






“串”只是线性表的一种特殊的应用,指的就是线性存储的一组数据
(通常教科书里面提到的串默认是“字符串”,也就是说这组数据是 字符 )
串有一些特殊的操作集:
- 求串的长度,Length(S)
- 比两串是否相等,StrCompare(S,T)
- 两串相接,Concat(&T,S1,S2)
- 求子串,StrAssign(&T,chars)
- 插入子串,StrInsert(&S,pos,len)
- 匹配子串,Index(S,T,pos)
- 删除子串,StrDelete(&S,pos,len)
其中匹配子串是稍微有点难度的且比较有趣的操作,现在来讨论一下串的模式匹配
目标

总结来说,模式匹配就是:给定一个文本,给定一个模式,我们要通过这个Patternmatch这个函数来返回pattern在这个string里面出现的第一个位置。
简单实现
- strstr
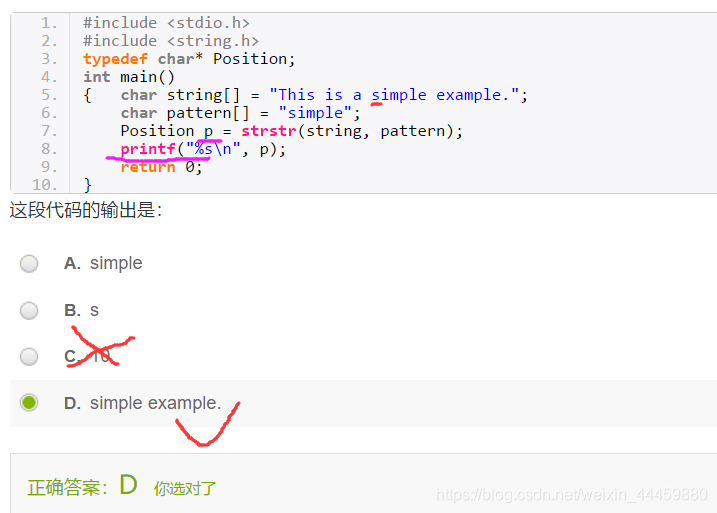
解释:
typedef char* Position // 把这个char*重命名一下
#define NotFound NULL//同理
优点:不管懂不懂C语言的人都能知道是什么意思…
①匹配得上时,p指针指向出现simple的那个s的位置,也意味着是simple example这个子串的头指针。所以printf去打印的时候,就直接把s后面的整个打印出来,输出结果就是答案D
②匹配不上的情况,这个p就是个空指针,null 。输出结果如图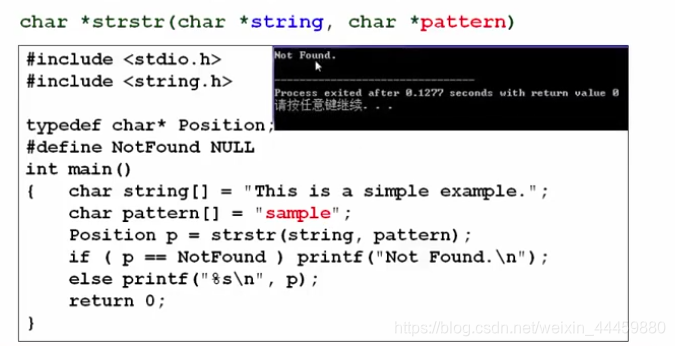


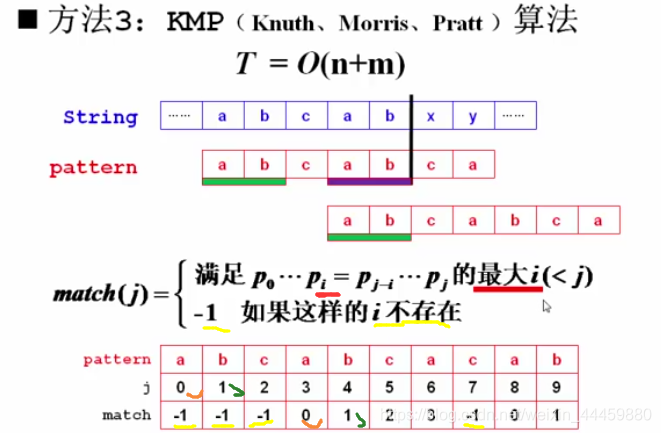
如果 match[j] 的值不是满足子序列条件的“最大”i,会出现什么问题?
——降低匹配效率,时间复杂度增加.
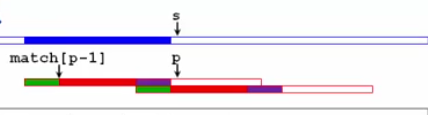
将p回溯到match[p-1]+1的位置(在此期间s是不动的)
// 即 图中绿色模式匹配的下一个位置,然后s和p继续向前走下去
Details:当p等于0的时候,会得到一个段错误,说明这pattern从第一个字符开始就和string不匹配,所以p是不用动的,让s前移一格就OK了//即所给的else s++
两个指针一起向前飞,任意一方飞到自己串的末尾时,这个匹配就结束了~(while)
KMP算法的 时间复杂度
讨论:原始的 KMP 函数返回的是模式在文本中的首字母下标,这使我们不得不改变结果输出的格式 。如果我们希望在调用了Position p = KMP(string, pattern);之后,仍然用printf("%s\n", p); 输出,该怎样修改 KMP 函数?
——修改返回类型 typedef char * position
修改返回值 return (p==m) ?string +(s-m):Not found
上面出现了BuildMatch用来获得match的值
现在来讨论一下BuildMatch的实现
先分析一下~
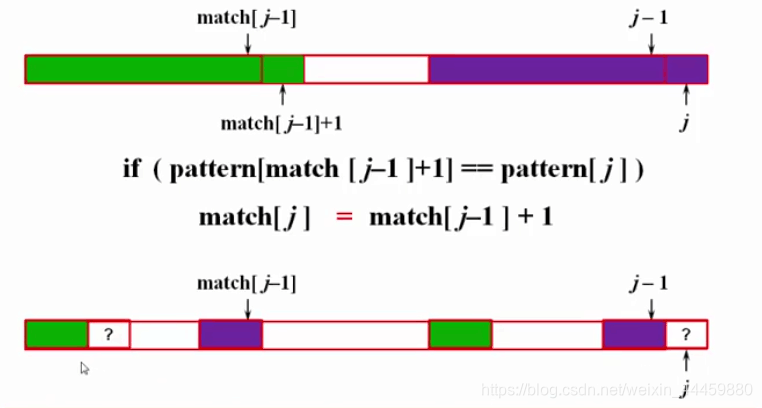
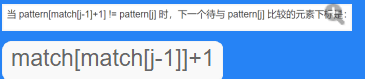
BuildMatch完整表示方法:

它的时间复杂度O(m)

本章重点是掌握KMP算法的匹配过程哦!!
稍微有点绕,多用演草纸写一下

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









