







 本文探讨了缓存带来的加速效果、成本与使用场景,并详细阐述了缓存更新策略、粒度控制、缓存穿透的解决方案,以及无底洞问题、缓存雪崩的优化方法。建议包括使用LRU/LFU/FIFO算法、主动更新和设置超时时间,以及通过布隆过滤器防止穿透。同时,提出了热点key重建的优化策略,包括互斥锁和逻辑过期时间字段。
本文探讨了缓存带来的加速效果、成本与使用场景,并详细阐述了缓存更新策略、粒度控制、缓存穿透的解决方案,以及无底洞问题、缓存雪崩的优化方法。建议包括使用LRU/LFU/FIFO算法、主动更新和设置超时时间,以及通过布隆过滤器防止穿透。同时,提出了热点key重建的优化策略,包括互斥锁和逻辑过期时间字段。
缓存的受益与成本
受益
1、加速读写
2、降低后端负载
成本
1、数据不一致 缓存层和数据层有时间窗口不一致(更新策略)
2、代码维护成本 (多了一层缓存逻辑)
3、运维成本 redis cluster
使用场景
1、高消耗sql 将结果缓存在redis中 降低后端mysql的负载
2、加速请求响应 利用redis、memcache 优化IO的响应时间
3、大量写合并为批量写 如计数器操作 可先在redis中使用incr累加再批量写入DB
缓存的更新策略
为了消除缓存中的数据和真实数据库中的数据存在不一致
更新策略
1、LRU(least recently used)\LFU(frequency)\FIFO 算法 (maxmemory-policy)
2、超时剔除 expire过期数据
3、主动更新 开发控制数据生命周期
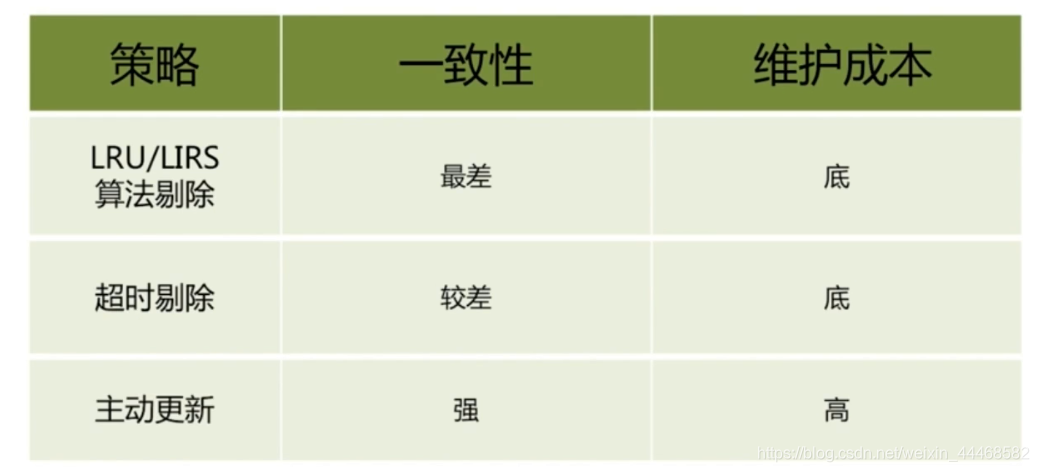
两条建议
1、低一致性:最大内存和淘汰策略
2、高一致性:超时剔除和主动更新结合,最大内存和淘汰策略兜底
缓存粒度控制
在redis中缓存数据库中用户的全量属性还是部分属性的粒度选择
三个角度
1、通用性 缓存全量属性的通用性更高
2、占用空间 部分属性肯定占用的空间更小
3、代码维护
缓存穿透
用户不断对缓存中和数据库中都没有的数据发出请求会导致数据库压力过大。(缓存击穿、缓存雪崩)
原因
恶意攻击
业务代码自身问题
发现
业务的响应时间
业务本身问题
相关指标:总调用数,缓存层命中数,存储层命中数
解决方案
1、缓存空对象并设置超时时间
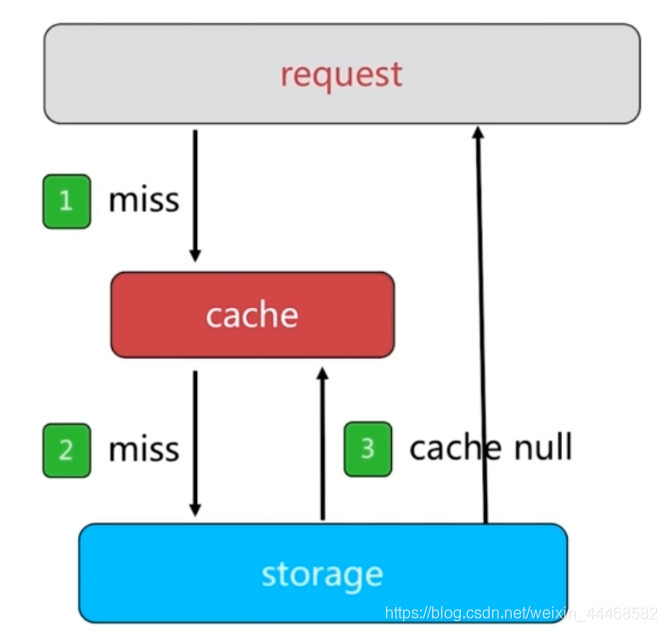
两个问题
1、可能造成大量空的键
2、缓存层和存储层的数据会出现短期的不一致(业务故障返回空并缓存后业务恢复)
2、布隆过滤器拦截
无底洞问题优化
增加机器与节点 服务端性能并没有获得对应提升反而性能下降(更多的机器 != 更高的性能)
优化IO的几种方法:
1、命令本身的优化
2、减少网络通信次数
3、降低接入成本 (客户端长连接、连接池、NIO)
从网络IO时间进行优化:
1、串行mget
2、串行IO
3、并行IO
4、hash_tag

缓存雪崩优化
缓存中的数据大批量到过期时间,查询数据巨大在缓存中查不到从而去数据库中查找,引起数据库压力过大
(缓存击穿是一条数据到期后并发用户大批量去数据库读取,缓存雪崩是大批量数据到期)
解决方案
1、保证缓存层服务的高可用性
2、客户端降级
3、提前演练
热点key重建优化
热点key在重建过程中会有大量访问请求
三个目标:
减少重建缓存的次数
数据尽可能保持一致性
减少潜在风险 死锁
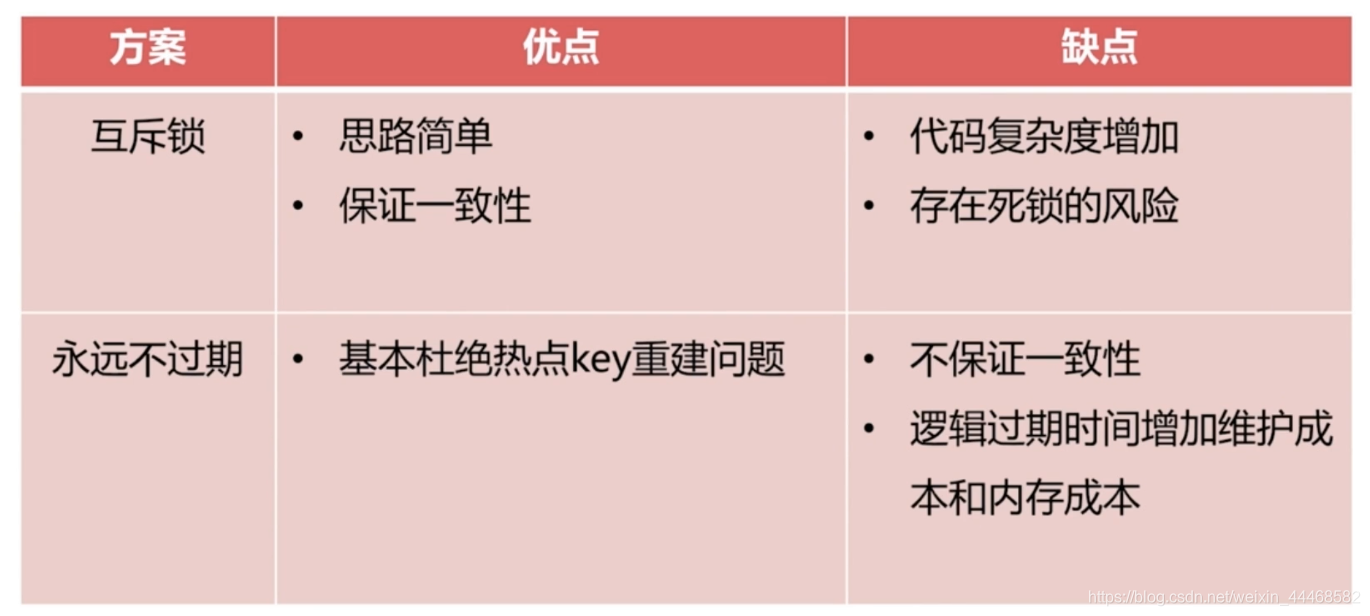
两个解决:
1、添加互斥锁
2、设置永远不过期但增加逻辑过期时间字段


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









