







 超级会员免费看
超级会员免费看
 Transformer模型由Vaswani等人在2017年提出,基于自注意力机制,广泛应用于自然语言处理。本文介绍如何用Tensorflow实现Transformer的编码器层,包括多头自注意力、前馈神经网络、位置编码、残差连接和层归一化。提供了一个简单的编码器层实现示例,并指出在实际应用中可能需要堆叠多层编码器和解码器。
Transformer模型由Vaswani等人在2017年提出,基于自注意力机制,广泛应用于自然语言处理。本文介绍如何用Tensorflow实现Transformer的编码器层,包括多头自注意力、前馈神经网络、位置编码、残差连接和层归一化。提供了一个简单的编码器层实现示例,并指出在实际应用中可能需要堆叠多层编码器和解码器。
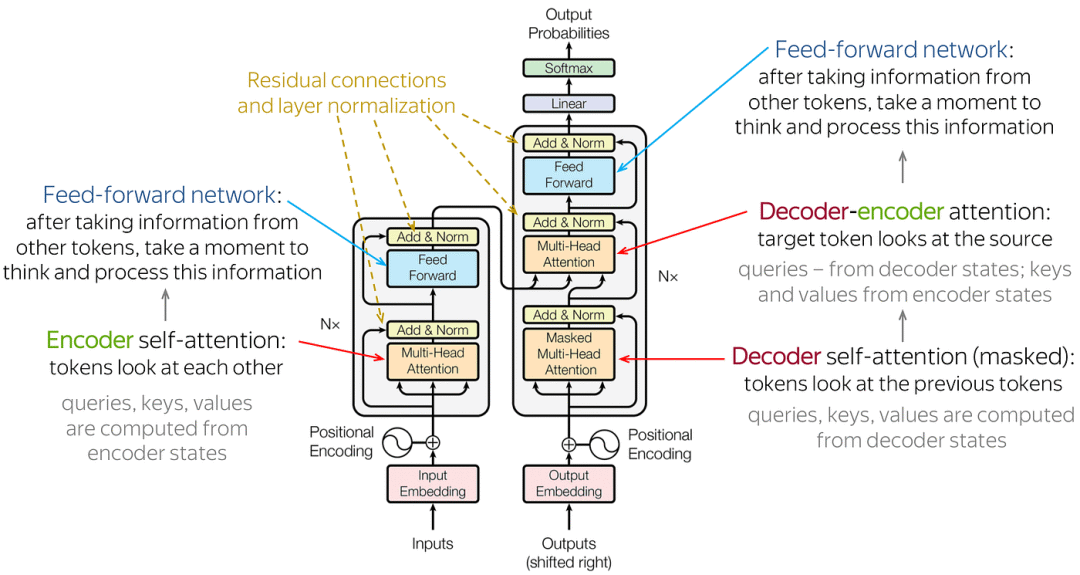
Transformer是一种基于自注意力机制(self-attention mechanism)的深度学习模型,最初由Vaswani等人于2017年提出,广泛用于自然语言处理任务,如机器翻译、文本生成等。以下是Transformer的基本原理:
-
自注意力机制(Self-Attention Mechanism):
- Transformer的核心是自注意力机制,也称为多头注意力机制。它允许模型在处理序列数据时对不同位置的信息分配不同的注意力权重。
- 在每一层中,输入序列被映射为三个向量:查询(Query)、键(Key)、值(Value)。
- 通过计算查询和键之间的点积,得到注意力分数。将注意力分数经过softmax操作,得到权重,再将权重与值相乘并求和,得到最终的自注意力输出。
-
多头注意力机制(Multi-Head Attention):
- Transformer不仅使用单个自注意力头ÿ

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1874
1874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











