







 本文详细介绍了MySQL的基础语法,包括创建、删除数据库和表,查询表结构,修改表结构,以及数据类型的使用。此外,还讲解了查询操作,如条件查询、模糊查询、排序和分组查询,以及聚合函数的应用。在数据库设计部分,阐述了一对一、一对多、多对多的关系建表方法。最后,讨论了内连接、外连接和子查询等多表查询技术,并展示了使用JDBC进行数据查询和新增操作的基本步骤。
本文详细介绍了MySQL的基础语法,包括创建、删除数据库和表,查询表结构,修改表结构,以及数据类型的使用。此外,还讲解了查询操作,如条件查询、模糊查询、排序和分组查询,以及聚合函数的应用。在数据库设计部分,阐述了一对一、一对多、多对多的关系建表方法。最后,讨论了内连接、外连接和子查询等多表查询技术,并展示了使用JDBC进行数据查询和新增操作的基本步骤。
一、数据库
1.mysql通用语法
- 基础语法
单行或多行书写,以分号结尾;
不区分大小写;
单行注释:--;
多行注释:/*注释*/
- 创建数据库/表
create database 名称;
--改进
create database if not exists 数据库名称;
CREATE TABLE 表名 (
字段名1 数据类型1,
字段名2 数据类型2,
…
字段名n 数据类型n
);
--最后一行不能加逗号- 删除数据库/表
drop database if exists 数据库名称;
drop table if exists 表名称;- 查询表结构
desc 表名称- 修改表
--修改表名
ALTER TABLE 表名 RENAME TO 新的表名;
--添加一列
ALTER TABLE 表名 ADD 列名 数据类型;
--修改数据类型
ALTER TABLE 表名 MODIFY 列名 新数据类型;
--修改列名和数据类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型;
--删除列
ALTER TABLE 表名 DROP 列名;2.数据类型
3.查询
- 基础查询

- 条件查询
在where中使用以下运算符
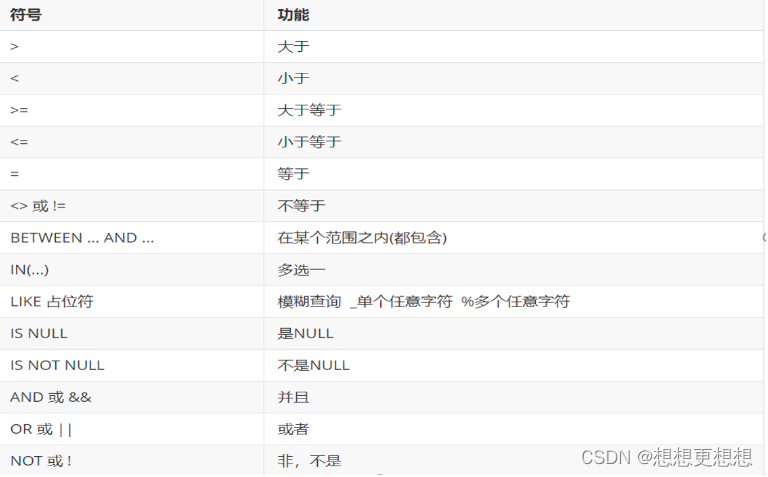
- 模糊查询
模糊查询使用like关键字,可以使用通配符进行占位:
(1)_ : 代表单个任意字符
(2)% : 代表任意个数字符

- 排序查询
ASC : 升序排列 (默认值)
DESC : 降序排列
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …;
--如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序4.聚合函数
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
用法:
SELECT 聚合函数名(列名) FROM 表;5.分组查询
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组
字段名 [HAVING 分组后条件过滤];where 和 having 区别:
-
执行时机不一样:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
-
可判断的条件不一样:where 不能对聚合函数进行判断,having 可以。
6.分页查询
SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查询条目数;
--上述语句中的起始索引是从0开始起始索引 = (当前页码 - 1) * 每页显示的条数
7.约束概念
-
非空约束: 关键字是 NOT NULL
保证列中所有的数据不能有null值。
-
唯一约束:关键字是 UNIQUE
保证列中所有数据各不相同。
-
主键约束: 关键字是 PRIMARY KEY
主键是一行数据的唯一标识,要求非空且唯一。一般我们都会给没张表添加一个主键列用来唯一标识数据。
添加约束:
-- 创建表时添加非空约束
CREATE TABLE 表名(
列名 数据类型 NOT NULL,
…
);
-- 创建表时添加唯一约束
CREATE TABLE 表名(
列名 数据类型 UNIQUE [AUTO_INCREMENT],
-- AUTO_INCREMENT: 当不指定值时自动增长
…
);
-- 创建表时添加主键约束
CREATE TABLE 表名(
列名 数据类型 PRIMARY KEY [AUTO_INCREMENT],
…
); -- 建完表后添加非空约束
ALTER TABLE 表名 MODIFY 字段名 数据类型 NOT NULL;
--ALTER TABLE t_department MODIFY COLUMN dept_no VARCHAR(20) UNIQUE;
-- 建完表后添加唯一约束
ALTER TABLE 表名 MODIFY 字段名 数据类型 UNIQUE;
-- 建完表后添加主键约束
ALTER TABLE 表名 ADD PRIMARY KEY(字段名);-
外键约束: 关键字是 FOREIGN KEY
外键用来让两个表的数据之间建立链接,保证数据的一致性和完整性。
关于外键约束的语法:
-- 创建表时添加外键约束
CREATE TABLE 表名(
列名 数据类型,
…
[CONSTRAINT] [外键名称] FOREIGN KEY(外键列名) REFERENCES 主表(主表列名)
);
-- 建完表后添加外键约束
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);
--删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;二,数据库设计
1.针对数据库关系建表
- 一对一
一对一关系多用于表拆分,将一个实体中经常使用的字段放一张表,不经常使用的字段放另一张表,用于提升查询性能,例如用户和用户详情。
实现方式:在任意一方加入外键,关联另一方主键,并且设置外键为唯一(UNIQUE)

create table tb_user_desc (
id int primary key auto_increment,
city varchar(20),
edu varchar(10),
income int,
status char(2),
des varchar(100)
);
create table tb_user (
id int primary key auto_increment,
photo varchar(100),
nickname varchar(50),
age int,
gender char(1),
desc_id int unique,
-- 添加外键
CONSTRAINT fk_user_desc FOREIGN KEY(desc_id) REFERENCES tb_user_desc(id)
);- 一对多
例如:部门与员工,一个部门对应多个员工,一个员工对应一个部门。
实现方式:在多的一方建立外键,指向一的一方的主键。
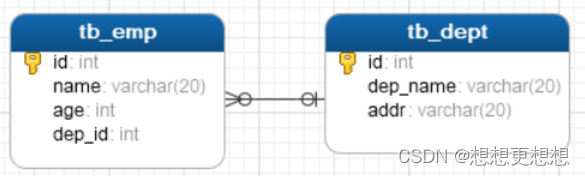
-- 删除表
DROP TABLE IF EXISTS tb_emp;
DROP TABLE IF EXISTS tb_dept;
-- 部门表
CREATE TABLE tb_dept(
id int primary key auto_increment,
dep_name varchar(20),
addr varchar(20)
);
-- 员工表
CREATE TABLE tb_emp(
id int primary key auto_increment,
name varchar(20),
age int,
dep_id int,
-- 添加外键 dep_id,关联 dept 表的id主键
CONSTRAINT fk_emp_dept FOREIGN KEY(dep_id) REFERENCES tb_dept(id)
);- 多对多
例如:商品和订单,一个商品对应多个订单,一个订单包含多个商品
实现方式:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
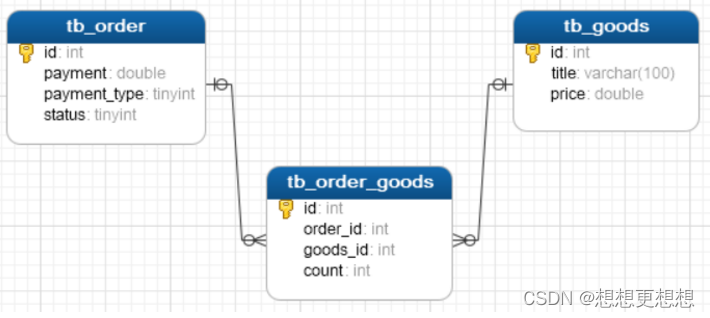
-- 删除表
DROP TABLE IF EXISTS tb_order_goods;
DROP TABLE IF EXISTS tb_order;
DROP TABLE IF EXISTS tb_goods;
-- 订单表
CREATE TABLE tb_order(
id int primary key auto_increment,
payment double(10,2),
payment_type TINYINT,
status TINYINT
);
-- 商品表
CREATE TABLE tb_goods(
id int primary key auto_increment,
title varchar(100),
price double(10,2)
);
-- 订单商品中间表
CREATE TABLE tb_order_goods(
id int primary key auto_increment,
order_id int,
goods_id int,
count int
);
-- 建完表后,添加外键
alter table tb_order_goods add CONSTRAINT fk_order_id
FOREIGN key(order_id) REFERENCES tb_order(id);
alter table tb_order_goods add CONSTRAINT fk_goods_id
FOREIGN key(goods_id) REFERENCES tb_goods(id);三、多表查询
1.内连接查询
内连接相当于查询A与B的交集
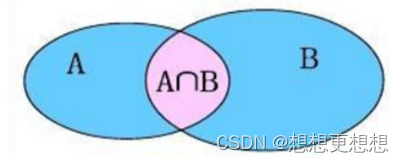
-- 隐式内连接
SELECT 字段列表 FROM 表1,表2… WHERE 条件;
-- 显示内连接,inner可省略
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 条件;2.外连接查询
左外连接:相当于查询A表所有数据和交集部分数据
右外连接:相当于查询B表所有数据和交集部分数据
-- 左外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件;
-- 右外连接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件;3.子查询
子查询使用情况
-
子查询语句结果是单行单列,子查询语句作为条件值,使用 = != > < 等进行条件判断
-
子查询语句结果是多行单列,子查询语句作为条件值,使用 in 等关键字进行条件判断:where (子查询)
-
子查询语句结果是多行多列,子查询语句作为虚拟表:from(子查询)
四、JBDC
设计思路:

写配置文件
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql:///连接的数据库名称?useSSL=false&useServerPrepStmts=true
username=root
password=123
# 初始化连接数量
initialSize=5
# 最大连接数
maxActive=10
# 最大等待时间
maxWait=3000实现查询
/**
* 查询所有
* 1. SQL:select * from tb_brand;
* 2. 参数:不需要
* 3. 结果:List<Brand>
*/
@Test
public void testSelectAll() throws Exception {
//获取连接的Connection对象
//1.加载配置文件
Properties prop=new Properties();
prop.load(new FileInputStream("src/main/java/druid.properties"));
//2.获取连接池对象
DataSource dataSource= DruidDataSourceFactory.createDataSource(prop);
//3.获取数据库连接Connection
Connection connection=dataSource.getConnection();
//4.定义SQL
String sql="select * from tb_brand;";
//5获取pstmt对象
PreparedStatement pstmt=connection.prepareStatement(sql);
//6.设置参数
//根据增删查改传入指定的参数
//7.执行sql
ResultSet rs=pstmt.executeQuery();
//8.处理结果,用List<Brand>封装Brand对象,装载List集合
Brand brand=null;
List<Brand> brands=new ArrayList<Brand>();
while (rs.next()){
//获取数据
int id = rs.getInt("id");
String brandName = rs.getString("brand_name");
String companyName = rs.getString("company_name");
int ordered = rs.getInt("ordered");
String description = rs.getString("description");
int status = rs.getInt("status");
//封装Brand对象
brand=new Brand();
brand.setId(id);
brand.setBrandName(brandName);
brand.setCompanyName(companyName);
brand.setOrdered(ordered);
brand.setDescription(description);
brand.setStatus(status);
//装载集合
brands.add(brand);
}
System.out.println(brands);
rs.close();
pstmt.close();
connection.close();
}新增数据:
/**
* 添加
* 1. SQL:insert into tb_brand(brand_name, company_name, ordered, description, status) values(?,?,?,?,?);
* 2. 参数:需要,除了id之外的所有参数信息
* 3. 结果:boolean
*/
@Test
public void testAdd() throws Exception {
// 接收页面提交的参数
String brandName = "香飘飘";
String companyName = "香飘飘";
int ordered = 1;
String description = "绕地球一圈";
int status = 1;
//1. 加载配置文件
Properties prop = new Properties();
prop.load(new FileInputStream("jdbc-demo/src/druid.properties"));
//2. 获取连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
//3. 获取数据库连接 Connection
Connection conn = dataSource.getConnection();
//4. 定义SQL
String sql = "insert into tb_brand(brand_name, company_name, ordered, description, status) values(?,?,?,?,?);";
//5. 获取pstmt对象
PreparedStatement pstmt = conn.prepareStatement(sql);
//6. 设置参数
pstmt.setString(1,brandName);
pstmt.setString(2,companyName);
pstmt.setInt(3,ordered);
pstmt.setString(4,description);
pstmt.setInt(5,status);
//7. 执行SQL
int count = pstmt.executeUpdate(); // 影响的行数
//8. 处理结果
System.out.println(count > 0);
//9. 释放资源
pstmt.close();
conn.close();
}
















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









