







 超级会员免费看
超级会员免费看
 本文详细介绍了在Scrapy中如何复写默认的图片管道,包括`get_media_requests`方法的使用来添加请求头,以及`item_completed`方法来保存文件路径。此外,文章还探讨了Rule的用法,用于设定爬取优先级,并解释了如何通过Link Extractor对象定义链接提取规则。虽然示例中的27270图片网站已无法访问,但提供了修改默认ImagesPipeline以自定义图片保存名称的代码示例。
本文详细介绍了在Scrapy中如何复写默认的图片管道,包括`get_media_requests`方法的使用来添加请求头,以及`item_completed`方法来保存文件路径。此外,文章还探讨了Rule的用法,用于设定爬取优先级,并解释了如何通过Link Extractor对象定义链接提取规则。虽然示例中的27270图片网站已无法访问,但提供了修改默认ImagesPipeline以自定义图片保存名称的代码示例。
@Author:Runsen
上文用scrapy 爬百度美女图片,补充如何重写默认管道知识点,当年爬取的网站是:http://www.27270.com/。但是这里也访问不了,网站没了。所以下面的笔记当作回忆。

上次我们是直接使用了图片管道,有时候我们需要重写管道。
一般重写get_media_requests 和item_completed
- get_media_requests 一般用来加上请求头
- item_completed 保存路径
下面就是图片管道的源码
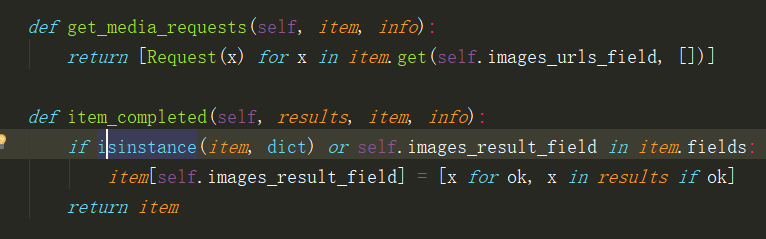
下面的代码是之前用Scrapy爬取百度图片的pipelines.py,现在我们重写了get_media_requests,和item_completed方法。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











