







redis cluster
呼唤集群:并发量 (10万/s) 数据量 (单机内存不够) 网络流量
解决方式:分布式 (简单的认为加机器)
集群:规模化需求
分布式数据库:数据分区 (顺序分区 哈希分区)
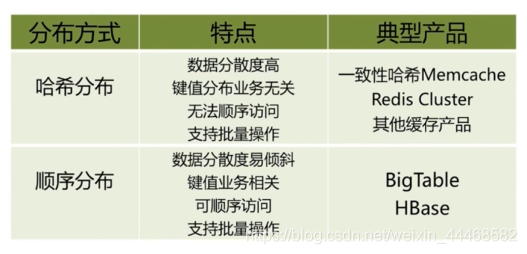
哈希分布:节点取余 一致性哈希 虚拟槽分区
节点取余: 添加一个节点 会造成80%的数据迁移 建议多倍扩容(迁移50)
一致性哈希 哈希环 顺时针决定临近节点 对节点取余的优化 节点伸缩只影响顺时针临近节点
一般情况还是使用翻倍伸缩 保证最小迁移数据的同时能够保证负载均衡
虚拟槽分区 预设虚拟槽 每个槽映射一个数据子集 槽一般比节点数大 良好的哈希函数(CRC16)
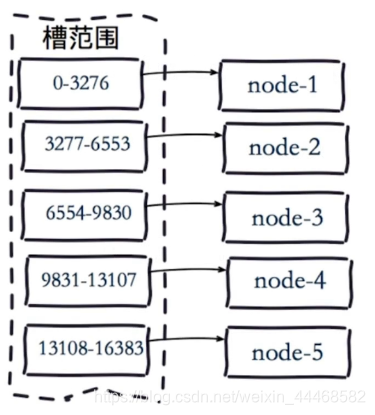
服务端管理服务节点 每个节点知道其他节点负责的槽16383的范围 节点之间通过gossip协议通信 meet操作
cluser enable : yes 开启集群模式
主从复制 高可用
集群搭建
原生命令安装 官方工具ruby安装 redis-cli --cluster 代替redis-trib
-
配置开启节点
cluser enable : yes 开启集群模式
cluster config file
cluster node timeout 15000
cluster require full coverage no 要求集群所有节点正常可用才对外提供服务 正常业务不开启
直接开启后 集群处于下线状态 不能对外提供服务 clusterdown
cluster nodes 查看信息 包括nodeid
2 meet
cluster meet ip port 建立通信
redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7001…7005
3 指派曹
cluster addslots {…}
4 主从分配
cluster replicate node-id
集群伸缩
扩展集群:
加入节点 新加入的节点必须和原来节点配置文件相同
加入集群 使用meet操作加入集群 但是并没有立即开始开始 要等待迁移
迁移槽和数据 reshard host:port
redis-cli --cluster reshard 127.0.0.1:7000
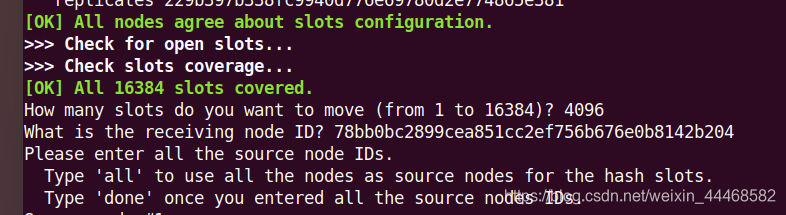
要求分配4096个槽给port7006 的id 并且使用all或者指定nodeid
会从指定槽或全部槽中 分配一部分给新增的节点

收缩机群:
下线迁移槽
redis-cli --cluster reshard --cluster-form {nodeid} --cluster-to{nodeid1} --cluster-slots {nums} ip:port
redis-cli --cluster reshard --cluster-form {nodeid} --cluster-to{nodeid2} --cluster-slots {nums} ip:port
redis-cli --cluster reshard --cluster-form {nodeid} --cluster-to{nodeid3} --cluster-slots {nums} ip:port
忘记节点 并关闭节点
redis-cli --cluster del-node ip:port nodeid 指定ip端口的忘记指定nodeid的节点
先下线主节点 后下线从节点 先下线主节点会触发从节点的故障转移
 使用delnode忘记节点同时会关闭节点
使用delnode忘记节点同时会关闭节点
客户端路由
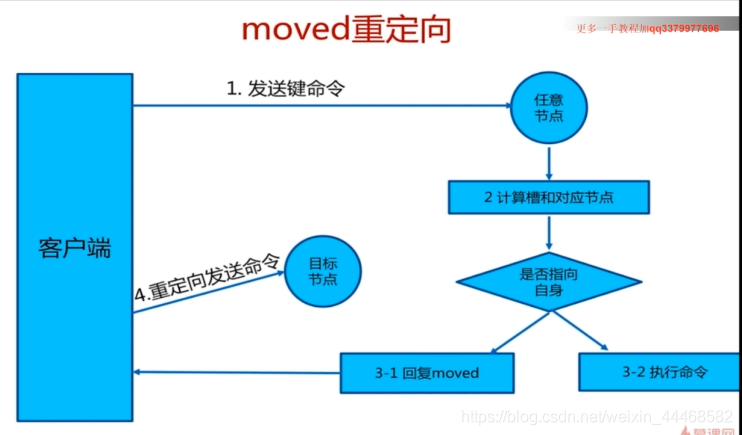
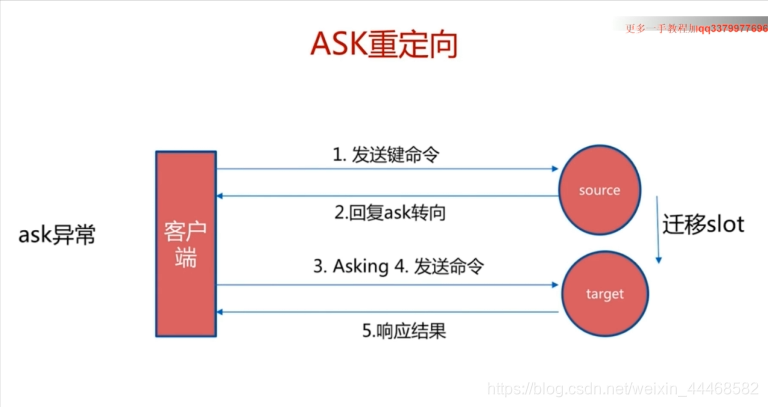
故障转移
故障发现 通过节点之间的ping.pong消息实现故障发现 不需要依赖sentinel
主观下线:某个节点认为另一个节点不可用 与某节点的最后通信时间超过node timeout 标记为pfail状态
客观下线:当半数以上持有槽的主节点都标记某节点主观下线,更新节点为客观下线,向集群广播下线节点的fail消息
节点的ping消息中会包含其他节点的pfail节点信息
故障恢复:
检查资格:每个从节点检查与故障主节点的断线时间,超过timeout(15000ms)*cluster slave validity factor(10)取消资格
偏移量更大的 优先级更高的 更早进行选举 容易获得更多的选票
替换主节点:当前从节点变为主节点 slaveofnoone 撤销故障主节点负责的槽 并分配给自己 向集群广播自己的pong 表示替换成功
redis cluster 常见问题
集群完整性 带宽消耗 pubsub 数据倾斜 请求倾斜 读写分离 数据迁移 集群vs单机
集群完整性: cluster requere full coverage 选项为yes时 集群槽必须全部可用 才对外提供服务
带宽消耗 :官方建议 不要超过一千个节点
pingpong消息 (发送频率(timeout/2) 数据量(槽数据 2KB 和集群1/10的状态数据 (十个节点状态约1KB)) )
PUB/SUB:pub在集群中每个节点广播 加重带宽的消耗 解决:单独布置一套sentinel解决发布订阅
集群倾斜:数据倾斜 请求倾斜
数据倾斜:节点和槽分配不均匀(rebalance) 不同槽对应的键值数量差异较大 包含bigkey 内存配置不一致
请求倾斜:热点key
集群读写分离:集群模式中的从节点不接受任何读写请求 重定向到负责槽的主节点
数据迁移:import 只能从单机迁移到集群 不支持在线迁移 单线程
在线迁移:伪装成source节点的从节点获取数据 完成迁移
集群和单机的对比
key 批量操作支持有限 mget mset必须在一个slot
事务和Lua支持有限 操作的key’必须在一个节点
不支持多个数据库 在集群模式下只有一个db0

















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









