







1.MySQL支持哪些存储引擎?
| 特点 | InnoDB | MyISAM | Memory |
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行级锁,表锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 支持外键 | 支持 | - | - |
| 文件 | xxx.ibd存放表结构,数据,索引信息 | xxx.sdi:存储表结构信息 xxx.MYD:存储数据 xxx.MYI:存储索引 | xxx.sdi:存储表结构信息 |
存储引擎的选择:
InnoDB:MySQL的默认存储引擎,对事务的完整性有较高要求,在并发条件下要求数据一致。
MyISAM:应用以插入和查询操作为主,对事务的完整性,并发性要求不高。
MEMORY:所有数据保存在内存中,访问速度快,通常用于临时表及缓存,并对表大小有限制。
2.聚簇索引与非聚簇索引
聚簇索引:将数据存储与索引放到一块,索引结构的叶子节点保存了行数据;
二级索引:将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键。
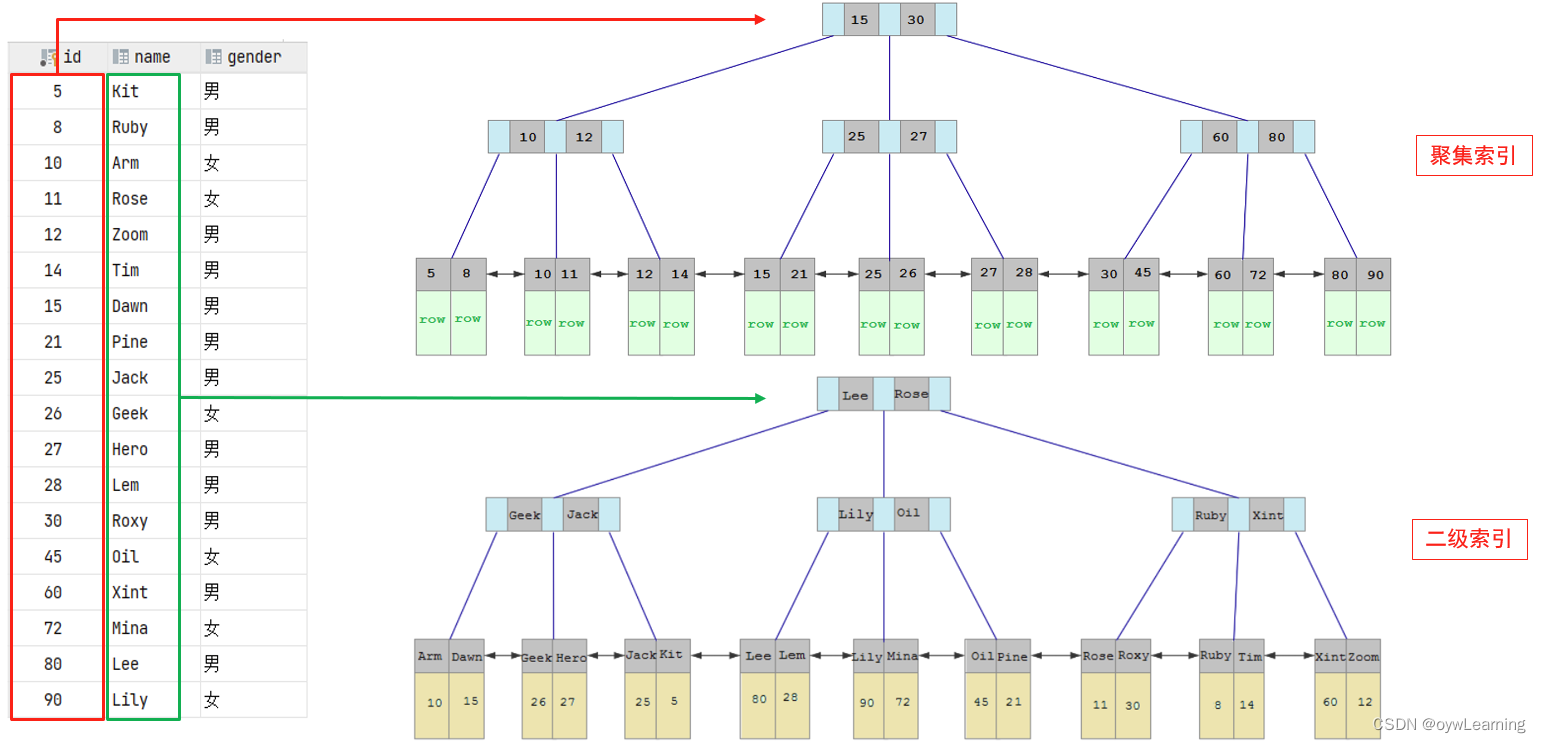
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,避免回表查询,而非单列索引。
3.索引失效的场景
- 不满足最左法则;
- 对索引使用><;
- 使用头部模糊匹配"__xxx";
- 对索引进行运算操作;
- 字符串不加引号;
- or后面的索引;
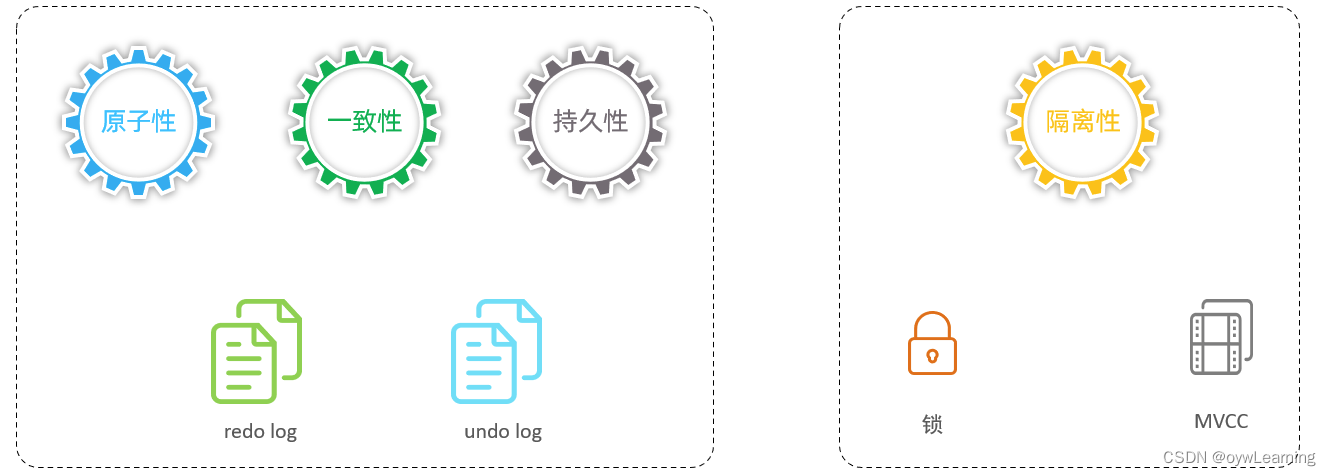
4.事务的四个特征
*一致性:事务完成时,所有的数据都保持一致状态。
原子性:事务时不可分割的最小操作单元,要么全部成功,要么全部失败。
隔离性:数据库系统提供的隔离机制,保证事务不受外部并发操作的影响。
*持久性:事务一旦提交或回滚,他对数据库中数据的改变是永久的。
5.快照读与MVCC
多版本并发控制(MVCC)是一种用来解决读-写冲突的无锁并发控制。
在并发读写数据库时,可以做到在读操作时不用阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能 同时还可以解决脏读,幻读,不可重复读等事务隔离问题,但不能解决更新丢失问题。
RC隔离级别下的快照读:
每次在进行insert、update、delete的时候都会在undo log日志中产生回滚日志。每条记录包含有DB_TRX_ID和DB_ROLL_PTR两个数据用于RC隔离级别下的快照读。
DB_TRX_ID : 代表最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID,是自增的。DB_ROLL_PTR : 代表回滚指针,用来指定如果发生回滚,回滚到哪一个版本。
| 条件 | 是否可以访问 | 说明 |
| 版本链对应事务ID==ReadView创建者事务ID | 可以访问 | 说明数据是当前这个事务修改的 |
| 版本链对应事务ID<最小活跃事务ID | 可以访问 | 说明数据已经提交 |
| 版本链对应事务ID>最大活跃事务ID+1 | 不可以访问 | 说明该事务是在ReadView后才开启的 |
| 最小活跃事务ID<=版本链对应事务ID<=最大活跃事务ID+1 | 当版本链对应事务ID不在目前活跃ID集合中,可以访问 | 说明数据已经提交 |
如下图示例第一次快照读具体的读取过程:
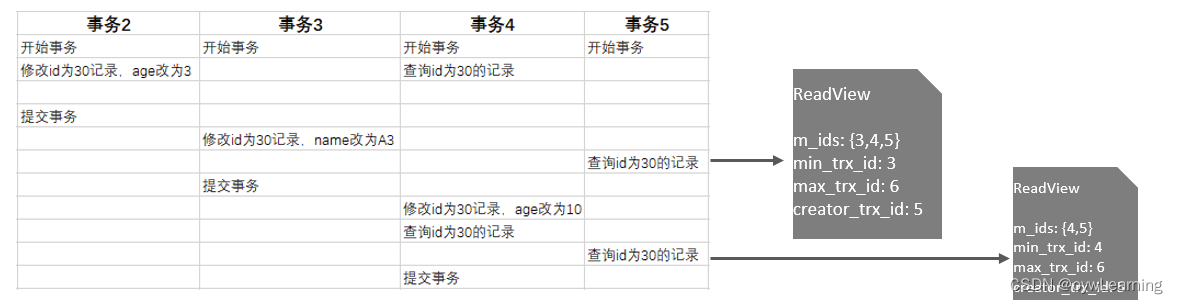

RR隔离级别下的快照读:
在RR隔离级别下,仅在事务第一次执行快照读时生成ReadView,后续复用该ReadView。RR是可重复读的,在一个事务中,执行两次相同的查询语句,查询到的结果时一样的。
6.脏读、不可重复读、幻读
脏读:
- 事务B第一次读取数据库中的数据,数据没有变化;
- 事务B与事务A并发执行,事务A修改了id=1的数据,但是没有提交;
- 事务B再次执行数据库中的数据,检测到id=1的数据变化,但是此时事务A还没有提交;
不可重复读:
- 由于事务A在第一次查询数据库中id=1时,数据不变;
- 事务B更新数据库中id=1的数据,但是未提交,此时事务A在第一次查询数据库中id=1时,数据不变;
- 当事务B提交以后,事务A再次查询数据库中id=1的数据,数据发生变化;
幻读:
- 事务A查询数据库中是否存在id=1的数据,查询结果是不存在;
- 此时事务B在数据库中插入id=1的数据;
- 由于避免“不可重复读”,此时事务A查询数据库中id=1的数据还是不存在,但是向其中插入id=1的数据却会报错,因为事务B已经插入过了,只是还没提交事务;
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| ***RU | √ | √ | √ |
| RC | × | √ | √ |
| RR | × | × | √ |
| ***可串行化 | × | × | × |
7.MySQL的索引调优
- 前缀索引优化:在一些大字符串的字段作为索引时,使用前缀索引可以帮助我们减小索引项的大小。
- 覆盖索引优化:建立一个联合索引,即「商品ID、名称、价格」作为一个联合索引。如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。
- 主键索引设为自增:每次插入一条新记录,都是追加操作,不需要重新移动数据,因此这种插入数据的方法效率非常高。
- 索引设置为NOT NULL:索引列存在 NULL 就会导致优化器在做索引选择的时候更加复杂,NULL 值是一个没意义的值,但是它会占用物理空间。
- 防止索引失效

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









