







 本文以生动的比喻介绍了Kubernetes集群的组件及其作用,包括node、api-server、etcd、scheduler、controller-manager、kube-proxy和kubelet等。详细阐述了pod的创建流程,从yaml文件校验、api-server交互、调度策略、节点选择、pod状态更新直至kubelet创建和管理pod的过程。同时,提到了pod的优先级、抢占机制以及调度失败后的处理。
本文以生动的比喻介绍了Kubernetes集群的组件及其作用,包括node、api-server、etcd、scheduler、controller-manager、kube-proxy和kubelet等。详细阐述了pod的创建流程,从yaml文件校验、api-server交互、调度策略、节点选择、pod状态更新直至kubelet创建和管理pod的过程。同时,提到了pod的优先级、抢占机制以及调度失败后的处理。
集群组件
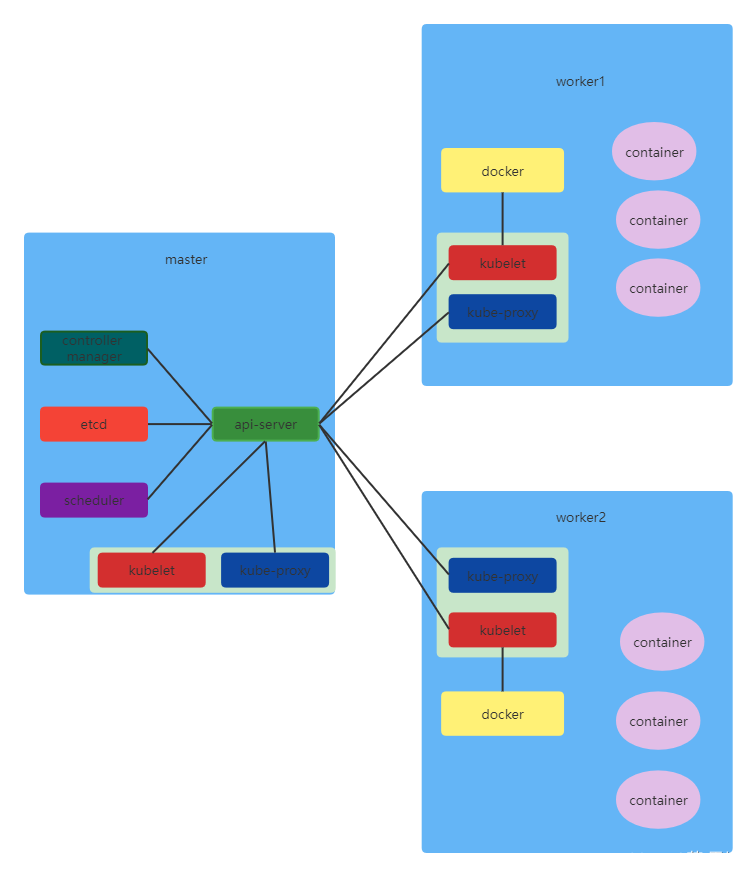
node
Kubernetes所运行服务的物理节点,所有的容器和组件全部运行于这些节点上.节点分为"master"和"slave".
master节点主要运行于所有的控制平面组件,slave节点主要运行于工作容器(业务容器).
api-server
网关设备,集群中所有组件的互相访问都需要经过他.
etcd
保存了集群中所有数据,负责持久化.
scheduler
调度组件.pod被提交后scheduler会寻找合适的节点来放置pod.
controller-manager
控制器,包含了节点控制器,任务控制器,端点令牌控制器等.
kube-proxy
网络管理服务,service实现的主要组件,负责节点的iptables或ipvs管理等
kubelet
节点管理,负责运行pod和销毁pod.kubelet和kube-proxy是运行在集群中所有节点上的.
docker
CRI(容器运行时)基础组件
container
kubelet调用docker所创建的工作容器
把一个Kubernetes集群看做一个黑心公司,controller-manager就是老板,他管理着整个公司的大事,如名称空间创建,pod创建申请.管理每个厂区(Node)
api-server就是传达室,一方面对外传达老板的命令,一方面将各类信息整理汇报给老板
etcd就是公司的数据库或者文档库(档案室),记录公司大大小小的事情,比如有几个厂子,每个厂子都有什么规定.
scheduler就是业务部门,当有新项目(pod创建申请)提交过来他们负责处理安排人去做.
kubelet就是每个厂区的厂长,跟老板汇报自己的工作同时管理整个厂区(当前节点资源)
kube-proxy负责该厂区的货物出入,接待外来人口.(接收处理流量请求)
container就是一个个的工人,狠心的资本家在工人工作结束后开除掉他,等来活了在招一个上来干活(容器运行结束即释放)
docker就是这个厂区的人力部门,为虎作伥,管着开除和招人.
创建pod
-
kubectl检查文件是否符合规范
甲方的项目部门先检查项目是否合法,不合法直接打回,创建者自己去修改yaml文件直到合法
-
先检查集群或者pod是否满足某些条件(如名称指定了资源限制是否符合)
然后检查是否符合公司业务,公司是否有能力去做这个项目.
-
接下来过滤出不能运行该pod的节点(根据节点资源或者亲和性),然后将他们淘汰.如果过滤后可用节点为0那么则将pod塞进另一个队列触发抢占,对于被驱逐的pod(低优先级)可以获得30s优雅停止的时间,30s后强制杀死.pod被驱逐后会重新被调度看是否可以运行到其他节点.如果直接过滤出部分满足条件的节点则进入下一步
接来下筛选所有厂区,从中挑出几个有能力做这个项目的厂子(或者说排除掉没能力做这个项目的厂子)(根据厂子资源或者厂长意愿).如果最后没有找到有能力的厂子,就把活丢给秘书(另一个队列)说这个项目很重要给我优先干,然后看看其他厂子是否有可延期的项目,判断一个项目是不是能延期就根据给的钱多钱少来判断,有能延期的项目的话就给你们30s缓冲时间结束现在手里的活,30s后立马停手先来干这个.
然后看看他们厂子停掉的这个项目别的部门能不能做
-
如果上一步有可用节点,那么对过滤出来的pod进行评分,从中选择出节点,优先使用资源较多的,同时如果该镜像较大,但是某个节点存在这个镜像那么也优先使用这个节点
如果上一步直接找出了几个有能力去做的厂子,从里面挑一个最闲的厂子去做,不能白吃干饭啊,或者其他衡量标准就是哪个厂子干过这个活毕竟有经验继续让他干.
-
然后scheduler通知api-server,pod调度完成.
然后项目规划部通过传达室(api-server)中转,这个项目安排好了.
-
接下来开始将这个pod状态更新为已调度,然后进行绑定(将对应的pod的 nodeName字段设置为该节点的名字)
传达室把这个消息告诉档案室,让他们记下这个项目调度完成了,要由那个厂子来做(这时候该厂还不知道自己要有一个新项目)
-
kubelet会不断地请求api-server核实自己主机的pod,在请求的时候发现有个pod自己的主机上没有则开始创建
厂子闲着没事就打电话给传达室问问我这个厂子项目有变化吗,传达室每次都很负责去档案室找出来这个厂子要负责的项目告诉他们.
厂子发现传达室返回的列表有一个项目自己现在没有做,然后立刻安排人去做这个项目
-
kubelet创建pod完成,请求api-server更新pod状态为Running,api-server将结果保存到etcd.
厂子检查了下机械设备工位都准备好了,人员也开始工作了,然后告诉传达室xx项目开始正常运作了.传达室再找档案室记下来.
优先级就是钱,从0-10亿,再多钱的项目不敢接,不给钱的项目老板图个好名声也做,无非就是给钱的来了就先把不给钱的停了.
厂子就是kubelet,他们会定期向老板(controller-manager)汇报自己工作负载,保存到档案室(etcd).
被驱逐的pod享有30s的优雅停止时间,这个时间内他可以释放资源,按自己顺序挨个停止任务,写入停止日志等,就是你开除工人得提前三十天通知他,告诉他最晚下个月这时候你必须得走了.
整个过程就是甲方有个部门自己先检查下,确认无误后交给Kubernetes公司,公司老板再检查一遍项目是否可以,通过后先把这个招标文件合同之类的记下来,然后通知调度部门找个厂子,调度部门安排好之后也记下来,等着对应厂子自己来问,我这个厂子现在做的这些项目有变动吗,然后丢给他一份最新的安排表,他自己对照去对比需要新建那些,然后检查下设备工位是否准备好了,最后再告诉老板他们一声: 这个项目正常开始了
以上内容为了便于理解做了很大的简化,实际的pod从提交到创建的完成过程如下:
参考文档
源码解析:K8s 创建 pod 时,背后发生了什么(二)(2021)
源码解析:K8s 创建 pod 时,背后发生了什么(三)(2021)
源码解析:K8s 创建 pod 时,背后发生了什么(四)(2021)
源码解析:K8s 创建 pod 时,背后发生了什么(五)(2021)
Kubernetes默认调度器的优先级与抢占机制
kubectl开始检查yaml文件格式是否正确,关键字是否为空等.
使用"config"文件的证书内容,创建一个https请求,访问api-server.
api-server首先对提交的内容首先进行"认证",是否是加密的,所带的token是否正确.
接下来"鉴权",鉴权通过后会开始检查所提交的内容是否符合集群规则和限制.
接下来由api-server将提交信息持久化到etcd数据库.最后在发起一个get请求查看是否在数据库中了.
接下来会是controller来对他进行检查(这个步骤叫做 Initializer),负责在这个资源对外可见之前在执行一次处理,给pod注入证书,暴露端口或者打上特定的annotation(标注).
此步骤也可以被跳过,pod直接对外可见,如果没有跳过则在执行完毕之后对外可见.
初始化之后这个资源对外就是可见的(api-server会去更新他),然后会被对应资源的controller监控到,如deployment controller,然后他开始创建新的资源
k8s中存在大量的controller,他们不断地检查pod当前状态和期望状态是否一致,不一致则将其改变为期望状态,而这一组controller的集合就是Kubernetes中的 controller-manager.
deployment controller会通过api-server去查询调用replicas controller,如果没有对应资源则创建.如果有对应资源但是状态不一致则触发同步.
如果不存在,创建一个replicaSet然后分配一个标签.ReplicaSet的部分metadata则是来源于Deployment的metadata字段.
Deployment只负责创建或者同步ReplicaSet controller的状态,所以pod还是要ReplicaSet controller来创建,这也是deployment资源依赖ReplicaSet资源的原因.
ReplicaSet被创建之后.ReplicaSet controller会不断地检查他们的状态,发现不一致.开始增加pod数量.
创建的时候会按批次一点一点来创建,如果上一批成功那么下一批就翻倍.(为了不给api-server造成太大压力)
接下来就是其他的controller同步信息,清理缓存释放连接.这会etcd已经存储了一个deployment,一个replicaSet和对应数量的pod.
前面处理的都是"元数据"信息,主要是各个controller之间互相同步调用,pod此时可以被查到但处于
Pending状态,接下来的scheduler才是创建pod的开始.
scheduler是独立于controller-manager存在的.他也是个监听器监听事件然后触发动作.
首先是predicates函数,也就是"过滤"节点.他会根据不同的规则:如指定了资源节点资源是否满足,是否设置了亲和性,来过滤出一组符合要求的节点.
接下来就是priority function,又称排序或者打分.这个步骤根据上一个步骤的结果在筛选出的node列表中,选取节点,如果指定了亲和性希望pod尽可能的分散开,那么则优先选择资源比较闲置的节点.
如果在第一步就发现没有主机满足条件,那么第二个阶段就会直接调度失败.
调度失败的pod会被放入一个失败队列. 当失败队列中的pod被更新后,会被重新放入调度队列,重新给她一次机会.如果再次失败,那么首先检查其调度失败的原因.
如果是因为没有对应的volume,或者说没有符合其亲和性的标签等失败,那么则重新放入失败队列,过会再重新检查是否可以被调度了.
如果是因为资源不足调度失败,那么接下来检查这个pod的"优先级".如果他的优先级足够高,那么则会触发"抢占"
抢占开始后,会把目前缓存的节点信息复制一份,开始模拟抢占.目的就是尽可能的释放较少的pod或者释放优先级最低的pod来保证当前被调度的高优先级pod运行.
接下来调度器会把需要释放的pod删除,给这个pod标记上对应运行的节点防止被其他pod抢走,然后重新把他放回调度队列.这次调度大概率就能成功了.
接下来对pod进行绑定到节点(binding),将pod和对应节点的关系记录,通知api-server.
api-server会将pod的nodeName指定上分配的节点的名字.添加annotations,最后设置pod PodScheduled状态为"true".表示调度成功.
接下来就是kubelet登场了.他也是一个controller,从api-server获取本节点需要存在的pod,然后和自己的缓存进行核对,发现不存在新建的则开始准备新建一个容器:如创建容器目录,cgroups,挂载卷,创建网络等.接下来调用CRI(容器)开始启动创建pod.

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









