







 本文详细介绍了sklearn库中的数据集划分,包括训练集和测试集的分割方法。接着讨论了转化器与估计器的概念,特别是k-近邻算法和朴素贝叶斯的实现。文章还涵盖了决策树的构建原理,如信息熵和信息增益,以及随机森林的集成学习方法。
本文详细介绍了sklearn库中的数据集划分,包括训练集和测试集的分割方法。接着讨论了转化器与估计器的概念,特别是k-近邻算法和朴素贝叶斯的实现。文章还涵盖了决策树的构建原理,如信息熵和信息增益,以及随机森林的集成学习方法。
一.sklearn数据集
1.sklearn数据集划分
训练集:测试集=7:3或者8:2或者75%:25%(取75%:25%)
训练数据:用于训练,构建模型。
测试数据:在模型检验时使用,用于评估模型是否有效。
2.API
sklearn.model_selection.train_test_split
sklearn.datasets:加载数据集
datasets.load_* ():小规模数据集,数据包含在datasets里
datasets.fetch_*(data_home=None):获取大规模数据集,须从网上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是~/scikit_learn_data/
3.获取数据集返回的类型
load* 和fetch* 返回的数据类型datasets.base.bunch(字典格式)
data:特征数据数组是[n_samples*n_features]的二维numpy.ndarray数组
target:标签组是n_samples的一维numpy.ndarray数组
DESCR:数据描述
feature_names:特征名(例如新闻数据、手写数字)
target_names:标签名
数据集选取鸢尾花数据集,代码如下所示:
from sklearn.datasets import load_iris
li = load_iris()
print("获取特征值")
print(li.data)
print("目标值")
print(li.target)
print("数据描述信息")
print(li.DESCR)
4.数据集进行分割
sklearn.model_selection.train_test_split(*arrays,**options)
X:数据集的特征值
Y:数据集的标签值
test_size:测试集的大小,一般为float
random_state:随机数种子
return:训练集特征值,测试集特征值,训练标签,测试标签(默认随机取)
代码如下所示:
from sklearn.model_selection import train_test_split
li = load_iris()
# 训练集train:x_train, y_train; 测试集test:x_test, y_test
x_train, x_test, y_train, y_test = train_test_split(
li.data, li.target, test_size=0.25)
print("训练集特征值和目标值:", x_train, y_train)
print("测试集特征值和目标值:", x_test, y_test)
5.用于分类的大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
subset:‘train’或者‘test’,‘all’。可选择要加载的数据集,训练集的“训练”,测试集的“测试”,两者的全部。
datasets.clear_data_home(data_home=None)消除目录下的数据
二.转化器与估计器
1、fit_transform():输入数据直接转换
fit():输入数据但不做事情。transform():进行数据的转换。
实例化的是一个转换器类(Transformer)
2、在sklearn中,估计器(estimator)是一个重要的角色,是一个类实现了算法的API。
(1)用于分类的估计器:
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression逻辑回归
sklearn.tree决策树与随机森林
(2)用于回归的估计器:
sklearn.linear_model.LinearRegression线性回归
sklearn.linear_model.Ridge岭回归
三.k-近邻算法
k近邻算法(KNN)——需要做标准化处理
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的太多数属于某一类别,则该样本也属于这个类别。
来源:KNN算法最早由Cover和Hart提出的一种分类算法。
距离公式:(欧式距离)
a(a1,a2,a3) , b(b1,b2,b3)
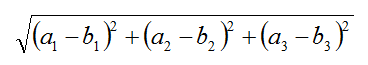
相似的样本,特征之间的值应该都是相近的。
1、API:sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)
n_neighbors:int可选(默认5),k_neighbors查询默认使用的邻居数
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},auto将尝试根据传递给fit方法的值来决定最合适的算法。
2、k值的影响结果:
k值取很小:容易受异常点影响。
k值取很大:容易受k值数量(类别)波动。
3、性能问题:复杂度高。
4、优缺点:
优点:简单,易于理解,易于实现,无需估计参数,无需训练。
缺点:懒惰算法,对测试样本分类时的计算量大,内存开销大。必须指定k值,k值选择不当则分类精度不能保证。
5、使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试。
四.朴素贝叶斯
1、概率定义为一件事情发生的可能性。
联合概率:包含多个条件,且所有条件同时成立的概率
P(A B)=P(A)P(B)。
条件概率:在事件B已经发生条件下,事件A发生的概率P(A|B)。
2、公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









