







 博客介绍了特征提取相关内容。在词袋模型因词汇字典表过大难以使用时,可应用哈希技巧降维,介绍了Hash函数特点及流行的Hash函数,还提到用有符号哈希函数解决碰撞问题。此外,阐述了图片特征提取,如将图片像素矩阵reshape拼接成向量,以及提取兴趣点和轮廓等。
博客介绍了特征提取相关内容。在词袋模型因词汇字典表过大难以使用时,可应用哈希技巧降维,介绍了Hash函数特点及流行的Hash函数,还提到用有符号哈希函数解决碰撞问题。此外,阐述了图片特征提取,如将图片像素矩阵reshape拼接成向量,以及提取兴趣点和轮廓等。
上文特征的提取(上)
特征哈希向量
词袋模型的方法很好用,也很直接,但在有些场景下很难使用,比如分词后的词汇字典表非常大, 达到100万+,此时如果直接使用词频向量或Tf-idf权重向量的方法,将对应的样本对应特征矩阵载 入内存,有可能将内存撑爆,在这种情况下我们该怎么办呢?
词袋模型的方法很好用,也很直接,但在有些场景下很难使用,比如分词后的词汇字典表非常大, 达到100万+,此时如果直接使用词频向量或Tf-idf权重向量的方法,将对应的样本对应特征矩阵载 入内存,有可能将内存撑爆,在这种情况下我们该怎么办呢?
我们可以应用哈希技巧进行降维。
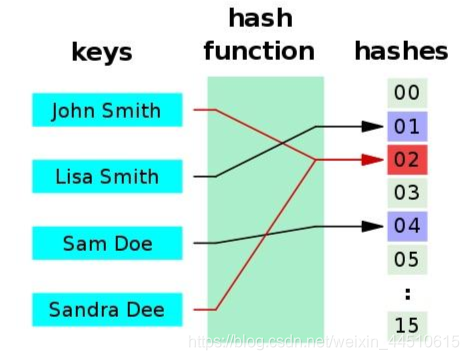
Hash函数可以将一个任意长度的字符串映射到一个固定长度的散列数字中去。Hash函数是一种典 型的多对一映射。
- 正向快速:给定明文和 hash 算法,在有限时间和有限资源内能计算出 hash 值。
- 逆向困难:给定(若干) hash 值,在有限时间内很难(基本不可能)逆推出明文。
- 输入敏感:原始输入信息修改一点信息,产生的 hash 值看起来应该都有很大不同。
- 碰撞避免:很难找到两段内容不同的明文,使得它们的 hash 值一致(发生碰撞)。即对 于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和 它hash值相同的数据块极为困难。
目前流行的Hash函数包括MD4,MD5,SHA等。
利用HashingVectorizer的n_features设置可以将特征数量降至任意我们想要的范围。但是由于碰撞 可能发生,有些特征的值会由于碰撞累加得过高产生偏差。HashingVectorizer通过使用有符号哈希 函数巧妙地解决了这个问题。
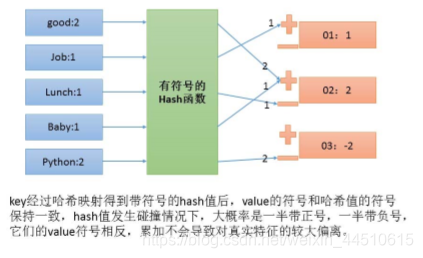
scikitlearn提供了HashingVectorizer来实现这个技巧:哈希技巧是无固定状态的(stateless),它把任意的数据块映射到固定数目的位置,并且保证相同的输入一定产生相同的输出,不同的输入尽可能产生不同的输出。它可以用并行,线上,流式传输创建特征向量,因为它初始化是不需要文集输入。n_features是一个可选参数,默认值是 ,这里设置成6是为了演示。另外,注意有些单词频率是负数。由于Hash碰撞可能发生,所以HashingVectorizer用有符号哈希函数(signed hash function)。
from sklearn.feature_extraction.text import HashingVectorizer
corpus = ['the', 'ate', 'bacon', 'cat']
vectorizer = HashingVectorizer(n_features=6) #6个特征
# Hashingvecto rizer是无状态的,你不需要fit它
print(vectorizer.transform(corpus).todense())
out:
[[-1. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 1. 0. 0.]
[ 0. 0. 0. 0. -1. 0.]
[ 0. 1. 0. 0. 0. 0.]]
因为不知道 hash 应用了什么函数,输出的结果很难知道什么意思
应用多行文本
from sklearn.feature_extraction.text import HashingVectorizer
corpus = [ 'UNC played Duke in basketball', 'Duke lost the basketball game,game over', 'I ate a sandwich' ]
vectorizer = HashingVectorizer(n_features = 3)
counts = vectorizer.transform(corpus).todense()
print(counts)
counts.shape
OUT:
[[ 0. 0. -1. ]
[-0.33333333 -0.66666667 -0.66666667]
[ 0.70710678 0. 0.70710678]]
(3, 3)
图片特征提取
一张图片可以看成是一个每个元素都是颜色值的矩阵。表示图像基本特征就是将矩阵每行连起来变成一个行向量。光学文字识别(Optical character recognition,OCR)是机器学习的经典问题。
这里有张meinv图片

图片特征提取的基本方法是获取图片的像素矩阵,并将其reshape拼接成为一个行向量。
- 提取像素矩阵
import skimage.io as io #用skimage中的io 导入图片
import matplotlib.pyplot as plt
%matplotlib inline
imrgb = io.imread('meinv.jpg') #提取像素
print('before reshape:',imrgb.shape)
#第三个维度分别对应r,g,b像素值
#将imrgb拼接成为一个行向量
imvec = imrgb.reshape(1,-1)
print('after reshape:',imvec.shape)
plt.gray() # 灰度图
fig, axes = plt.subplots(2,2,figsize=(12,10))
ax0,ax1,ax2,ax3= axes.ravel()
ax0.imshow(imrgb)
ax0.set_title('original image')
ax1.imshow(imrgb [:,:,0]) #R通道
ax1.set_title('red channel')
ax2.imshow(imrgb [:,:,1]) # G通道
ax2.set_title('green channel')
ax3.imshow(imrgb [:,:,2]) # B通道
ax3.set_title('blue channel')
before reshape (616,600,3)说明图像的像素是616*600,rgb 的值在第三个维度
原图中越红的地方在red channel越亮

#转换成灰白图像
from skimage.color import rgb2gray
import matplotlib.pyplot as plt
import skimage.io as io
from skimage.exposure import equalize_hist
plt.gray()
imgray = equalize_hist(rgb2gray(imrgb))
#转换成黑白图并使直方图均衡化,增强对比
io.imshow(imgray)
# 转换成一个行向量
imvec = imgray.reshape(1,-1)
imvec.shape
- 提取兴趣点(角点)
import numpy as np
from skimage.feature import corner_harris, corner_peaks
from skimage.color import rgb2gray
import matplotlib.pyplot as plt
import skimage.io as io
from skimage.exposure import equalize_hist
def show_corners(corners, image):
fig = plt.figure()
plt.gray()
plt.imshow(image)
y_corner, x_corner = zip(*corners)
plt.plot(x_corner, y_corner, 'or')
plt.xlim(0, image.shape[1])
plt.ylim(image.shape[0], 0)
fig.set_size_inches(np.array(fig.get_size_inches()) * 1.5)
plt.show()
imrgb = io.imread('meinv.jpg')
imgray = equalize_hist(rgb2gray(imrgb))
corners = corner_peaks(corner_harris(imgray), min_distance=2)
show_corners(corners, imgray)

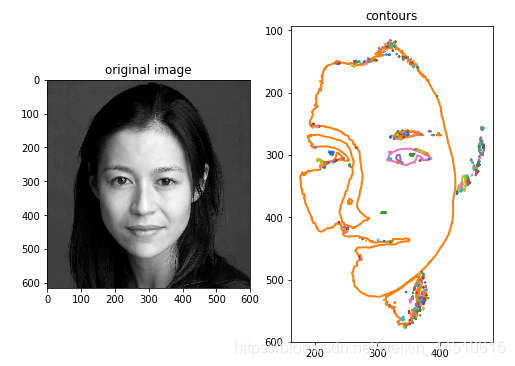
- 提取轮廓
import matplotlib.pyplot as plt
from skimage import measure,data,color
#生成二值测试图像
imrgb = io.imread('meinv.jpg')
img=color.rgb2gray(imrgb)
#检测所有图形的轮廓
contours = measure.find_contours(img, 0.5)
#绘制轮廓
fig, axes = plt.subplots(1,2,figsize=(8,8))
ax0, ax1= axes.ravel()
ax0.imshow(img,plt.cm.gray)
ax0.set_title('original image')
rows,cols=img.shape
ax1.axis([0,rows,cols,0])
for n, contour in enumerate(contours):
ax1.plot(contour[:, 1], contour[:, 0], linewidth=2)
ax1.axis('image')
ax1.set_title('contours')
plt.show()


















 6360
6360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











