
sm.mu.Lock()
sm.reqMap[op.Index] = opCtx
sm.mu.Unlock()
select {
case <-opCtx.committed:
if (opCtx.wrongLeader == true) { // 同样index位置的term不一样了, 说明leader变了,需要client向新leader重新写入
wrongLeader = true
} else {
wrongLeader = false
if opCtx.op.Type == OP_TYPE_QUERY {
config = opCtx.config
//DPrintf("ShardMaster[%d] templateHandler() query finish, opCtx.config = %v", sm.me, config)
}
}
case <-time.After(2 * time.Second):
wrongLeader = true
DPrintf("[KVserver] timeout 2s")
}
func() {
//超时或处理完毕则清理上下文
sm.mu.Lock()
defer sm.mu.Unlock()
if one, ok := sm.reqMap[op.Index]; ok {
if (one == opCtx) {
delete(sm.reqMap, op.Index)
}
}
}()
return wrongLeader, config
}
下面便类似lab3,用一个协程循环监听applyCh管道,处理逻辑。
func (sm *ShardMaster) applyLoop() {
for {
select {
case msg := <-sm.applyCh:
// 如果是安装快照
if !msg.CommandValid {
//本lab目前不需要快照
// func() {
// sm.mu.Lock()
// defer sm.mu.Unlock()
// if len(msg.Snapshot) == 0 { // 空快照,清空数据
// sm.configs = make([]Config, 1)
// sm.configs[0].Groups = map[int][]string{}
// sm.seqMap = make(map[int64]int64)
// } else {
// // 反序列化快照, 安装到内存
// r := bytes.NewBuffer(msg.Snapshot)
// d := labgob.NewDecoder(r)
// d.Decode(&sm.configs)
// d.Decode(&sm.seqMap)
// }
// // 已应用到哪个索引
// sm.lastAppliedIndex = msg.LastIncludedIndex
// //DPrintf("KVServer[%d] installSnapshot, kvStore[%v], seqMap[%v] lastAppliedIndex[%v]", kv.me, len(kv.kvStore), len(kv.seqMap), kv.lastAppliedIndex)
// }()
} else { // 如果是普通log
cmd := msg.Command
index := msg.CommandIndex
term := msg.CommandTerm
func() {
sm.mu.Lock()
defer sm.mu.Unlock()
// 更新已经应用到的日志
sm.lastAppliedIndex = index
// 操作日志
op := cmd.(Op)
opCtx, existOp := sm.reqMap[index]
prevSeq, existSeq := sm.seqMap[op.ClientId]
sm.seqMap[op.ClientId] = op.SeqId
if existOp { // 存在等待结果的RPC, 那么判断状态是否与写入时一致
if opCtx.op.Term != term {
opCtx.wrongLeader = true
}
}
// 只处理ID单调递增的客户端写请求
if op.Type == OP_TYPE_JOIN || op.Type == OP_TYPE_LEAVE || op.Type == OP_TYPE_MOVE {
if !existSeq || op.SeqId > prevSeq { // 如果是递增的请求ID,那么接受它的变更
sm.doJoinLeaveMove(&op)
}
} else { // OP_TYPE_Query
if existOp {
//do some thing
queryNum := op.Args.(QueryArgs).Num
if (queryNum >= len(sm.configs) || queryNum == -1) {
opCtx.config = sm.configs[len(sm.configs) - 1]
} else {
opCtx.config = sm.configs[queryNum]
}
//DPrintf("ShardMaster[%d] applyloop query finish, opCtx.config = %v", sm.me, opCtx.config)
}
}
//DPrintf("KVServer[%d] applyLoop, kvStore[%v]", kv.me, len(kv.kvStore))
// 唤醒挂起的RPC
if existOp {
close(opCtx.committed)
}
}()
}
}
}
}
将会产生配置更新的三个操作Join()、Leave()、Move()单独拿出来写一个函数进行封装如下。
func (sm *ShardMaster) doJoinLeaveMove(op *Op) {
sm.configs = append(sm.configs, sm.configs[len(sm.configs) - 1])
//生成最新的config
config := &sm.configs[len(sm.configs) - 1]
//Groups map[int][]string是浅拷贝,需要特别小心
newGroups := make(map[int][]string)
for k,v := range(config.Groups) {
newGroups[k] = v
}
config.Groups = newGroups
config.Num++
switch op.Type{
case OP_TYPE_JOIN:
args := op.Args.(JoinArgs)
for gid, serversList := range(args.Servers) {
config.Groups[gid] = serversList
}
sm.loadBalance(config)
//DPrintf("ShardMaster[%d] Join finish, config = %v", sm.me, sm.configs)
case OP_TYPE_LEAVE:
args := op.Args.(LeaveArgs)
for _, gid := range(args.GIDs) {
delete(config.Groups, gid) //删除gid
for i := 0; i < NShards; i++ { //将分配的Shards置为0
if (config.Shards[i] == gid) {
config.Shards[i] = 0
}
}
}
sm.loadBalance(config)
case OP_TYPE_MOVE:
args := op.Args.(MoveArgs)
config.Shards[args.Shard] = args.GID
//不需要负载均衡,否则可能导致Move失效
}
}
//负载均衡
func (sm *ShardMaster) loadBalance(config *Config) {
//1.遍历Shards,将0(未分配的)分配给负载最小的
//2.判断负载最大的和最小的差值如果大于1,则从负载大的里拿一个shard到负载小的里
//如果用key:gid, value:loadsize的平衡树能加快速度,这里我直接暴力遍历
Groups_LoadSize := make(map[int]int)
for gid,_ := range(config.Groups) { //记录gid
Groups_LoadSize[gid] = 0
}
if len(config.Groups) == 0 { //无group直接退出
return
}
for _, gid := range(config.Shards) { //记录负载量
if (gid != 0) {
Groups_LoadSize[gid]++
}
}
for i := 0; i < NShards; i++ { //将未分配的shard分配出去
if (config.Shards[i] == 0) {
minGid,_,_,_ := getMinMax(&Groups_LoadSize)
config.Shards[i] = minGid
Groups_LoadSize[minGid]++
}
}
minGid, minLoadSize, maxGid, maxLoadSize := getMinMax(&Groups_LoadSize)
for maxLoadSize - minLoadSize > 1 {
//DPrintf("debug minGid=%v, minLoadSize=%v, maxGid=%v, maxLoadSize=%v", minGid, minLoadSize, maxGid, maxLoadSize)
for i := 0; i < NShards; i++ { //负载转移
if (config.Shards[i] == maxGid) {
config.Shards[i] = minGid
break
}
}
Groups_LoadSize[minGid]++
Groups_LoadSize[maxGid]--
minGid, minLoadSize, maxGid, maxLoadSize = getMinMax(&Groups_LoadSize)
}
}
func getMinMax(Groups_LoadSize *map[int]int) (int, int, int, int) {
minGid := -1
minLoadSize := -1
maxGid := -1
maxLoadSize := -1
for gid, loadSize := range(*Groups_LoadSize) {
if (minGid == -1) {
minGid = gid
maxGid = gid
minLoadSize = loadSize
maxLoadSize = loadSize
} else {
if (loadSize < minLoadSize) {
minGid = gid
minLoadSize = loadSize
} else if (loadSize > maxLoadSize) {
maxGid = gid
maxLoadSize = loadSize
}
}
}
return minGid, minLoadSize, maxGid, maxLoadSize
}
最后是StartServer函数。
func StartServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister) *ShardMaster {
DPrintf("shardmaster[%d]StartServer", me)
sm := new(ShardMaster)
sm.me = me
sm.configs = make([]Config, 1)
sm.configs[0].Groups = map[int][]string{}
labgob.Register(Op{})
labgob.Register(JoinArgs{})
labgob.Register(LeaveArgs{})
labgob.Register(MoveArgs{})
labgob.Register(QueryArgs{})
sm.applyCh = make(chan raft.ApplyMsg, 1)
sm.rf = raft.Make(servers, me, persister, sm.applyCh)
// Your code here.
sm.reqMap = make(map[int]*OpContext)
sm.seqMap = make(map[int64]int64)
sm.lastAppliedIndex = 0
go sm.applyLoop()
//go sm.snapshotLoop() 本lab似乎不需要拍快照
return sm
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









