







 本文详细介绍如何使用Java开发环境,基于Luncene构建Solr全文搜索服务器,包括下载、安装、配置步骤,以及如何整合中文分词器ikanalyzer实现中文搜索功能。
本文详细介绍如何使用Java开发环境,基于Luncene构建Solr全文搜索服务器,包括下载、安装、配置步骤,以及如何整合中文分词器ikanalyzer实现中文搜索功能。
简介:
采用Java开发,基于Luncene的全文搜索服务器,同时对其进行了扩展(扩展了面向抽象编程的地方,比如分词器,查询),提供了比Lucene更为丰富的查询语言(比如,过滤器),同时实现了可配置(跟hadoop整合,之前索引结构写在代码中,现在提前定义好)、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。(这些不重要 ,他就是干搜索的!!!)
安装步骤
下载 solr的解压包 和一个tomcat的容器 环境依赖JDK1.8
下载官网http://www.apache.org/dyn/closer.lua/lucene/solr
网址2下载:http://archive.apache.org/dist/lucene/solr/
这里是我以前下载好的解压包进行解
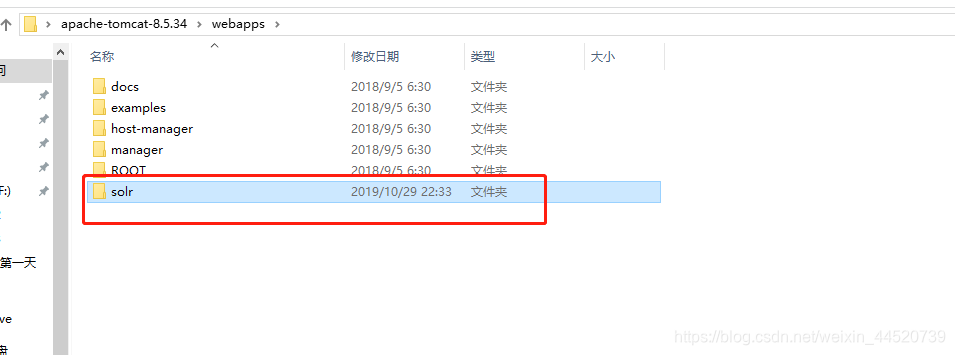
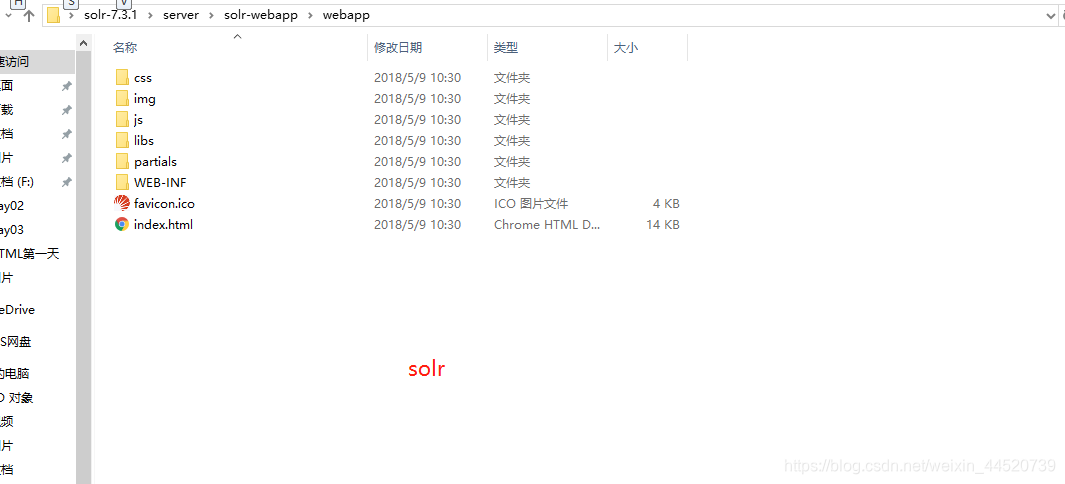
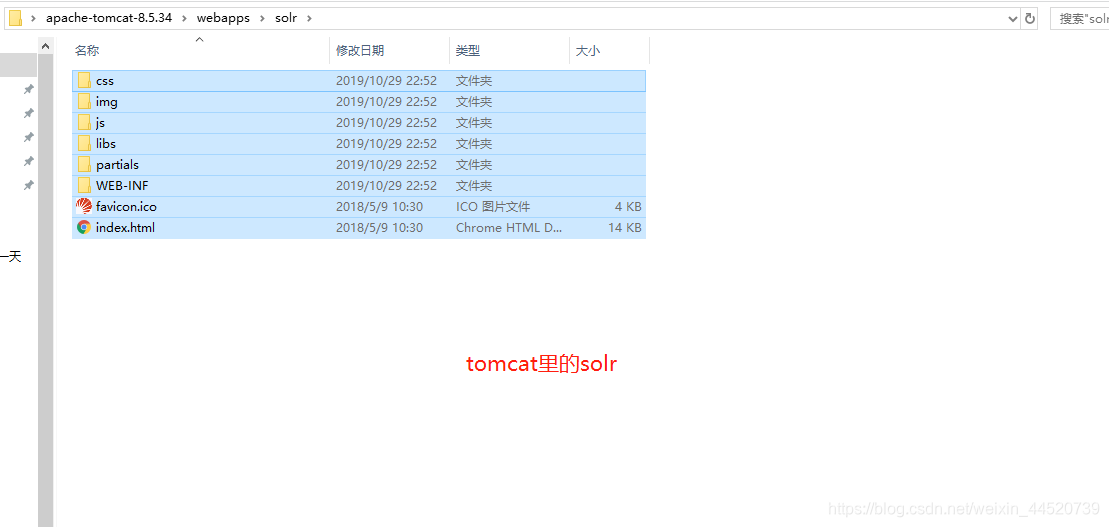
- 把解压好的tomcat 里的webapps下创建solr文件夹
- 把刚才解压的solr里的solr-7.3.1\server\solr-webapp\webapp下的文件复制到tomcat里的solr里
- 打开solr的dist的目录找到
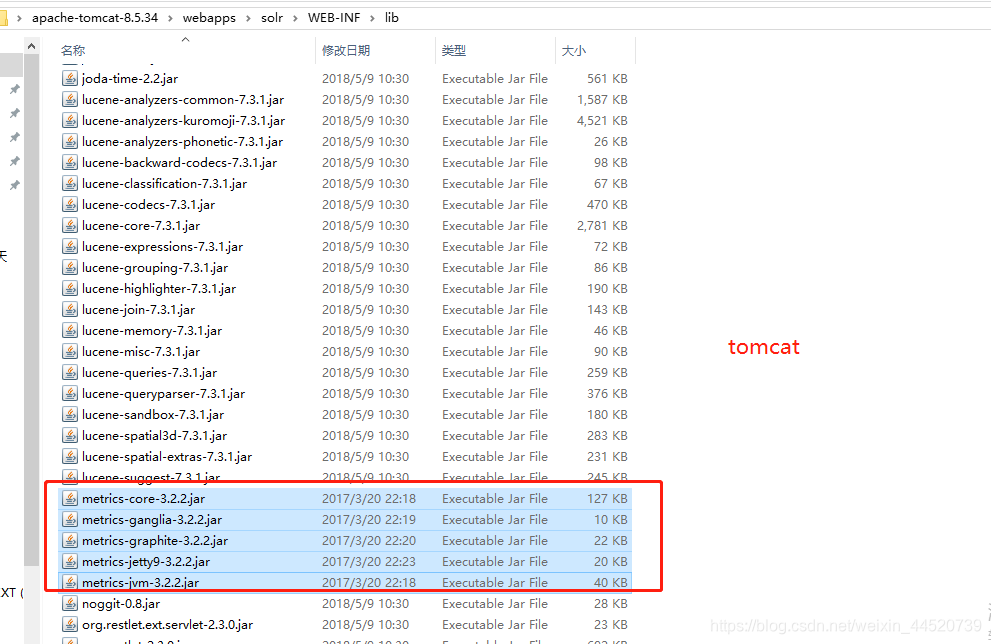
solr-dataimporthandler-7.3.1.jar和solr-dataimporthandler-extras-7.3.1.jar复制到tomcat里的solr的\WEB-INF\lib下 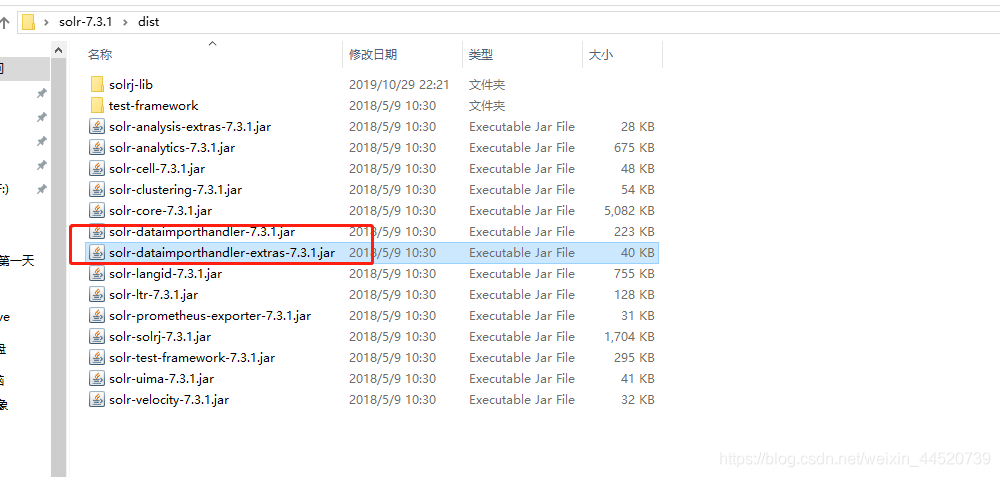
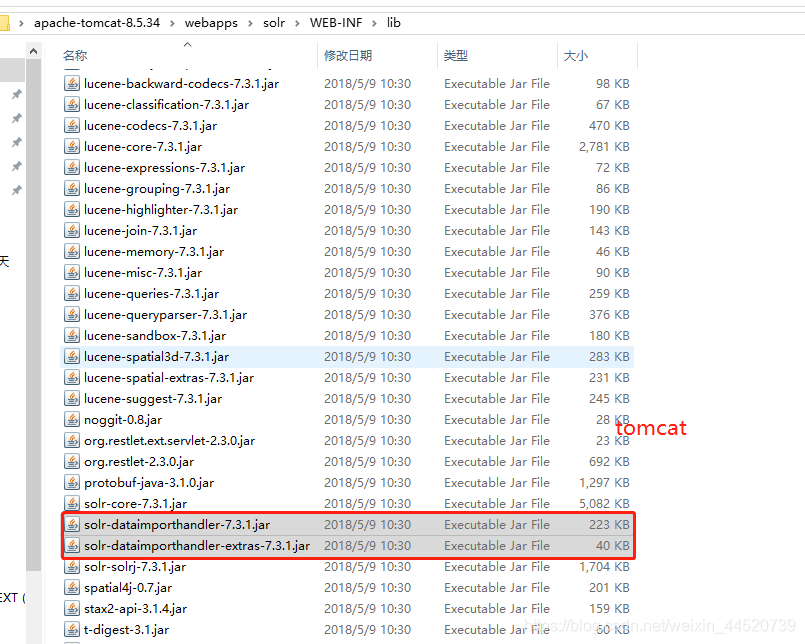
- 打开solr的server\lib复制
gmetric4j-1.0.7.jar和metrics-core-3.2.2.jar和metrics-ganglia-3.2.2.jar和metrics-graphite-3.2.2.jar和metrics-jetty9-3.2.2.jar和metrics-jvm-3.2.2.jar复制到tomcat里的solr的\WEB-INF\lib下
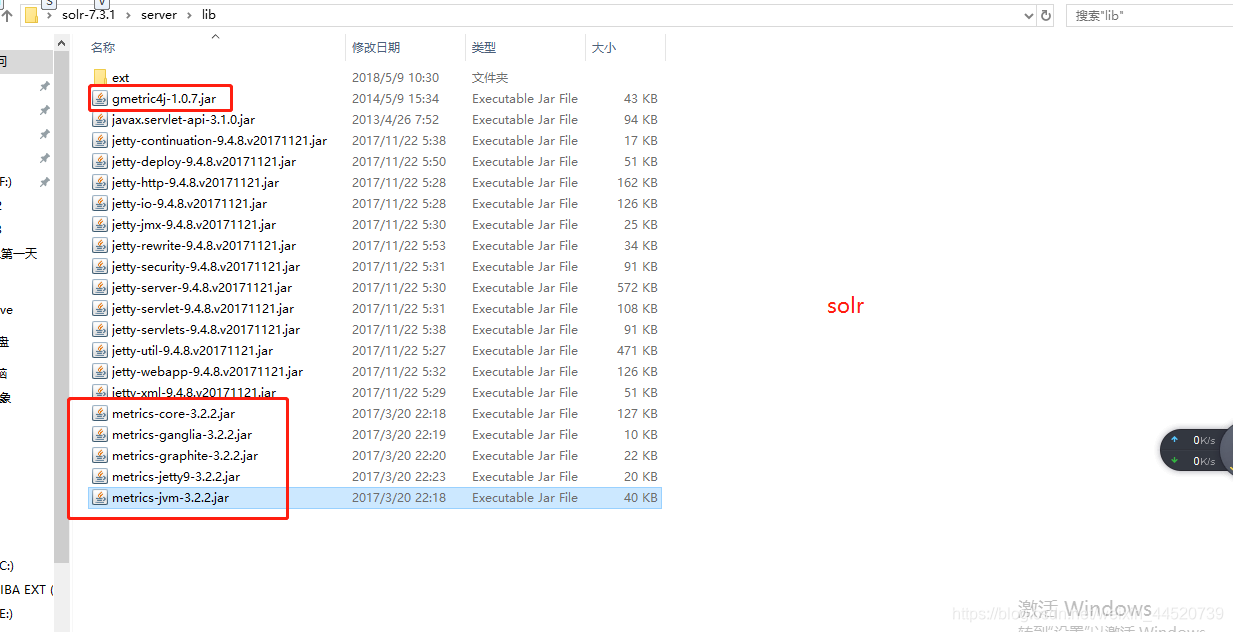
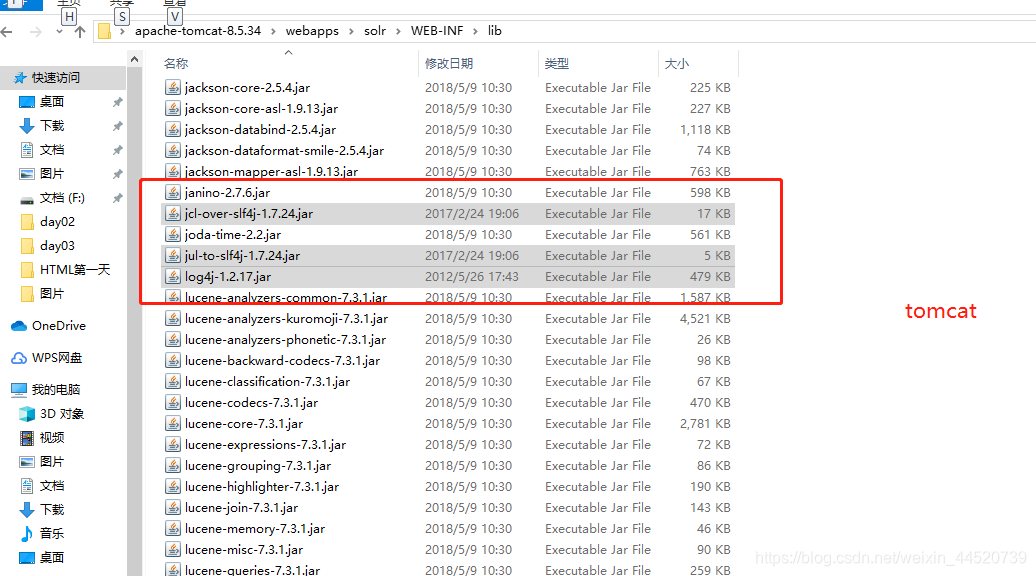
- 打开solr的server\lib\ext下的所有的jar包复制到tomcat里的solr的\WEB-INF\lib下

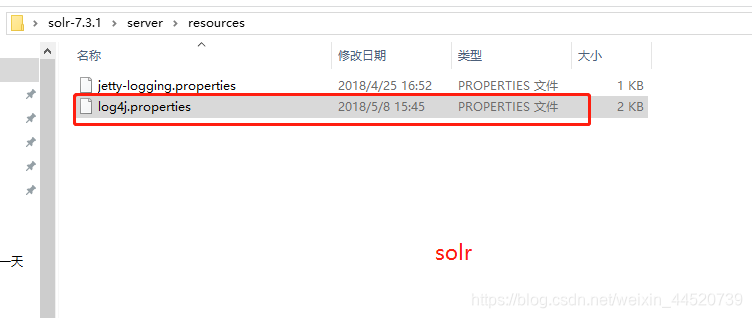
- 在tomcat下的solr的\WEB-INF下创建classes 把solrsolr-7.3.1\server\resources目录下的log4j.properties放在WEB-INF下创建classes里
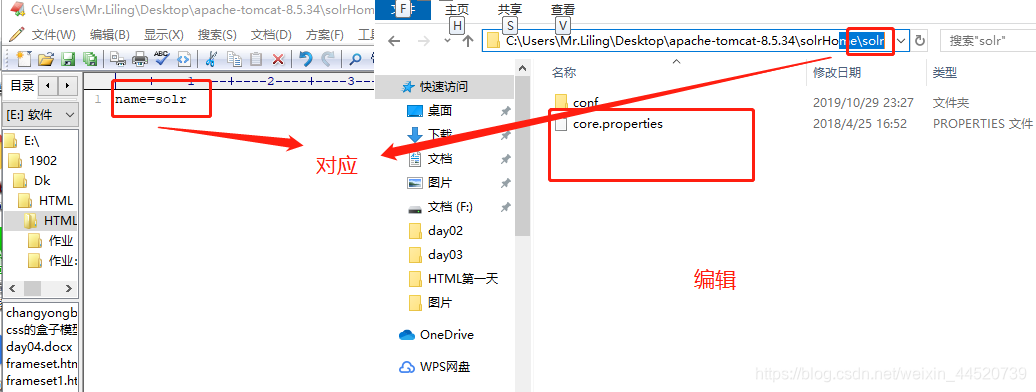
- 在tomcat创建solrHome 在将solr下的solr-7.3.1\server\solr里复制
zoo.cfg和solr.xml到创建的solrHome里
- 将solr下的solr-7.3.1\example\example-DIH\solr的solr文件夹复制到tomcat里的solrHome里
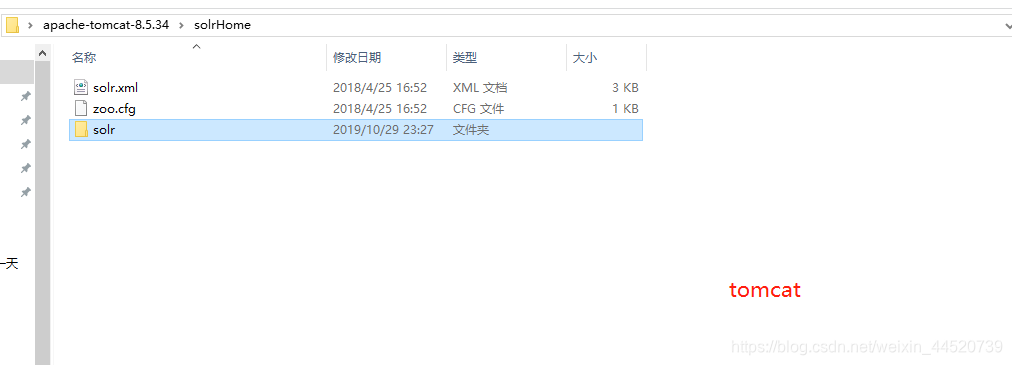
- 把刚才复制到solrHome的solr的core.properties进行编辑
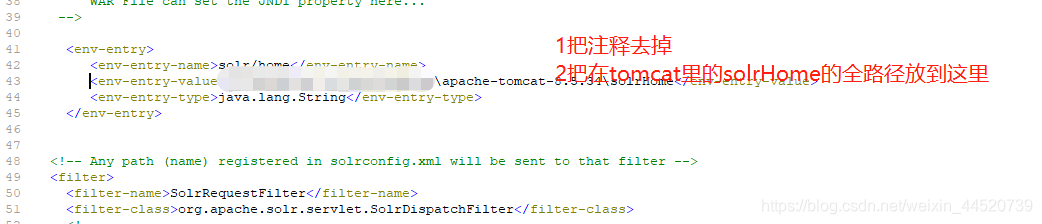
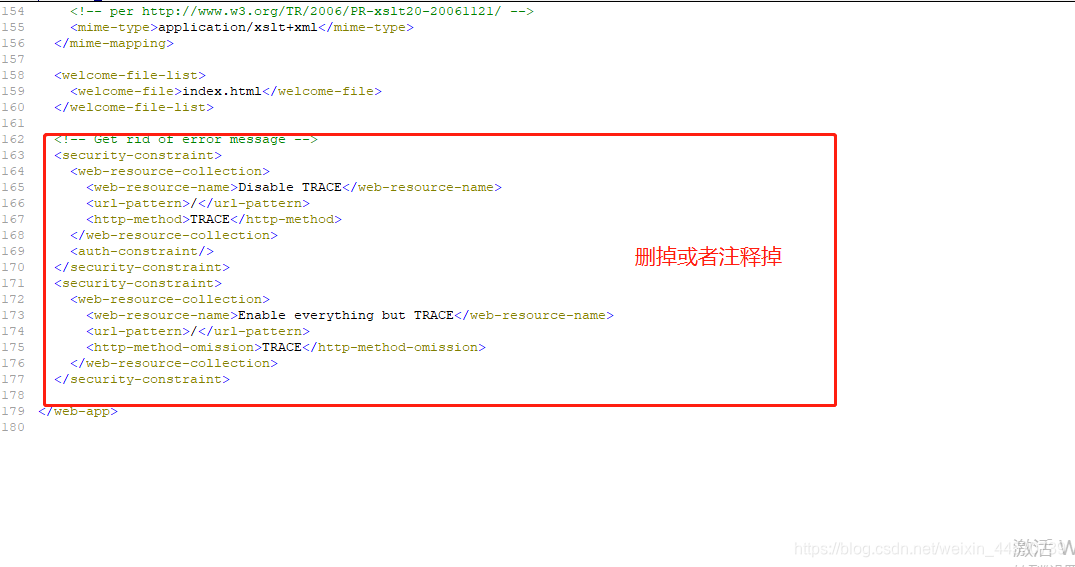
- 修改tomcat里的apache-tomcat-8.5.34\webapps\solr\WEB-INF下的web.xml文件
二. 配置好 启动 tomcat 测试有没有成功
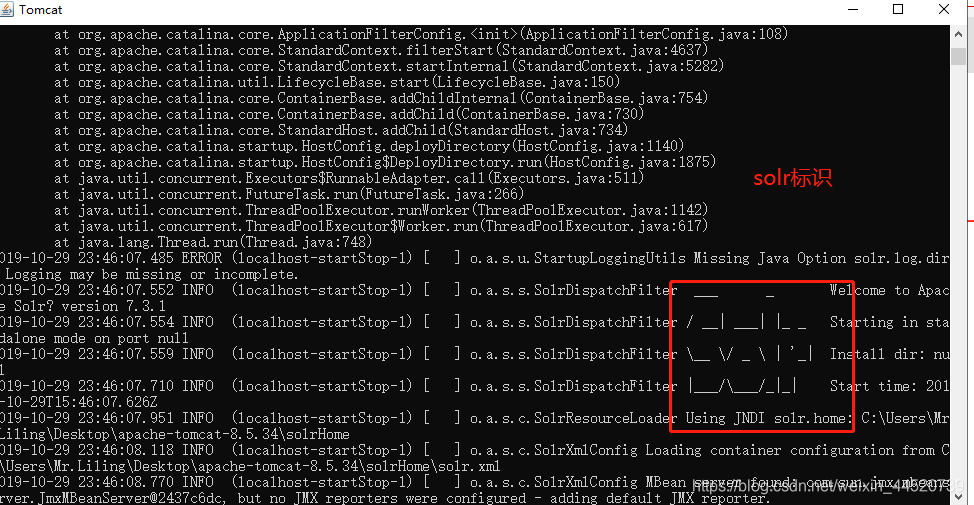
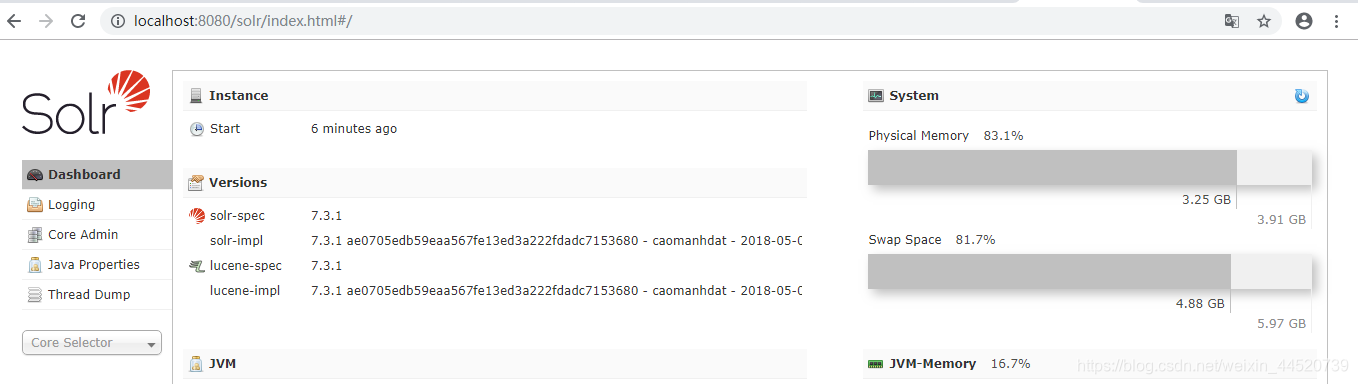
启动没有问题的话访问一下solr的index页面
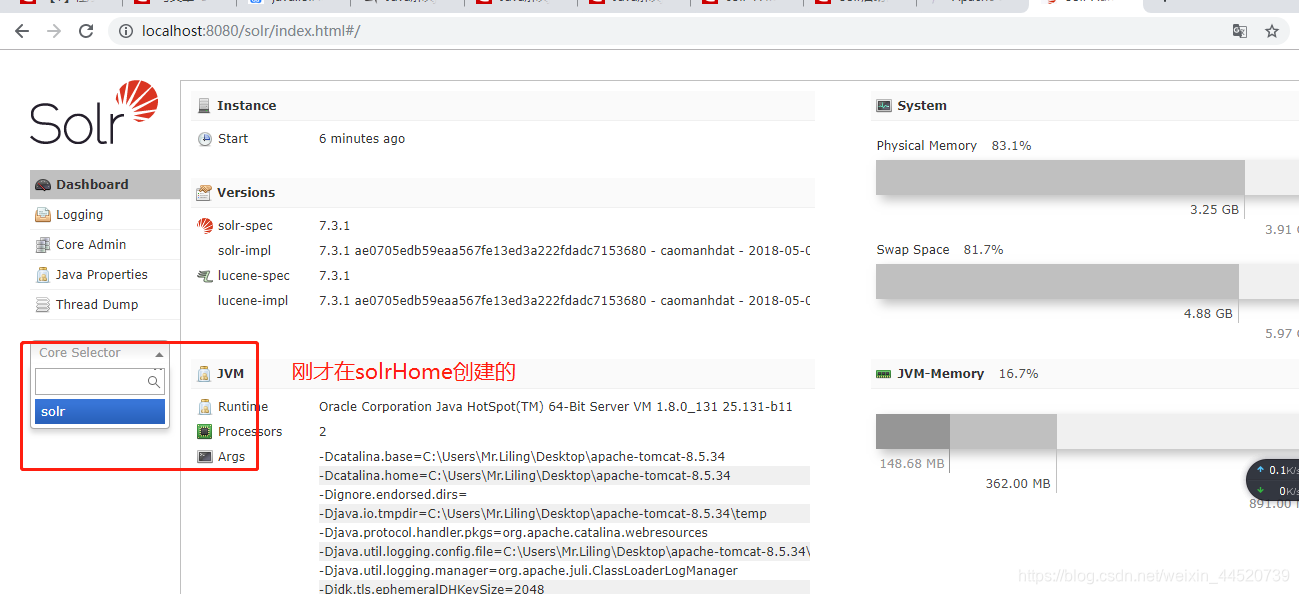
中文分词器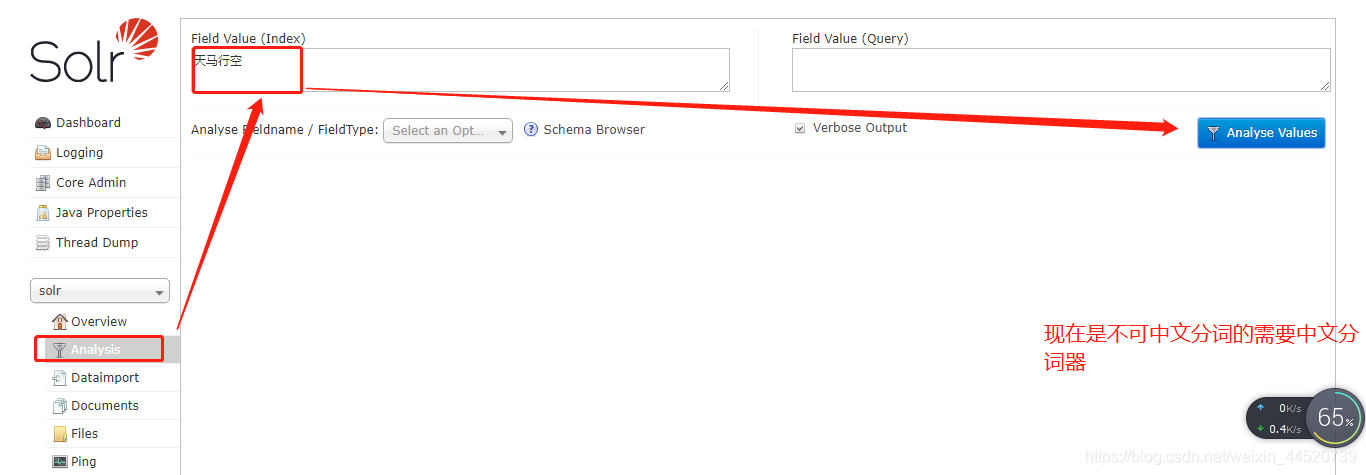
把ikanalyzer分词器解压

三 分词器的配置
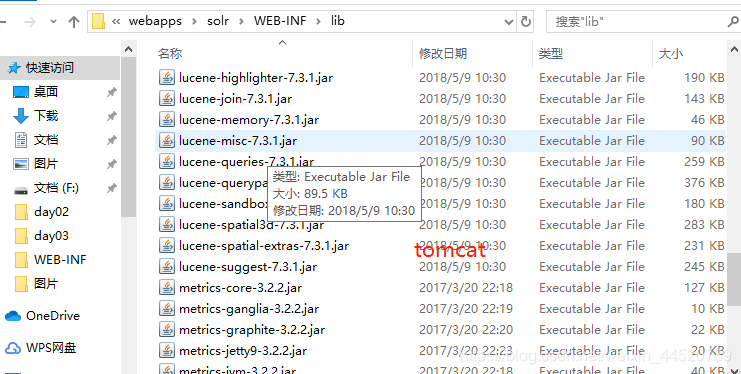
- 把解压好的ikanalyzer下的两个jar包放到apache-tomcat-8.5.34\webapps\solr\WEB-INF\lib下
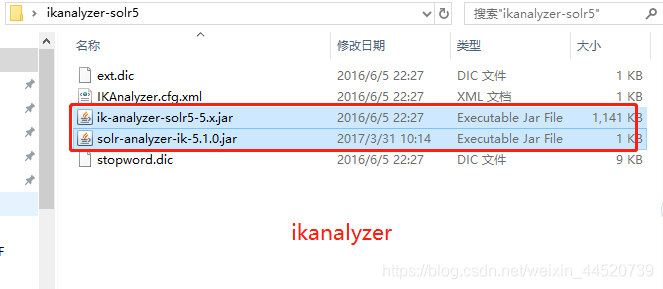
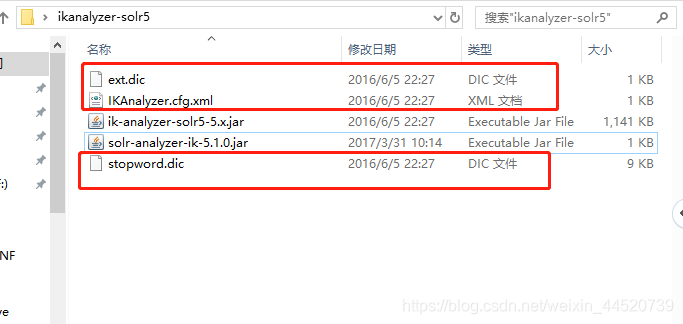
- 把解压好的ikanalyzer下的 剩下的三个文件放到tomcat的classes里
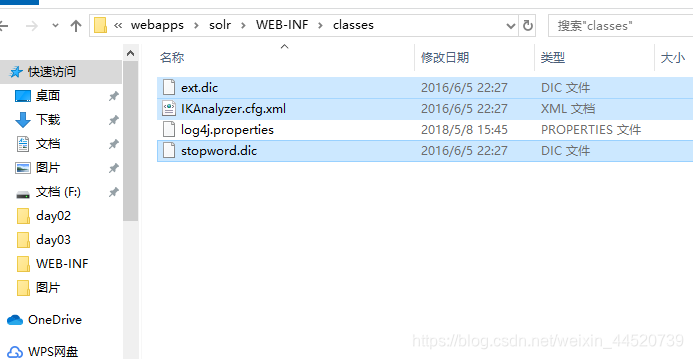
- 找到tomcat下的solrHome下的\solr\conf
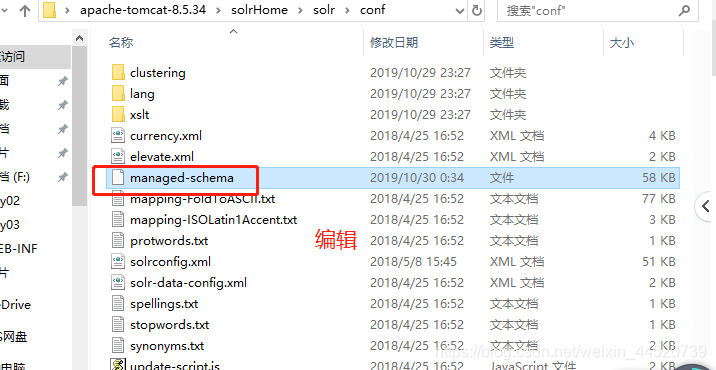
- 添加中文 分词器 和域
<!--定义中文分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!--增加一个域 -->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
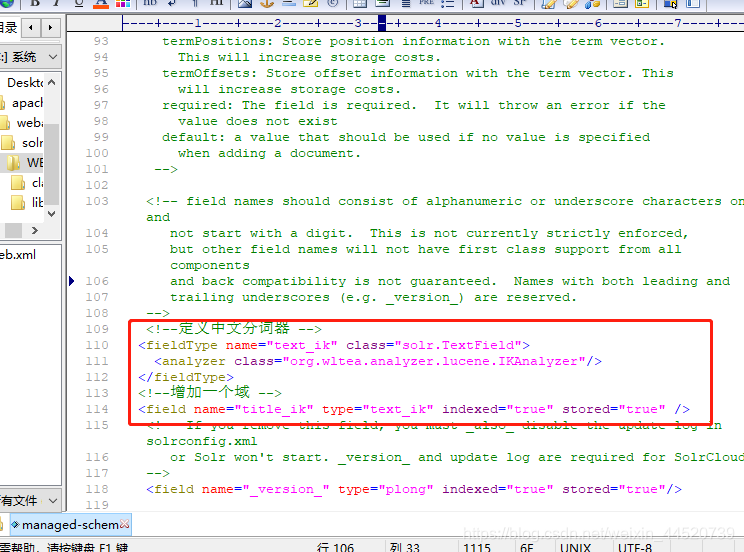
启动tomcat 测试分词器可以中文分词了
如果自己想定义一些词语在apache-tomcat-8.5.34\webapps\solr\WEB-INF\classes有一个ext.dic编辑添加
想忽略的分词设置添加就可以了
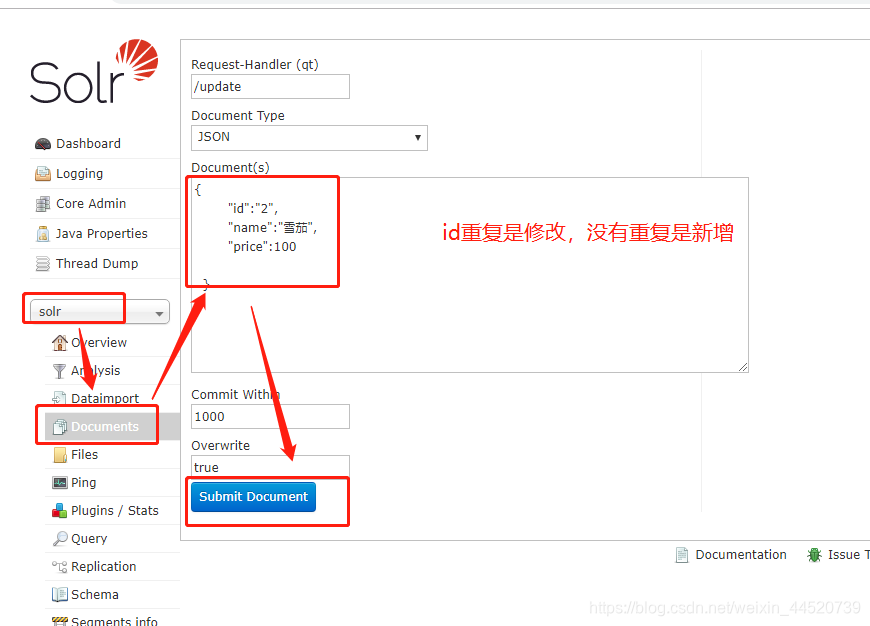
新增词语 json格式 必须有ID
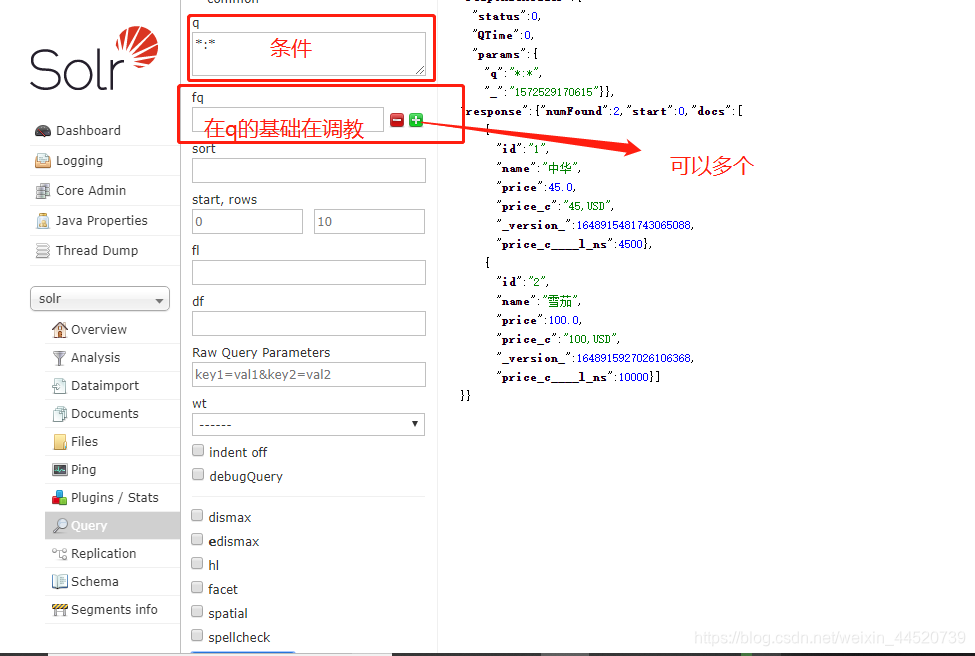
查询
条件
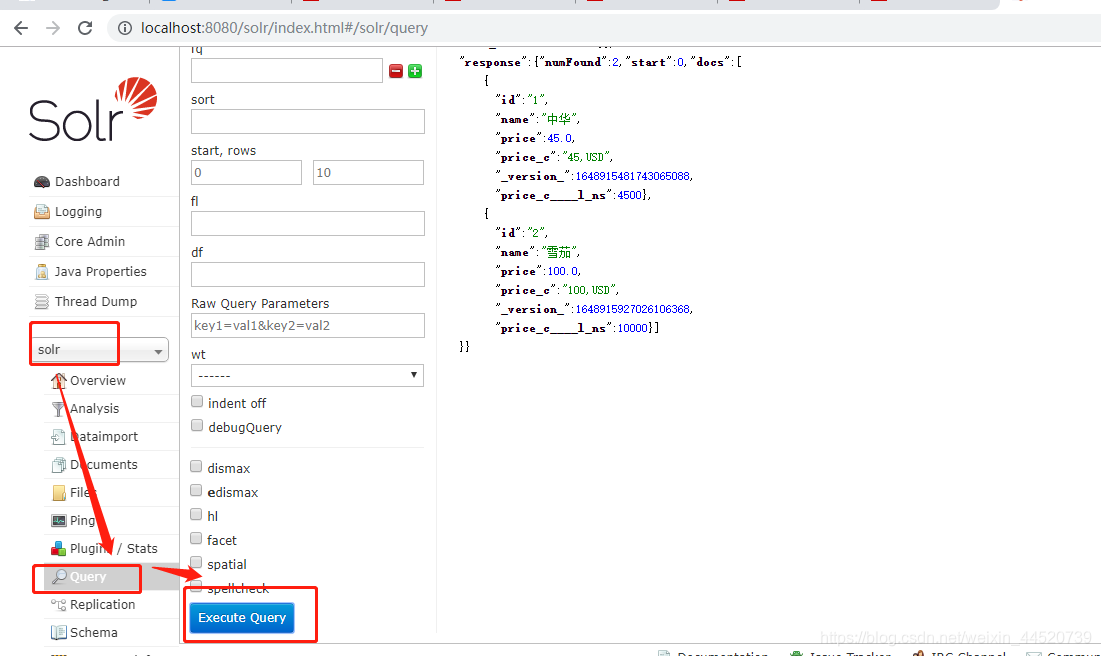
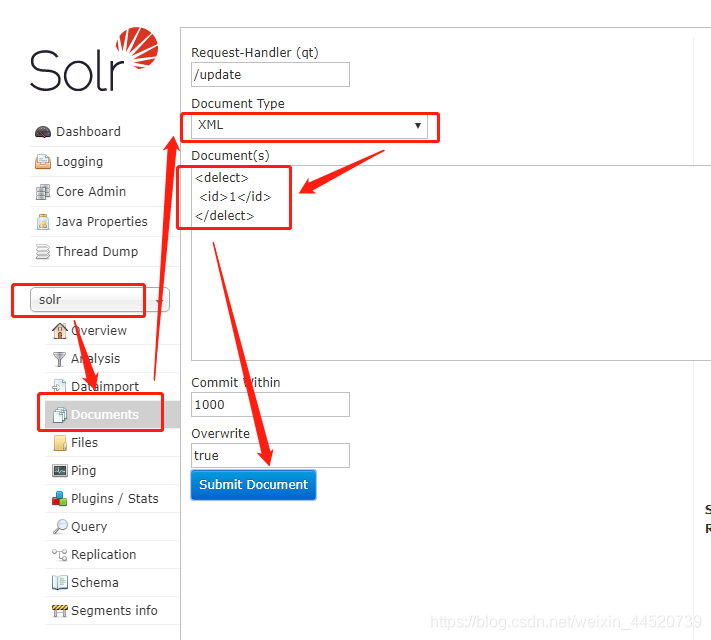
删除注意删除是xml不是json


















 4039
4039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











