






1、持久化方案:
RDB: 跟快照差不多,占空间小,容易丢数据,二进制文件,默认开启
AOF:每次更新插入数据就会把数据记录到aof文件当中,需要手动开启,还有个重写机制,达到某个条件,会优化语句,比如将重复语句整合
最优方案:两个结合,rdb容易丢的数据用aof写上,命令:# aof-use-rdb-preamble yes
两个结合前提是aof先打开:appendonly yes;修改配置文件的信息打开aof
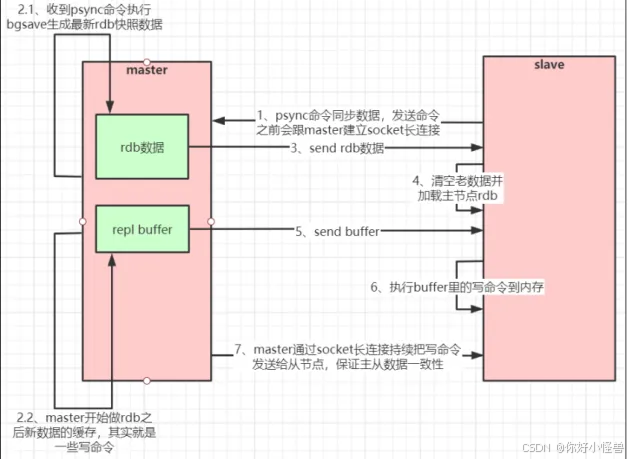
主从复制流程图:
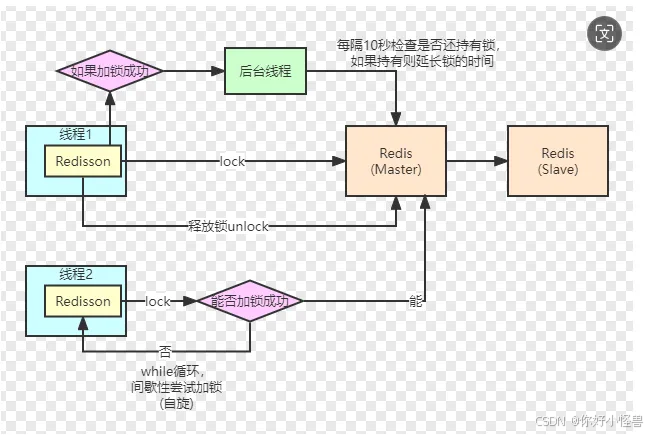
2、redission分布式锁方案:
1、setnx方法,简单,适合并发小的业务功能,小公司适合
2、redission分布式锁,看门狗机制。(可以配合使用可重入锁)
3、redis过期的key淘汰策略:
1.定期淘汰:定期淘汰过期的key
2.懒惰淘汰:读到/或写到一个过期的key才去删除
3.设置固定内存大小,超过就进行主动删除算法
算法:1.LRU:淘汰最近过期的key
2.LFU:淘汰最近使用次数最少的key
4、redis重要命令:
keys:全量遍历键 : keys *,避免在很多key中用,查询慢
scan:渐进式遍历键 :SCAN cursor [MATCH pattern] [COUNT count]
Info:查看redis服务运行信息,分为 9 大块,每个块都有非常多的参数,这 9 个块分别是:
- Server 服务器运行的环境参数
- Clients 客户端相关信息
- Memory 服务器运行内存统计数据
- Persistence持久化信息
- Stats 通用统计数据
- Replication 主从复制相关信息
- CPU CPU 使用情况
- Cluster集群信息
- KeySpace 键值对统计数量信息
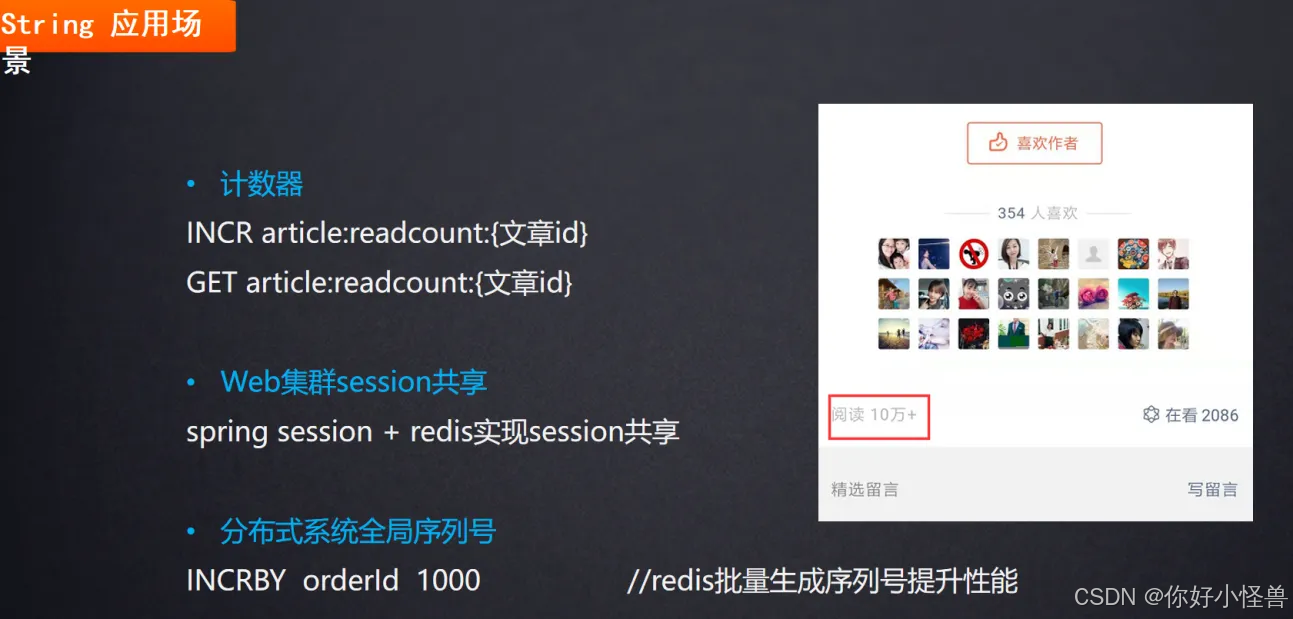
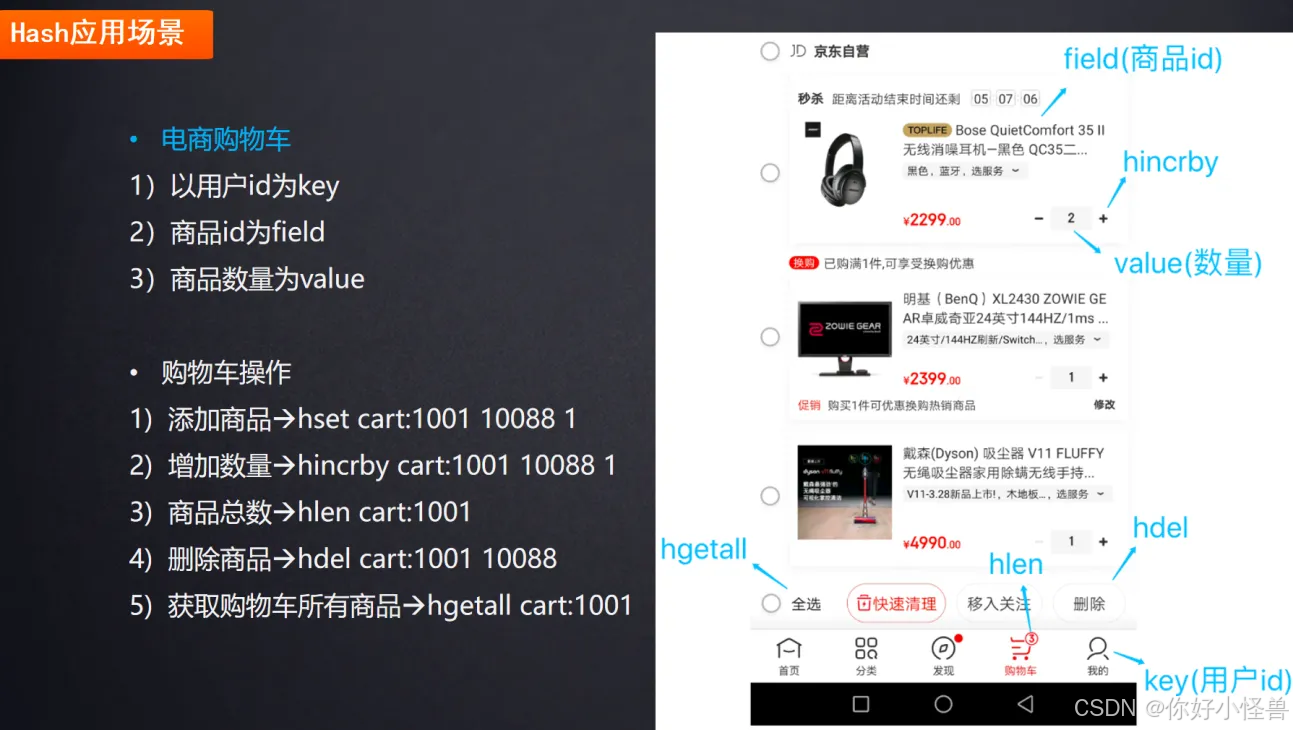
5、数据类型应用场景
1.string:计数器
2.hash:购物车(id:用户id,field:商品id,value:数量),注意不要把商品信息算进来,商品信息需要另外开一个新的key,或者用其他数据结构
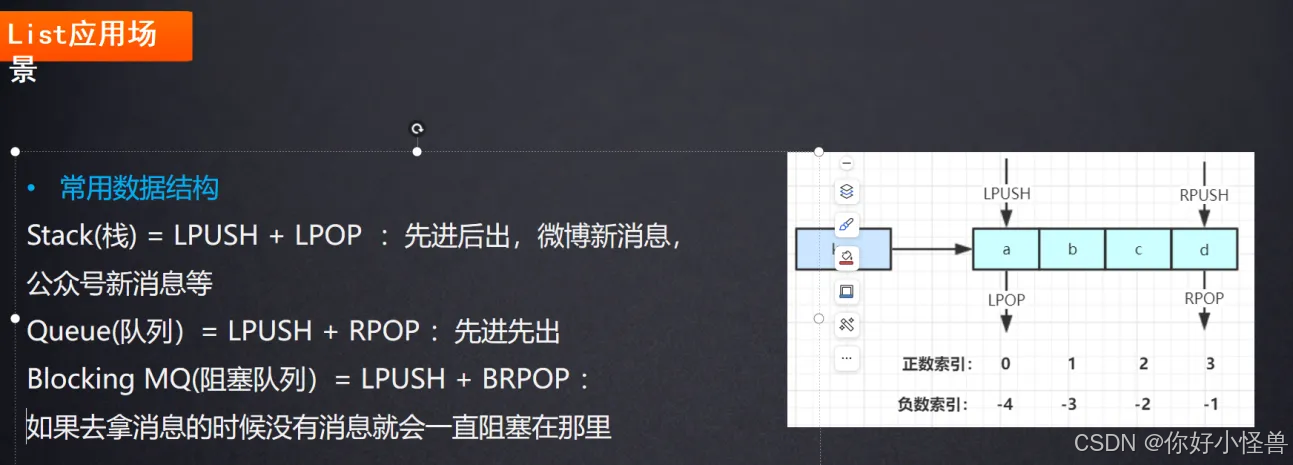
3.list:消息队列,比如公众号首页的信息,一般是先进后出(最开始的消息会被新来的消息挤到后面去),各种消息列表
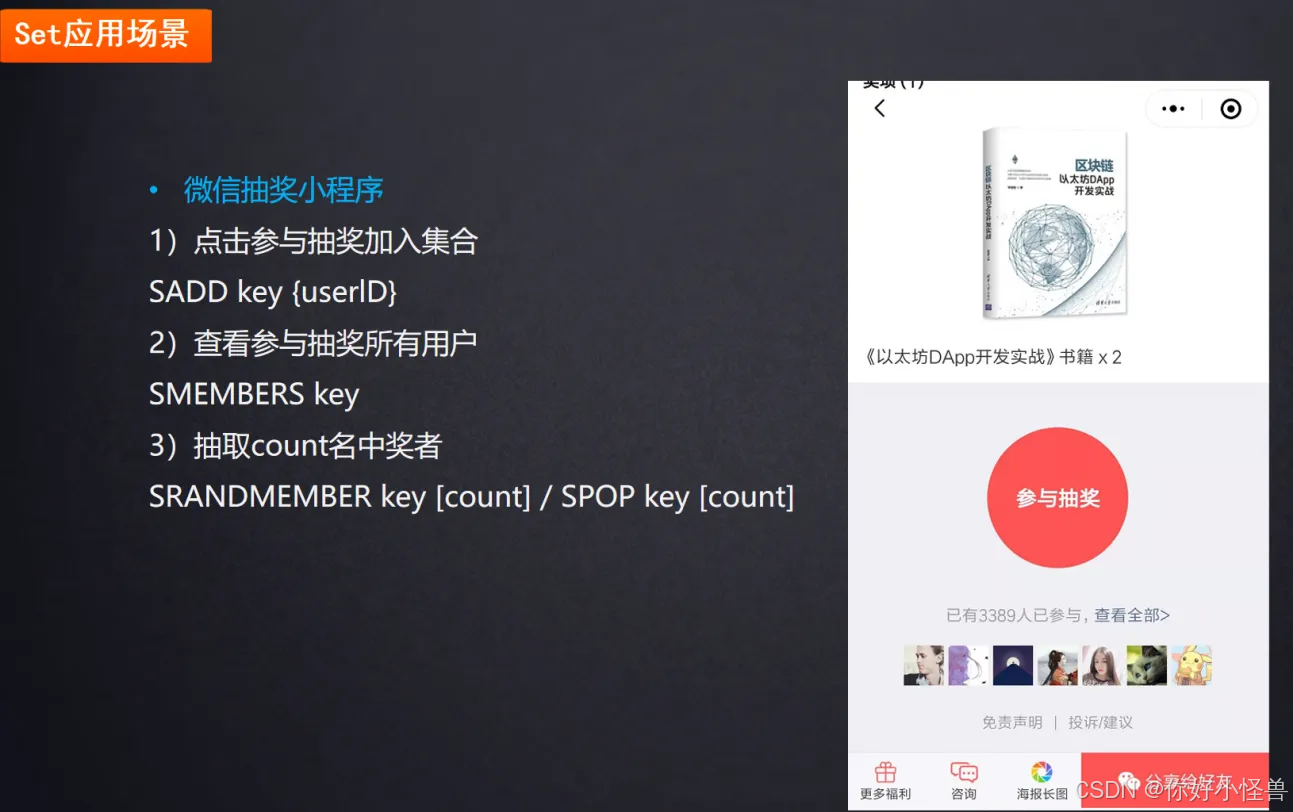
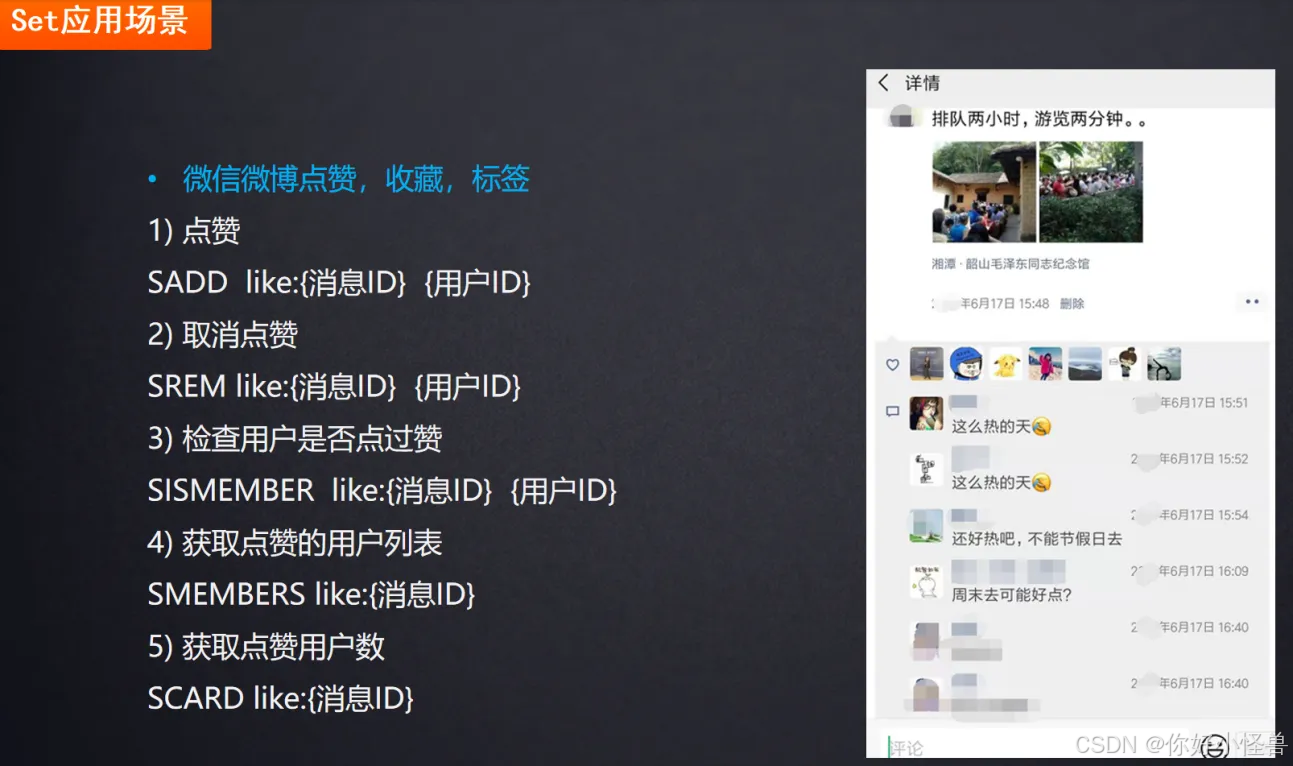
4.set:抽奖名单(不可重复)
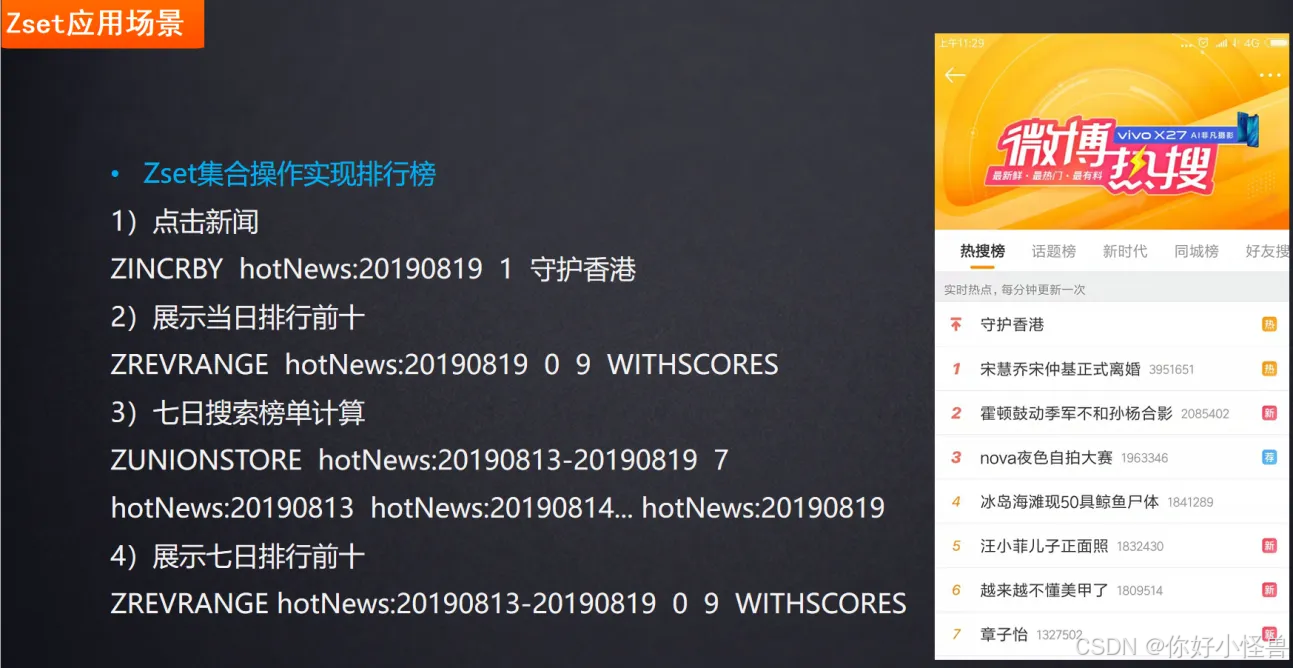
5.zset:排行榜
6、StringRedisTemplate
StringRedisTemplate默认采用的是String的序列化策略,保存的key和value都是采用此策略序列化保存 的。 (可见性比较好)
RedisTemplate默认采用的是JDK的序列化策略,保存的key和value都是采用此策略序列化保存的。(一般看不到结构)
7.集群节点
Redis Cluster 将所有数据划分为 16384 个 slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每 个节点中。
8、集群选举和哨兵选举是同级的两种方案,但是类似。
假设一主两从,有三个集群,这样A主挂了,A从1和A从2会发信息给B主C主,看谁先的到回复超过半数就能成为新A主
机制:先收到谁的消息就会先回复谁,因此发消息的时间快慢是关键,发消息的速度有一个公式:•延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
•SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方 式下,持有最新数据的slave将会首先发起选举(理论上)。
9、布隆过滤器:
布隆过滤器能保存上亿个数据只占用几个mb,因为一个数据占三个位置(8个位置才是一个字节b),且位置为1。1mb=1024*1024b,(有的不一定有(hash冲突),没有的一定没)
10、如何快速查找特定的key scan key user* ;这个命令可以分页查询前缀为user的相关key
11、redis事务命令:

12、redis如何保证与数据库一致性:
方案有很多,没有最优解,通常用延迟双删
13、过期时间设置相关
在 Redis 中,数据的默认过期时间是没有设置的,因此只要不调用 expire 或 set 方法来设置过期时间,数据就会永不过期。
如果你想明确地设置一个键的过期时间,可以使用 redisTemplate.expire(key, timeout, TimeUnit.SECONDS) 方法,但如果你不调用这个方法,数据就会保持永久有效。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









