






1 词典文件介绍
前面建立的词典,只有两个单词,现在我们要建立一个上万个单词的词典,所有单词及其翻译都在一个名为dict.txt的文件(词典文件)中
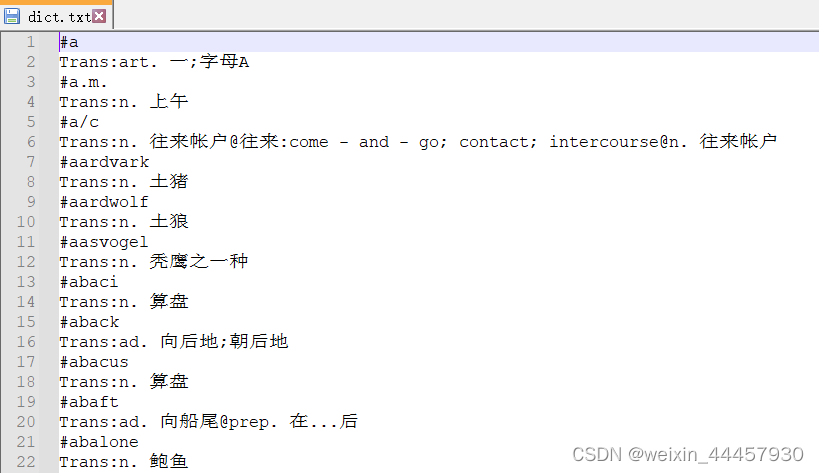
每个单词有两行,其中一行是单词原文,下一行是对应的翻译
这个文件共有20多万行,也就是说,共有10多万个单词,但看一下文件的末尾,可以发现后面的单词是中文,对应的翻译是英文,也就是说,这个文件即包含了英译中,也包含了中译英。

2 打开文件的函数与结构体定义
因为需要多次打开文件,因此可以将其封装成函数
# define FILE_PATH "./dict.txt"
FILE* open(char * file_path)
{
FILE* fp = fopen(file_path, "r");
if (!fp)
{
perror("open");
exit(0);
}
return fp;
}
这个函数过于简单,因此不进行测试。
我们这次要建立的词典,既能英译中,也能中译英,那么就需要修改结构体定义
typedef struct _dict
{
char *key;
char *content;
}Dict;
3 词典文件的行数统计
dict.txt的行数决定了需要有多大的空间存储词典,这里词典文件有222204行,我们可以使用宏定义来写死行数
#define LINE_NUM 222204
但如果哪天在dict.txt文件中增加了两个单词,就必须修改代码了。
我们希望能够程序能够自动地获得文件的行数,那么这里可以写一个函数实现
int line_number()
{
FILE* fp = open(FILE_PATH);
int i = 0;
char temp[128];
while (1)
{
fgets(temp, sizeof(temp), fp);
if (feof(fp))
{
fclose(fp);
return i;
}
i++;
}
}
这个函数看起来没问题,但实际上是存在bug的,feof不建议与fgets配合使用,因为在读完最后一行的时候(dict.txt的最后一行没有换行符),feof认为读取结束,此时函数返回,最后一行没能统计到。当feof与fgetc配合使用时,fgetc只有读取失败返回-1之后,feof才认为文件读取结束,而feof与fgets配合时,只需要最后一行读完,feof就认为文件读取结束,无需等到读取失败。
如果把i++移动到if语句前面,也是不行的,因为当文件是一个空文件时,i++也会执行。
可以按以下方式修改
int line_number()
{
FILE* fp = open(FILE_PATH);
int i = 0;
char temp[128];
char* p;
while (1)
{
p = fgets(temp, sizeof(temp), fp);
if (!p)
{
fclose(fp);
return i;
}
i++;
}
}
当读到最后一行的时候,p仍然不为NULL,这样后面的i++还是能够正常执行的,但下一次循环时,读取失败,p为NULL,此时执行if语句中的内容。下面是该函数的测试程序
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main()
{
int lines = line_number();
printf("%d\n", lines);
return 0;
}
输出:
222690
这里的行数和我们用notepad++中看到的行数不一致,我一直没找到原因,因为行数太多,又不能通过打断点调试找到原因,直到我后面对比了视频配套的代码才找到原因。在函数line_number中char temp[128];,也就是temp的长度只有128个字节,通常情况下是够用的,但某些单词或者翻译极度的长,128字节仍然不够用,导致一行被读两次。
将128改成256,就能正常计算行数了,代码如下:
int line_number()
{
FILE* fp = open(FILE_PATH);
int i = 0;
char temp[256];
char* p = NULL;
while (1)
{
p = fgets(temp, sizeof(temp), fp);
if (NULL == p)
{
fclose(fp);
return i;
}
i++;
}
}
输出:

4 词典的初始化
所谓初始化,就是将词典文件中的单词和翻译都写进内存
Dict* dict_init() {
FILE* fp = open(FILE_PATH);
int lines = line_number();
Dict* dict = (Dict *)malloc(sizeof(Dict) * lines);
char temp[256];
int len = 0;
for (int i = 0; i < lines/2; i++)
{
fgets(temp, sizeof(temp), fp);
len = strlen(temp);
dict[i].key = (char*)malloc(len + 1);
strcpy(dict[i].key, temp);
fgets(temp, sizeof(temp), fp);
len = strlen(temp);
dict[i].content = (char*)malloc(len + 1);
strcpy(dict[i].content, temp);
}
fclose(fp);
return dict;
}
测试程序尝试输出5个单词及其翻译,代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main()
{
/*int lines = line_number();
printf("%d\n", lines);*/
typedef struct _dict {
char* key;
char* content;
} Dict;
Dict * dict = dict_init();
for (int i = 0; i < 5; i++)
{
printf("%s\t%s\n", dict[i].key, dict[i].content);
}
return 0;
}
这里暂时不考虑内存泄漏的问题。
输出:
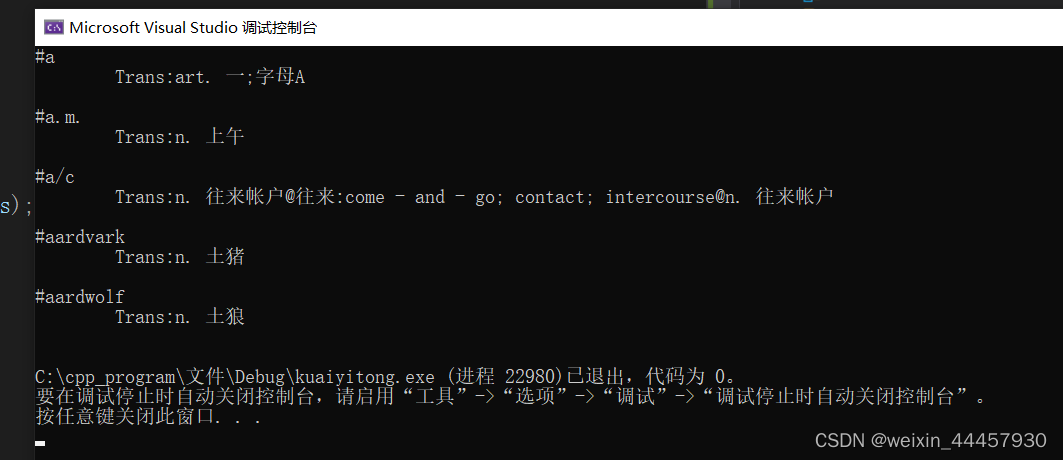
显然,输出的单词和字符,有很多字符不是我们想要的
下面来改进一下

因为单词的每行都是以#号开头,翻译都是以Trans:开头,并且单词和翻译,后面有可能跟了空格、换行等无效字符,因此需要对读到的信息进行处理
char* filter_buf(char *buf)
{
int n = strlen(buf) - 1;
while (buf[n] == ' ' || buf[n] == '\n' || buf[n] == '\r' || buf[n] == '\t')
n--;
buf[n + 1] = 0;
char* new_buf;
if ('#' == buf[0]) //单词
new_buf = buf + 1;
else //翻译
new_buf = buf + 6;
return new_buf;
}
测试程序如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
int main()
{
char str[256];
char* new_str = NULL;
strcpy(str, "#abcde \t\r\n");
new_str = filter_buf(str);
printf("%s len=%d\n", new_str, strlen(new_str));
strcpy(str, "Trans:n. 算盘");
new_str = filter_buf(str);
printf("%s len=%d\n", new_str, strlen(new_str));
return 0;
}
输出
abcde len=5
n. 算盘 len=7
因为汉字占两个字节,因此第二次输出的时候strlen(new_str)是7
把filter_buf函数插入到词典初始化函数中
Dict* dict_init() {
FILE* fp = open(FILE_PATH);
int lines = line_number();
Dict* dict = (Dict *)malloc(sizeof(Dict) * lines);
char temp[256];
char* str;
int len = 0;
for (int i = 0; i < lines/2; i++)
{
fgets(temp, sizeof(temp), fp);
str = filter_buf(temp);
len = strlen(str);
dict[i].key = (char*)malloc(len + 1);
strcpy(dict[i].key, str);
fgets(temp, sizeof(temp), fp);
str = filter_buf(temp);
len = strlen(str);
dict[i].content = (char*)malloc(len + 1);
strcpy(dict[i].content, str);
}
fclose(fp);
return dict;
}
测试程序如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main()
{
/*int lines = line_number();
printf("%d\n", lines);*/
typedef struct _dict {
char* key;
char* content;
} Dict;
Dict * dict = dict_init();
for (int i = 0; i < 5; i++)
{
printf("%s\t%s\n", dict[i].key, dict[i].content);
}
return 0;
}
输出如下:
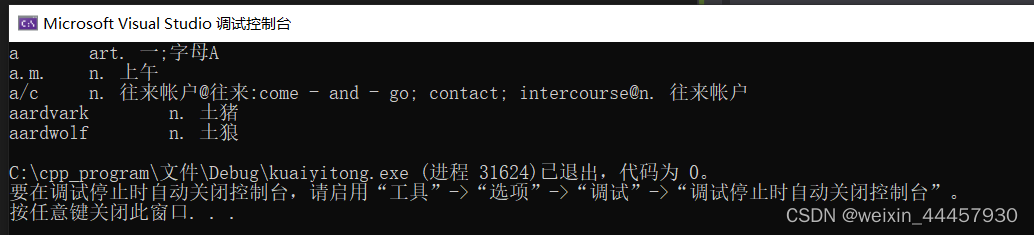
能输出这样的,说明初始化成功
5 搜索
搜索程序可以和简易版的相同,但因为结构体成员发生了改变,因此这里需要稍微改一下名字,代码如下:
void search(Dict* dict, char* key, int n)
{
for (int i = 0; i < n; i++)
{
if (strcmp(dict[i].key, key) == 0)
{
printf("OK!The content word is:%s", dict[i].content);
printf("\n");
return;
}
}
printf("There is no %s\n", key);
}
测试程序如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
int main()
{
typedef struct _dict {
char* key;
char* content;
} Dict;
Dict * dict = dict_init();
char str[256];
for (int i = 0; i < 2; i++) //这里循环只执行两次
{
printf("Please enter a word:");
fgets(str, strlen(str), stdin);
str[strlen(str) - 1] = 0;
search(dict, str, line_number() / 2);
}
return 0;
}
输出
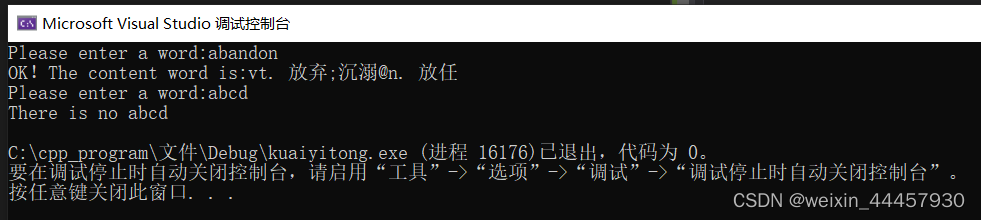
可以看到,搜索也是没问题的
6 翻译
将刚刚搜索的测试程序稍加改动,就得到了翻译的函数;
void translate() {
Dict* dict = dict_init();
int ret = 0;
char key[256];
while (1)
{
printf("Please Enter the world you want to search:");
fgets(key, sizeof(key), stdin);
key[strlen(key) - 1] = 0;
printf("%s\n", key);
search(dict, key, line_number() / 2);
}
}
测试程序如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
int main()
{
/*typedef struct _dict {
char* key;
char* content;
} Dict;
Dict * dict = dict_init();
char str[256];
for (int i = 0; i < 2; i++)
{
printf("Please enter a word:");
fgets(str, strlen(str), stdin);
str[strlen(str) - 1] = 0;
search(dict, str, line_number() / 2);
}*/
translate();
return 0;
}
输出如下:
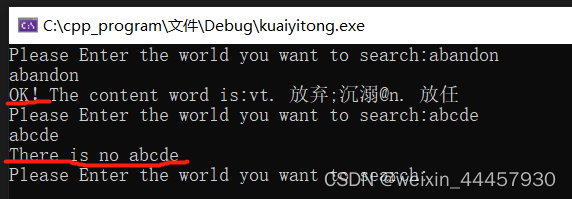
至此,快译通制作完毕。
7 完整程序
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
typedef struct _dict {
char * key;
char * content;
} Dict;
# define FILE_PATH "./dict.txt"
FILE* open(char * file_path)
{
FILE* fp = fopen(file_path, "r");
if (!fp)
{
perror("open");
exit(0);
}
return fp;
}
int line_number()
{
FILE* fp = open(FILE_PATH);
//FILE* fp = open("test_line.txt");
int i = 0;
char temp[256];
char* p = NULL;
while (1)
{
p = fgets(temp, sizeof(temp), fp);
if (NULL == p)
{
//printf("%d\n", strlen(temp));
fclose(fp);
return i;
}
i++;
}
}
char* filter_buf(char *buf)
{
int n = strlen(buf) - 1;
while (buf[n] == ' ' || buf[n] == '\n' || buf[n] == '\r' || buf[n] == '\t')
n--;
buf[n + 1] = 0;
char* new_buf;
if ('#' == buf[0]) //单词
new_buf = buf + 1;
else //翻译
new_buf = buf + 6;
return new_buf;
}
Dict* dict_init() {
FILE* fp = open(FILE_PATH);
int lines = line_number();
Dict* dict = (Dict *)malloc(sizeof(Dict) * lines);
char temp[256];
char* str;
int len = 0;
for (int i = 0; i < lines/2; i++)
{
fgets(temp, sizeof(temp), fp);
str = filter_buf(temp);
len = strlen(str);
dict[i].key = (char*)malloc(len + 1);
strcpy(dict[i].key, str);
fgets(temp, sizeof(temp), fp);
str = filter_buf(temp);
len = strlen(str);
dict[i].content = (char*)malloc(len + 1);
strcpy(dict[i].content, str);
}
fclose(fp);
return dict;
}
void search(Dict* dict, char* key, int n)
{
for (int i = 0; i < n; i++)
{
if (strcmp(dict[i].key, key) == 0)
{
printf("OK!The content word is:%s", dict[i].content);
printf("\n");
return;
}
}
printf("There is no %s\n", key);
}
void translate() {
Dict* dict = dict_init();
char key[256];
while (1)
{
printf("Please Enter the world you want to search:");
fgets(key, sizeof(key), stdin);
key[strlen(key) - 1] = 0;
printf("%s\n", key);
search(dict, key, line_number() / 2);
}
}
测试程序
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
int main()
{
translate();
return 0;
}

















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









