







 超级会员免费看
超级会员免费看
 本文详细介绍了如何使用Fiddler进行HTTP抓包,包括HTTP原理、Fiddler的设置与使用,以及如何配置Fiddler进行HTTPS抓包。内容涵盖了设置全局与指定断点、过滤和搜索请求、解析请求与响应详情,以及在移动设备上抓包的步骤。通过Fiddler,可以方便地调试和分析网络请求。
本文详细介绍了如何使用Fiddler进行HTTP抓包,包括HTTP原理、Fiddler的设置与使用,以及如何配置Fiddler进行HTTPS抓包。内容涵盖了设置全局与指定断点、过滤和搜索请求、解析请求与响应详情,以及在移动设备上抓包的步骤。通过Fiddler,可以方便地调试和分析网络请求。
@Author :Runsen
文章目录
http原理
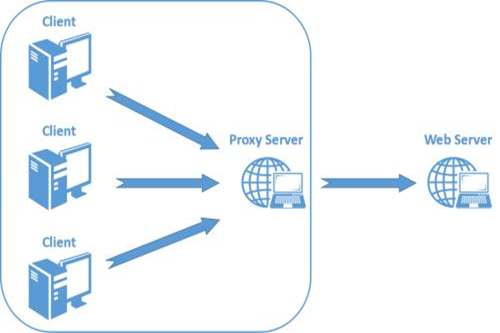
所谓的http代理,其实就是代理客户机的http访问,主要代理浏览器访问页面。
代理服务器是介于浏览器和web服务器之间的一台服务器,有了它之后,浏览器不是直接到Web服务器去取回网页而是向代理服务器发出请求,Request信号会先送到代理服务器,由代理服务器来取回浏览器所需要的信息并传送给你的浏览器。
fiddler的使用
抓包工具抓取HTTPS的包的时候跟HTTP的直接转发是不同的。所以我们需要配置HTTPS的证书。
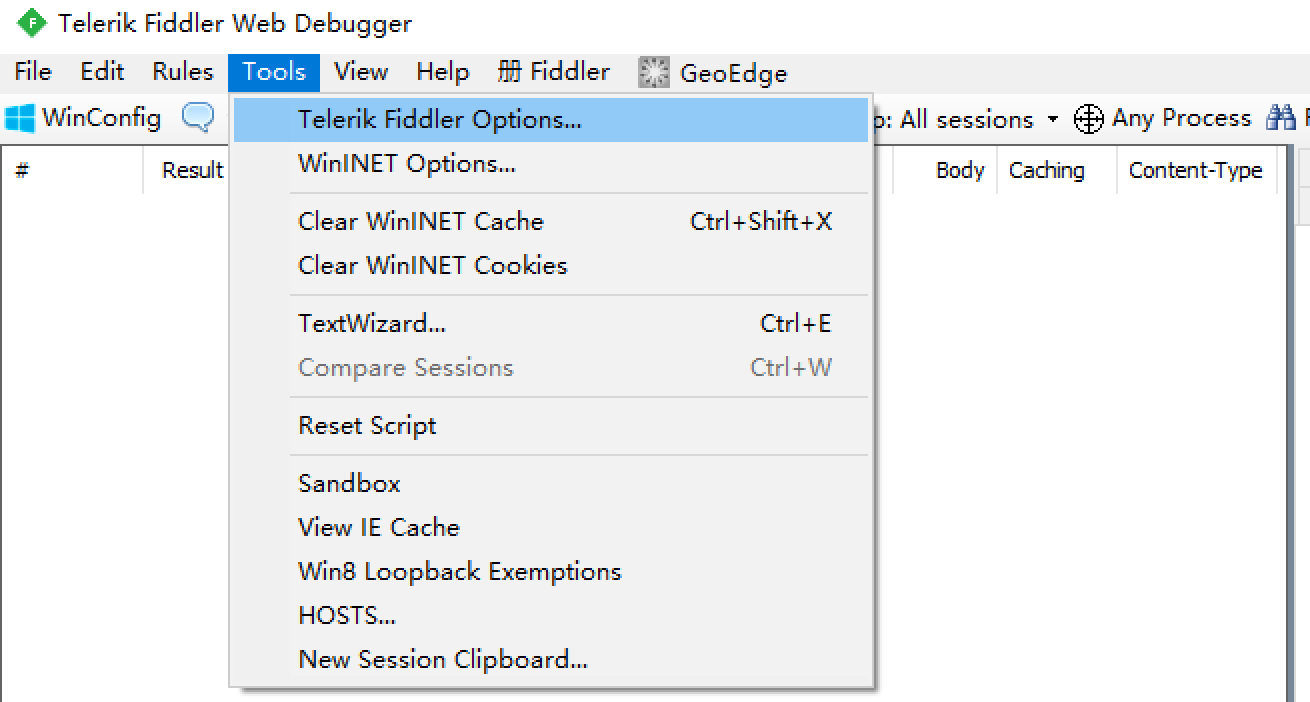
打开后选择HTTPS,勾选上这个选项,然后勾选上下方出现的两个选项。最后再将弹出的窗口都选择yes
设置
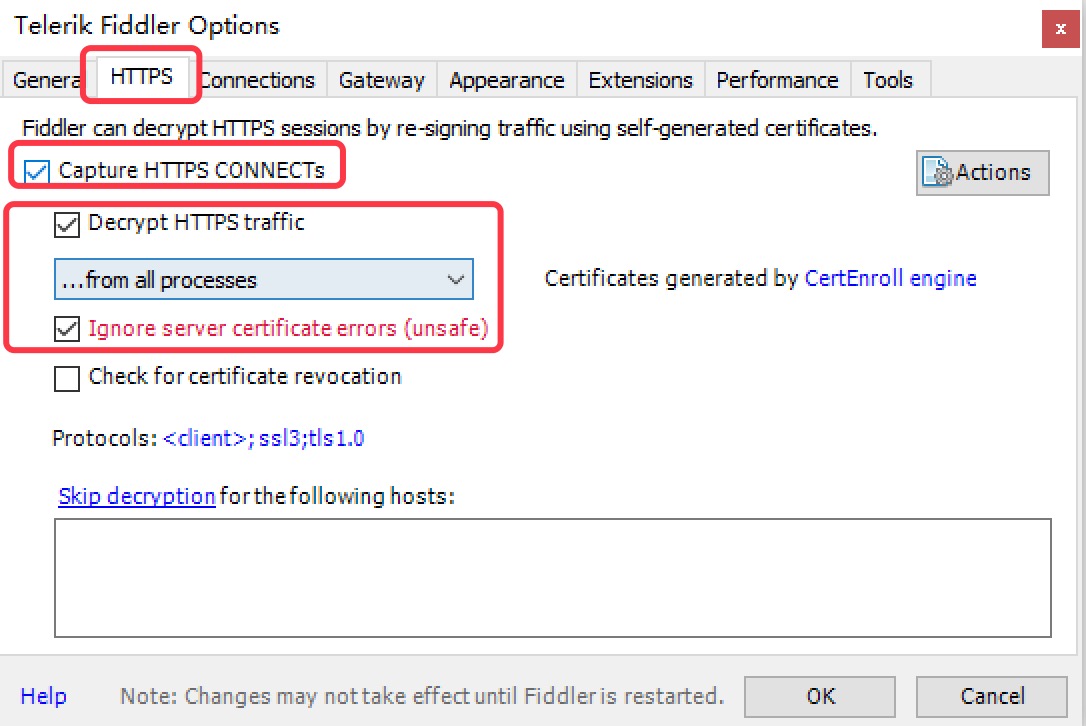
- Capture HTTPS CONNECTs 捕捉HTTPS连接
- Decrypt HTTP

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











