






生产需求:
生产环境中kafka集群机器满了五年(或者更久)之后,服务器到达了寿命需要替换。将用了超过五年的服务进行下线处理。
方案一:使用kafka-reassign-partitions.sh重分配指令。但缺点是导致再topic充分配的时候导致生产和消费端产生异常,所以不采用。
方案二:先扩副本(之前已经做了扩集群,可以将下线的机器上的topic全部迁移到扩的集群中),再下线机器,再所副本,这样对生产和消费端做到无感知。所以采用方案二。
本篇文章详细讲解方案二的策略:
topic-lists.txt : 该文件是用来填写需要迁移的主题名称,主要有两种模式:
1、值为all,代表对集群中所有的主题执行迁移操作,但是脚本里面会判断,当主题中所有的副本都不在下线节点中的话,则不会进行迁移
2、值为主题名,每个主题占一行,对指定主题进行迁移
topic-replica-change.sh :该脚本是主脚本,主要有3个参数
参数1: 有两种类型的值,Add和Del,其中add代表在现有副本中扩副本,所扩副本数为所有分区的副本中,某个分区的副本在下线节点中个数最多的即为该主题所扩副本数;del代表删除副本中broker id为下线节点的broker对应的副本
参数2:所有非下线节点的broker id,用逗号分割
参数3:下线节点的broker id,用逗号分割
/bin/bash topic-replica-change.sh Add 0,1,2 3 #这是扩容调用的脚本
/bin/bash topic-replica-change.sh Del 0,1,2 3 #这是缩容调用的脚本
扩容脚本执行过程中产生的文件:
主题名.txt : 主题扩容前对应的describe信息
主题名-to-move-add.json : 主题副本扩容生成的对应的执行计划
move-result.txt : 主题副本重分配结果
缩容脚本执行过程中产生的文件:
【注意】下线缩容,为避免迁移过程中leader切换影响业务,必须采用先下线节点,后进行缩容操作
主题名.txt : 主题缩容前对应的describe信息
主题名-to-move-del.json : 主题副本缩容生成的对应的执行计划
move-result.txt : 主题副本重分配结果
topic-lists.txt
1、值为all,代表对集群中所有的主题执行迁移操作,但是脚本里面会判断,当主题中所有的副本都不在下线节点中的话,则不会进行迁移
2、值为主题名,每个主题占一行,对指定主题进行迁移
all
topic-replica-change.sh
#!/bin/sh
SHELL_NAME=$(echo $0)
SHELLDIR=$(cd $(dirname $0);echo $(pwd);cd - >/dev/null)
TOPIC_FILE=${SHELLDIR}/topic-lists.txt
ZK_URL="localhost:2181/kafka"
KAFKA_DIR="/home/software/kafka_2.11-0.11.0.0/bin"
TOPIC_LIST="${KAFKA_DIR}/kafka-topics.sh --zookeeper ${ZK_URL} --list"
TOPIC_DESCRIBE="${KAFKA_DIR}/kafka-topics.sh --zookeeper ${ZK_URL} --describe --topic "
REASSIGN_EXECUTE="${KAFKA_DIR}/kafka-reassign-partitions.sh --zookeeper ${ZK_URL} --execute --reassignment-json-file "
REASSIGN_VERIFY="${KAFKA_DIR}/kafka-reassign-partitions.sh --zookeeper ${ZK_URL} --verify --reassignment-json-file "
OPERATION=$1
ONLINE_BROKER=$2
OFFLINE_BROKER=$3
echo $SHELL_NAME
echo $SHELLDIR
echo $ONLINE_BROKER
echo $OFFLINE_BROKER
usage() {
cat << EOF
Usage: /bin/bash ${SHELL_NAME} [-degv] argument
示例如下:
扩容调用的脚本:/bin/bash topic-replica-change.sh Add 10000,10001 10002 60 #扩容调用的脚本
缩容调用的脚本:/bin/bash topic-replica-change.sh Del 10000,10001 10002 60 #这是缩容调用的脚本
参数1: 有两种类型的值,Add和Del
Add代表在现有副本中扩副本,所扩副本数为所有分区的副本中,某个分区的副本在下线节点中个数最多的即为该主题所扩副本数;
Del代表删除副本中broker id为下线节点的broker对应的副本。
参数2:所有非下线节点的broker id,用逗号分割
参数3:下线节点的broker id,用逗号分割
EOF
}
verify_plan(){
local topic=$1
move_res=`${REASSIGN_VERIFY}${topic}"-to-move-${OPERATION}.json" | grep "in progress" | wc -l`
while [[ ${move_res} -ne 0 ]] ;do
sleep 5s
echo -e " ${topic} reassignment is still in progress,please wait!\n ${move_res} partitions is still in progress\n"
verify_plan $topic
done
}
execute_plan(){
local topic=$1
echo "start execute plan of ${topic}-to-move-${OPERATION}.json"
${REASSIGN_EXECUTE}${topic}"-to-move-${OPERATION}.json"
if [ $? -eq 0 ]; then
echo "success execute plan of $topic"
verify_plan $topic
echo "${topic} move success,operation is ${OPERATION}" | tee -a move-result.txt
else
echo "execute plan of $topic failed"
fi
}
#get topic lists
get_topic_lists(){
topic_lists=`${TOPIC_LIST}`
for topic in $topic_lists
do
#过滤掉__consumer_offsets主题名字的topic,这个topic是记录消费者的offset的
if [ $topic != "__consumer_offsets" ]; then
#-e 参数是激活转义字符 \n换行
echo -e "\n${topic}"
process_topic $topic
fi
done
}
process_topic(){
local countNoLeader=0
local countReplicasIsrNoEqual=0
local countLteOneBak=0
local topic=$1
echo "Beginning check Topic=${topic} Status:"
line="${TOPIC_DESCRIBE}${topic}"
countNoLeader=`${line} | egrep "\-1|none" |wc -l`
echo "${topic}的分区中没有leader的个数为${countNoLeader}"
countLteOneBak=`${line}| grep "ReplicationFactor" | awk '{match($0,/ReplicationFactor:([^[:blank:]]*)/,arr);print arr[1]}'`
echo "${topic}的副本个数为${countLteOneBak}"
num=`${line} | grep -o "Topic" | wc -l`
echo "${topic}的分区个数为${num}"
NUMOFFLINE=`echo ${OFFLINE_BROKER}|grep -o ","|wc -l`
echo $(${line}|grep "Leader:"| awk '{match($0,/Replicas: ([^[:blank:]]*).*Isr: ([^[:blank:]]*)/,arr);print arr[1],arr[2]}')
while read -r LINE ;do
[[ "${OPERATION}" == "Add" ]] && [ $(echo ${LINE} | awk '{print $1}' | grep -o "," | wc -l) -ne $(echo ${LINE} | awk '{print $2}' |grep -o ","|wc -l) ] && ((countReplicasIsrNoEqual++));
[[ "${OPERATION}" == "Del" ]] && [ $(echo ${LINE} | awk '{print $1}' | grep -o "," | wc -l) -ne $(($(echo ${LINE} | awk '{print $2}' |grep -o ","|wc -l) + ${NUMOFFLINE} + 1 )) ] && ((countReplicasIsrNoEqual++));
done < <( ${line}|grep "Leader:"| awk '{match($0,/Replicas: ([^[:blank:]]*).*Isr: ([^[:blank:]]*)/,arr);print arr[1],arr[2]}' )
if [ "${countNoLeader}" -ne 0 ] || [[ "${countReplicasIsrNoEqual}" -ne 0 ]] || [ "1${countLteOneBak}" -eq "11" ] || [ "${num}" -lt 1 ] ; then
echo "Topics has ExceptionStatus!"
else
echo "start process $topic"
rm -rf "${topic}.txt"
rm -rf "${topic}-to-move-${OPERATION}.json"
echo `${line}`|sed '#\n##g' | tee -a "${topic}.txt"
generate_plan ${topic}
fi
}
generate_plan(){
#在函数内定义局部变量。
local topic=$1
echo "start generate plan of $topic"
#执行python脚本
python ${SHELLDIR}/topicReplica${OPERATION}.py $topic $ONLINE_BROKER $OFFLINE_BROKER
echo ${SHELLDIR}/topicReplica${OPERATION}.py
if [ ! -f "${topic}-to-move-${OPERATION}.json" ]; then
echo "generate plan of $topic failed"
else
echo "success generate plan of $topic,plan file is ${topic}-to-move-${OPERATION}.json"
execute_plan $topic
fi
}
function doWork(){
#遍历文件中所有topics
while read -r LINE ;do
echo "topic=${LINE}"
process_topic ${LINE}
done < $TOPIC_FILE
}
main(){
#- z 如果参数ONLINE_BROKER为空,或
#-s "$TOPIC_FILE"如果文件存在且非空
if [ -z "${ONLINE_BROKER}" ] || [ ! -s "$TOPIC_FILE" ];then
echo "Please check params or $TOPIC_FILE "
usage
exit
elif [ $(grep -c "^all$" $TOPIC_FILE) -gt 0 ] ;then
echo "start process all topic"
get_topic_lists
else
case ${OPERATION} in
-h)
usage
exit 1
;;
Add)
doWork
exit 1
;;
Del)
doWork
exit 1
;;
*)
echo -e "input error\n"
usage
exit 1
;;
esac
fi
}
main
topicReplicaAdd.py
# coding:utf-8
import sys
import customlog as logger
import json
from random import randint
def get_str_btw(s, f, b):
par = s.partition(f)
return (par[2].partition(b))[0][:]
def read_topic_info(topic):
path = "./" + topic + ".txt"
with open(path, 'r') as f:
info = f.readline()
print("info" + info)
partition_infos = info.split("Configs:")[1].split("Topic")
topic_dic = {}
for line in partition_infos:
partition = get_str_btw(line, "Partition:", "Leader:").strip()
replicas = get_str_btw(line, "Replicas:", "Isr:").strip().split(",")
if partition != '':
topic_dic[partition] = replicas
return topic_dic
def get_max_replica(offline_broker, curr_relica):
replica = [ i for i in offline_broker if i in curr_relica]
return len(replica)
def get_usefull_broker(b1, b2):
return [i for i in b1 if i not in b2]
def add_new_replicas(b1, b2, replica_str, num):
usefull_online = get_usefull_broker(b1, b2)
if len(usefull_online) == 0:
logger.error("没有多余节点用来扩副本")
sys.exit(1)
used_lists = []
for k in range(0, num):
while True:
random_index = randint(0, len(usefull_online)-1)
if random_index not in used_lists:
replica_str = replica_str + "," + usefull_online[random_index]
used_lists.append(random_index)
break
return replica_str
def write_to_json(filepath,txt):
with open(filepath,"w") as f:
f.write(txt)
def get_new_replicas(topic_name, partition_replica, new_replica_num, online_broker, offline_broker):
pars = len(partition_replica)
js_str = """{"version":1,"partitions":["""
for x in range(0, pars):
replica_info = partition_replica[str(x)]
print(replica_info)
off_num = get_max_replica(offline_broker, replica_info)
on_num = new_replica_num - off_num
replica_news = ','.join(replica_info)
if off_num != 0:
replica_news = add_new_replicas(online_broker, replica_info, replica_news, off_num)
if on_num != 0:
replica_news = add_new_replicas(offline_broker, replica_info, replica_news, on_num)
partition_str = """{"topic": "%s", "partition": %s,"replicas": [%s]}""" % (topic ,x ,replica_news)
if x == pars -1:
js_str = js_str + partition_str+"]}"
else:
js_str = js_str + partition_str+","
write_to_json("./"+topic_name+"-to-move-Add.json",js_str)
if __name__ == '__main__':
topic = sys.argv[1]
print(topic+"topic")
onlineBroker = sys.argv[2].split(",")
offlineBroker = sys.argv[3].split(",")
res = read_topic_info(topic)
print("============================")
partitions = len(res)
# 获得主题新增最大副本数
max_replica = 0
for i in range(0, partitions):
max_middle = get_max_replica(offlineBroker, res[str(i)])
if max_replica < max_middle:
max_replica = max_middle
print("####################")
print(max_replica)
if max_replica == 0:
logger.info("当前主题%s所有分区副本都不在下线节点上,故不需要迁移!" % topic)
sys.exit(1)
get_new_replicas(topic, res, max_replica, onlineBroker, offlineBroker)
topicReplicaDel.py
# coding:utf-8
import sys
import customlog as logger
import json
from random import randint
def get_str_btw(s, f, b):
par = s.partition(f)
return (par[2].partition(b))[0][:]
def write_to_json(filepath,txt):
with open(filepath,"w") as f:
f.write(txt)
def read_topic_info(topic):
path = "./" + topic + ".txt"
with open(path, 'r') as f:
info = f.readline()
if len(info) == 0:
logger.info("主题%s信息文件对应的内容为空,请排查!" % topic)
exit(1)
# info.split()
partition_infos = info.split("Configs:")[1].split("Topic")
topic_dic = {}
for line in partition_infos:
partition = get_str_btw(line, "Partition:", "Leader:").strip()
replicas = get_str_btw(line, "Replicas:", "Isr:").strip().split(",")
if partition != '':
topic_dic[partition] = replicas
return topic_dic
def get_new_replicas(topic_name, partition_replica,offline_broker):
pars = len(partition_replica)
js_str = """{"version":1,"partitions":["""
flag= "false"
for i in range(0, pars):
replica_info = partition_replica[str(i)]
new_replica = []
for broker in replica_info:
if broker not in offline_broker:
new_replica.append(broker)
else:
falg = "true"
partition_str = """{"topic": "%s", "partition": %s,"replicas": [%s]}""" % (topic, i, ','.join(new_replica))
if i == pars -1:
js_str = js_str + partition_str+"]}"
else:
js_str = js_str + partition_str+","
if flag == "true":
logger.warn("该主题%s对应的所有副本都不在下线节点中,故不需要迁移!" % topic_name)
sys.exit(1)
write_to_json("./"+topic_name+"-to-move-Del.json", js_str)
if __name__ == "__main__":
topic = sys.argv[1]
offlineBroker = sys.argv[3].split(",")
res = read_topic_info(topic)
get_new_replicas(topic,res,offlineBroker)
customlog.py
这个文件是将日志打印到installlog中,这个目录在执行脚本的上一个目录。
import os
import datetime
log_path = '%s/../installlog' % os.path.dirname(__file__)
if not os.path.exists(log_path):
os.mkdir(log_path)
log_file = '%s/install.log' % log_path
def info(msg):
log(msg, 'INFO')
def warn(msg):
log(msg, 'WARN')
def error(msg):
log(msg, 'ERROR')
def log(msg, level):
log_msg = '%s %s: %s' % (datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), level, msg)
print(log_msg)
with open(log_file, 'a') as f:
f.write('%s\n' % log_msg)
测试过程展示
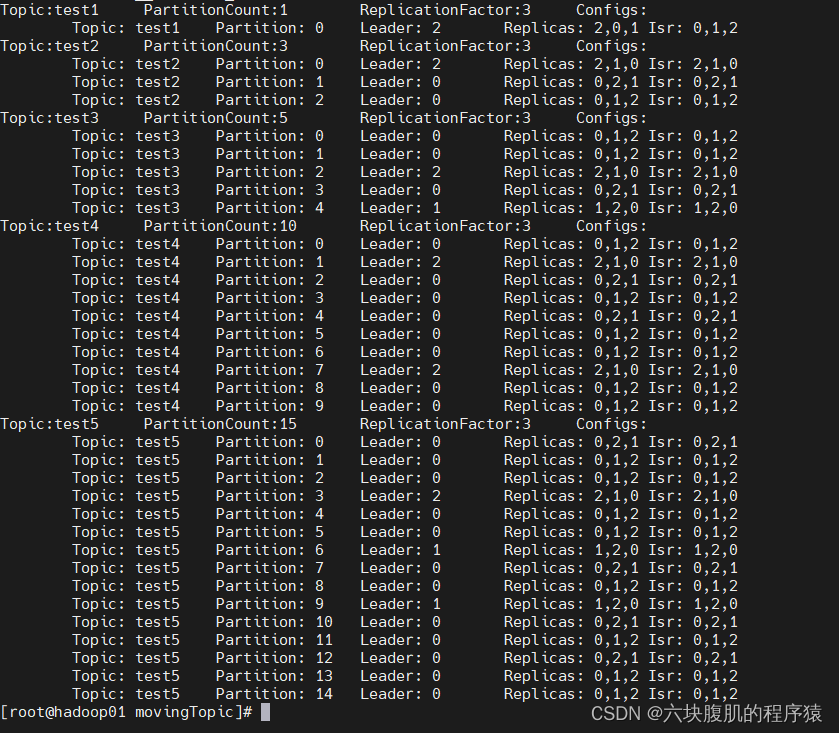
1.观察跑扩容脚本前所有topic的分区和副本分布情况:
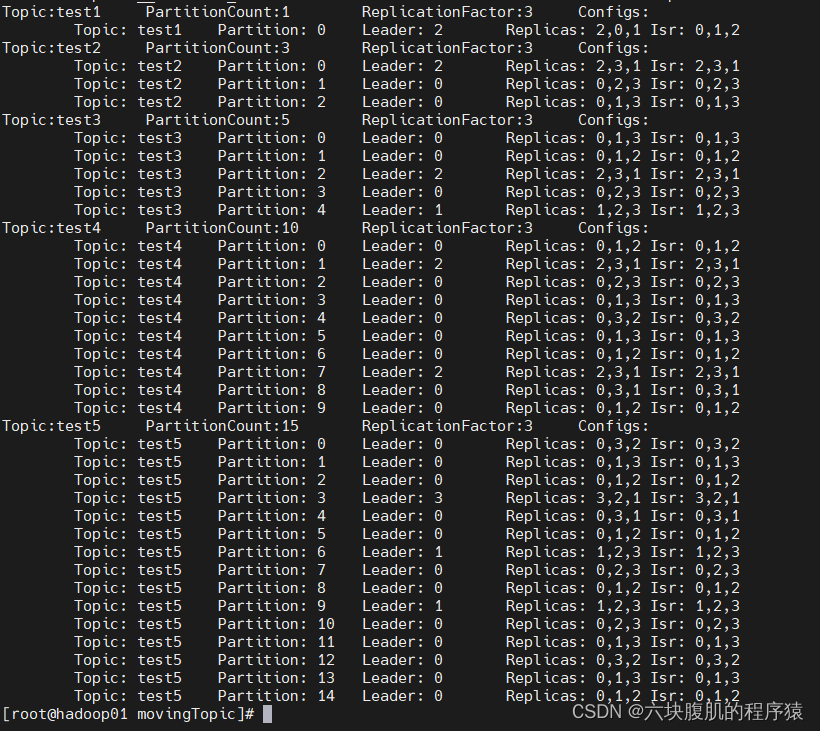
2.执行扩容脚本:/bin/bash topic-replica-change.sh Add 0,1,2 3
3.观察跑扩容脚本后所有topic的分区和副本分布情况
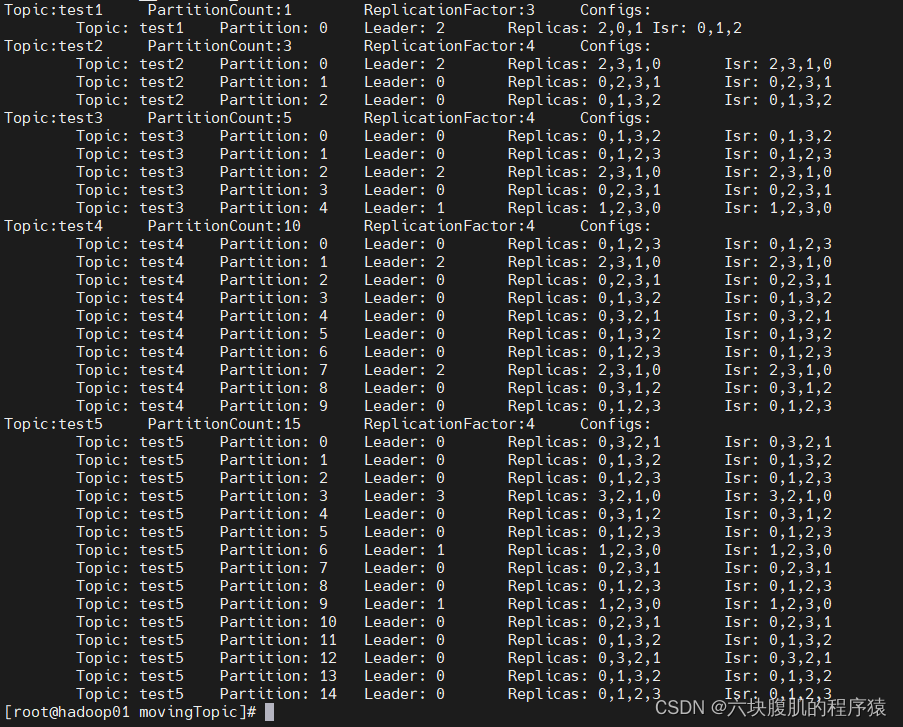
4.下线borkerId=3的机器
5.观察下线机器后所有topic的分区和副本分布情况
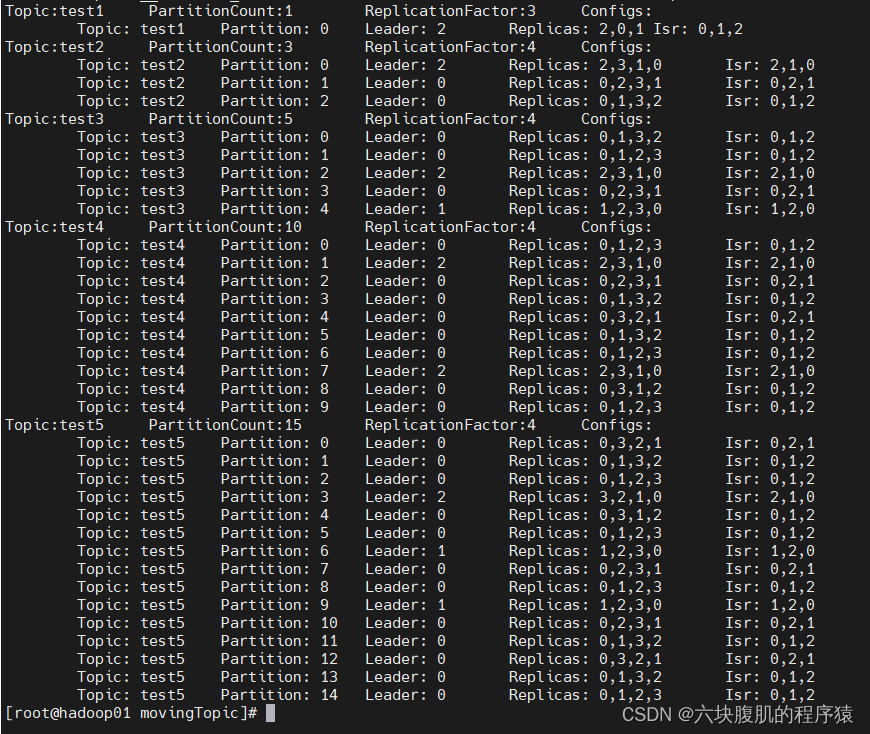
6.执行缩容脚本:/bin/bash topic-replica-change.sh Del 0,1,2 3
7.观察跑缩容脚本后所有topic的分区和副本分布情况
此功能在正常吞吐量写入过程中,也不会影响集群的稳定性,也进行压力测试过。
工具脚本:
如果在测试环境有多个topic(几十几百个),可以用以下脚本将3副本以上的脚本恢复成3副本。
ReducedReplication2three.sh
#!/bin/bash
shopt -s expand_aliases
source /etc/profile
SHELLDIR=$(cd $(dirname $0);echo $(pwd);cd - >/dev/null)
ZKURL="localhost:2181/kafka"
TOPICSDESCRIBE="kafka-topics.sh --zookeeper ${ZKURL} --describe --topic"
LOGFILE="${SHELLDIR}/topics-to-move.json"
alias log='tee -a ${LOGFILE}'
kafka-topics.sh --zookeeper ${ZKURL} --describe |grep "ReplicationFactor"|awk -F '[:\t]' '{if($6>3) print $2}' >${SHELLDIR}/kafka_list.txt
echo '{"version":1,"partitions": ['>${SHELLDIR}/topics-to-move.json
for replicas in `cat ${SHELLDIR}/kafka_list.txt`
do
echo ${replicas}
( ${TOPICSDESCRIBE} ${replicas} | grep -v "^Topic" | awk '{match($0,/Topic: ([^[:blank:]]*).*Partition: ([^ ]*).*Leader: ([^ ]*).*Replicas: ([^ ]*).*Isr: ([^[:blank:]]*)/,arr); print "{\"topic\": \""arr[1]"\", \"partition\": "int(arr[2])", \"replicas\": ["substr(arr[5],1,5)"]},"}' ) |log
done
sed -i ':lable;N;s/\n//;b lable' ${SHELLDIR}/topics-to-move.json
sed -i -e '$s/,$/]}/' ${SHELLDIR}/topics-to-move.json
sh /home/software/kafka_2.11-0.11.0.0/bin/kafka-reassign-partitions.sh --zookeeper localhost:2181/kafka --execute --reassignment-json-file /home/sc/suofuben/topics-to-move.json
注意:1.文中/home/software/kafka_2.11-0.11.0.0/bin/修改成自己的kafka的bin目录。
2.substr(arr[5],1,5)这个需要根据自己broker的长度进行切割。(原理是切割前面3个brokerId的长度)


















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









