









 文章介绍了如何在Sharding-JDBC中使用默认数据源来简化大量表的配置,当找不到特定数据节点时,操作会自动转向默认数据源。测试代码展示了如何在未配置分片规则的情况下,通过默认数据源进行数据操作。
文章介绍了如何在Sharding-JDBC中使用默认数据源来简化大量表的配置,当找不到特定数据节点时,操作会自动转向默认数据源。测试代码展示了如何在未配置分片规则的情况下,通过默认数据源进行数据操作。
当一个数据库中有大量的表,如果每个表都配置数据节点,代码变得非常繁琐,这时可以使用配置默认数据源,当sharding-jdbc找不到数据节点的时候会找默认数据源下的数据节点,省区了繁琐的配置
执行sql
-- 构建数据
create database default_db character set utf8;
use default_db;
-- 构建表
create table tb_log (
id bigint primary key ,
info varchar(30)
);
在test2文件中加入代码
spring.shardingsphere.datasource.names=ds1,ds2,udb,defdb
# 数据库连接池类名称
spring.shardingsphere.datasource.defdb.type=com.alibaba.druid.pool.DruidDataSource
# 数据库驱动类名
spring.shardingsphere.datasource.defdb.driver-class-name=com.mysql.cj.jdbc.Driver
# 数据库 url 连接
spring.shardingsphere.datasource.defdb.url=jdbc:mysql://localhost:3306/default_db?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
# 数据库用户名
spring.shardingsphere.datasource.defdb.username=root
# 数据库密码
spring.shardingsphere.datasource.defdb.password=root123
#spring.shardingsphere.sharding.default-data-source-name= #未配置分片规则的表将通过默认数据源定位
spring.shardingsphere.sharding.default-data-source-name=defdb
java测试代码
package com.itheima.sharding;
import com.itheima.sharding.entity.TDict;
import com.itheima.sharding.entity.TOrder;
import com.itheima.sharding.entity.TUser;
import com.itheima.sharding.entity.TbLog;
import com.itheima.sharding.mapper.TDictMapper;
import com.itheima.sharding.mapper.TOrderMapper;
import com.itheima.sharding.mapper.TUserMapper;
import com.itheima.sharding.mapper.TbLogMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.math.BigDecimal;
import java.util.Random;
@SpringBootTest
public class MyTest {
@Autowired
private TbLogMapper tbLogMapper;
/**
* 测试默认数据源
* 对于没有做分片处理的操作,则会直接访问默认数据源处理
*/
@Test
public void test5(){
TbLog log = TbLog.builder().id(2l).info("aaa").build();
tbLogMapper.insert(log);
}
}
运行完查看结果
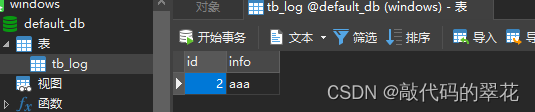



















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











