







 本文深入讲解Java集合框架,包括List、Set、Map等接口及其实现类的特点与使用方法,探讨泛型、迭代器、增强for循环等核心概念,解析哈希表结构与Set集合存储数据不重复的原理。
本文深入讲解Java集合框架,包括List、Set、Map等接口及其实现类的特点与使用方法,探讨泛型、迭代器、增强for循环等核心概念,解析哈希表结构与Set集合存储数据不重复的原理。
包装类
概念
-
基本数据类型使用起来非常方便,但是没有对应的方法来操作这些基本数据类型,可以使用一个类,把基本数据包装起来,在类中定义一些方法,这个类就称作包装类。
基本数据类型 对应的包装类(位于java.lang包中) byte Byte short Short int Integer long Long float Float double Double char Character boolean Boolean --注意int char的包装类分别是 Integer Character
装箱和拆箱
/*
装箱:把基本的数据类型,包装到包装类中(基本类型的数据-->包装类)
装箱的方法
1.构造方法
Integer(int value)构造一个新分配的Integer对象,int value 代表指定的int 值
Integer (String s)构造一个新分配的Integer对象,传递的字符串必须是基本类型的字符串(int)如"100"可以,"a"不行
2.静态方法
static Integer valueOf(int i)
static Integer valueOf(String s)
拆箱的方法
1.成员方法
int intValue(),以int类型返回该Integer的值
*/
public class Demo01Integer {
public static void main(String[] args) {
//使用构造方法装箱,int-->Integer
Integer integer = new Integer(100);
Integer integer1 = new Integer("2000");
System.out.println(integer);//100
System.out.println(integer1);//2000
System.out.println("============");
//使用静态方法进行装箱
Integer integer2 = Integer.valueOf("3000");
Integer integer3 = Integer.valueOf(100);
System.out.println(integer2);//3000
System.out.println(integer3);//100
//拆箱
int i = integer.intValue();
System.out.println(i);//100
}
}
自动装箱和拆箱
import java.util.ArrayList;
/*
自动装箱和自动拆箱:基本数据类型和包装类之间的互相转换
jdk1.5出现的新特性
*/
public class Demo02Integer {
public static void main(String[] args) {
Integer i=10;//自动装箱 相当于 Integer i =new Integer(10);或者 Integer i= Integer.valueOf(10)
/*
i+10 为自动拆箱,i=i+10;为自动装箱
*/
i=i+10;
ArrayList<Integer> arr =new ArrayList<>();
arr.add(11);//添加的基本数据类型,隐含了一个自动装箱的动作
arr.get(0);//自动拆箱
}
}
基本数据类型和字符串类型之间的转换
/*
基本数据类型于字符串之间的互相转换
基本数据类型-->字符串
1.基本数据类型的值+"",最简单的方法,工作中最常用的方法
2.包装类的静态方法,toString(参数),Object toString()的重载形式
static String toString(int i)
3.String 类的静态方法 valueOf(),这跟之前讲的装箱方法中的有点类似
字符串-->基本数据类型
使用包装类的静态方法parseXXX(String s)
Integer类:static int parseInt(String s)
Double类: static double parseDouble(String s)
*/
public class Demo03Inreger {
public static void main(String[] args) {
//基本数据类型转为字符串
int i=100;
String s=i+"";
System.out.println(s+200);//100200
String s1 = Integer.toString(i);//包装类的toString()方法
System.out.println(s1);//100
String s2 = String.valueOf(i);
System.out.println(s2);//100
System.out.println("=============");
//字符串转为基本数据类型
int i1 = Integer.parseInt("100");
System.out.println(i1);//100
double v = Double.parseDouble("9.9");
System.out.println(v);//9.9
}
}
集合框架
集合概述
- 集合:集合是java中提供的一种容器,可以用来存放多个数据
- 继承:子类共性抽取形成父类(接口)
- 学习集合框架的学习方式
- 学习顶层(共性)
- 使用底层
- 集合和数组的区别
- 数组的长度是固定的,集合的长度是可以改变的
- 数组中存储的都是同一类型的元素,不管是基本数据类型还是对象,集合存储的都是对象,如果要存储基本类型的数据要使用包装类,在开发中一般当对象多的时候使用集合进行存储
集合的框架
-
java.util.Collection(单列集合)
/* Collection:单列集合类的跟接口,用于存储一系列符合某种规则的元素,它有两个重要的子接口分别是java.util.List java.util.Set 1.java.util.List特点是元素有序,元素可重复,有索引的可以使用普通的for循环遍历主要的实现类有java.util.ArrayList,java.util.LinkedList,java.util.Vector 2.java.util.Set特点是元素无序,而且不可以重复,主要实现类有java.util.HashSet,java.util.TreeSet,java.util.LinkedHashSet,备注(TreeSet集合和HashSet集合是无序的,LinkedHashSet是有序的) */import java.util.ArrayList; import java.util.Collection; /* java.util.Collection接口 所有单列集合的最顶层的接口,里面定义了所有单列集合的共性方法 任意的单列集合都可以使用Collection接口中的方法 共性的方法: 1.public boolean add(E e):把指定的对象添加到当前集合中 2.public void clear():清空当前的集合 3.public boolean remove(E e):把指定的对象在当前集合中删除 4.public boolean contains(E e):判断当前集合中是否包含指定的对象 5.public boolean isEmpty():判断当前集合是否为空 6.public int size():返回集合中元素的个数 7.public Object[] toArray():把集合中的元素,存储到数组中 */ public class Demo01Collection { public static void main(String[] args) { //创建集合对象 Collection<String> col=new ArrayList<>();//向上转型 System.out.println(col);//重写了toString()方法//[] //先判断下集合是否为空 boolean empty = col.isEmpty(); System.out.println("empty?:"+empty);//true //空集合清空会咋样? col.clear(); System.out.println(col);//[] //往集合中添加元素 col.add("张三"); col.add("李四"); col.add("王五"); col.add("赵六"); col.add("田七"); col.add("王八"); col.add("张三"); System.out.println(col);//[张三, 李四, 王五, 赵六, 田七, 王八, 张三] //删除集合中的元素 col.remove("张三"); System.out.println(col);//[李四, 王五, 赵六, 田七, 王八, 张三] //contains的使用 boolean b = col.contains("张三"); System.out.println("包含张三吗?:"+b); //集合元素的个数 int size = col.size(); System.out.println("集合中元素的个数是:"+size); Object[] array = col.toArray(); for (int i = 0; i < array.length; i++) { System.out.println(array[i]); } /* for (int i = array.length - 1; i >= 0; i--) { }*///反向遍历的快捷键 array.forr } } -
java.util.Map(双列集合)
Iterator接口
- 迭代:即Collectiong集合元素的通用获取方式,在取元素之前先要判断集合中有没有元素,如果有就把这个元素取出来,继续判断,如果还有就在取出来,一直到把集合中的元素全部取出,这种取出的方式叫做迭代。
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
java.util.Iterator接口:迭代器(对Collection类进行遍历)
常用方法:
1.boolean hasNext()有下一个元素返回true
2.next() :返回迭代的下一个元素。
注意:Iterator迭代器是一个接口,我们无法直接使用,需要使用Iterator的接口实现类,获取接口实现类的方法比较特殊
Collection接口中有一个方法叫iterator(),返回的就是迭代器的实现类对象
Iterator<E> itrator()
迭代器的使用步骤:
1.使用集合中方法iterator()获取迭代器的实现类对象,使用Iterator接口接受(多态)
2.使用Iterator接口中的方法,hasNext()判断有没有下一个元素
3.使用Iterator接口中的方法next取出集合中的下一个元素
注意迭代器也是有泛型的,迭代器的泛型跟着集合走,集合是什么泛型,迭代器就是什么泛型
*/
public class Demo01Iterator {
public static void main(String[] args) {
//创建集合对象,多态
Collection<String> col=new ArrayList<>();
col.add("张三");
col.add("李四");
col.add("王五");
col.add("赵六");
col.add("田七");
System.out.println(col);
/*未知循环次数使用while循环*/
Iterator<String> iterator = col.iterator();
while(iterator.hasNext()!=false){//有元素
String e = iterator.next();//取数
System.out.println(e);
}
System.out.println("=============================");
//for循环实现迭代器的效果
/*
for循环初始化表达式:Iterator<String> it2 = col.iterator()
布尔表达式:it2.hasNext()
步进表达式:不用写,注意分号不要丢
*/
for(Iterator<String> it2 = col.iterator();it2.hasNext();){
String s = it2.next();
System.out.println(s);
}
}
}
迭代器的原理
[外链图片转存失败,源站可能有防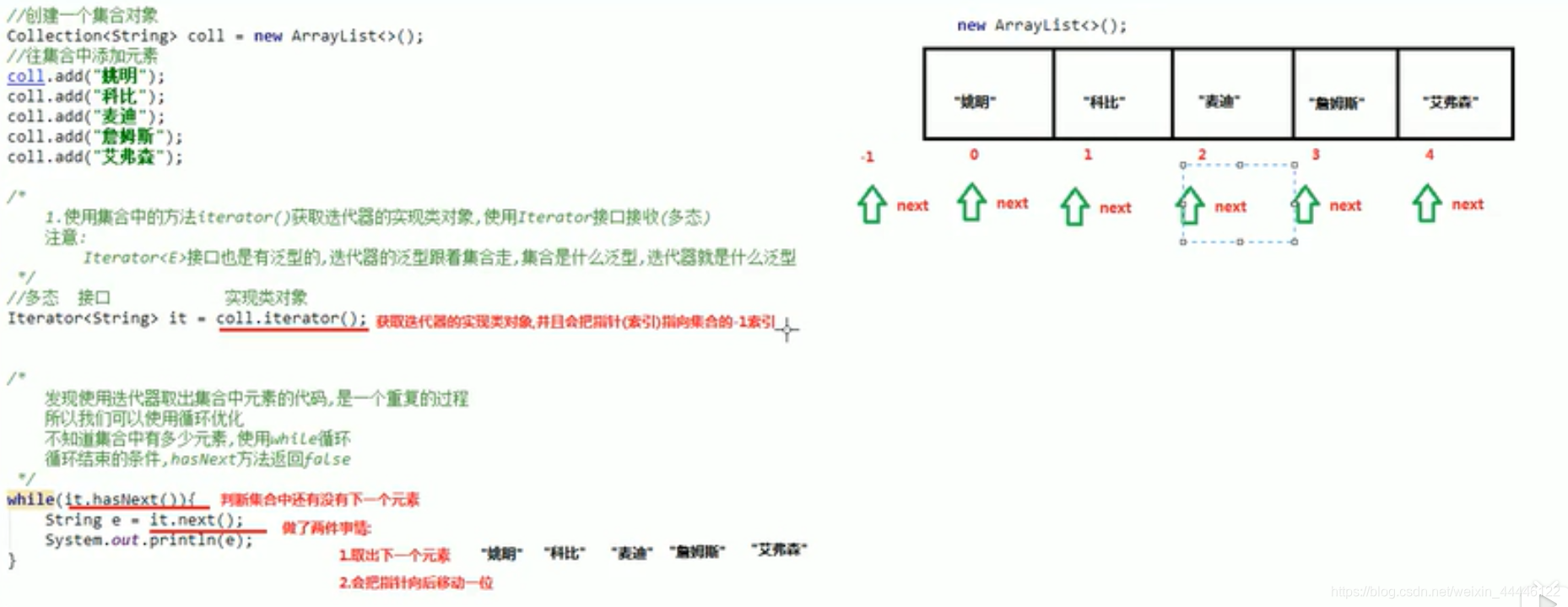 盗链机制,建议将图片保存下来直接上传(img-LQ8x4NYK-1591523106775)(C:\myNote\java_learning\迭代器的实现原理.PNG)]
盗链机制,建议将图片保存下来直接上传(img-LQ8x4NYK-1591523106775)(C:\myNote\java_learning\迭代器的实现原理.PNG)]
增强型for循环
-
JDK1.5以后出现的一个高级for循环,专门用来遍历数组和集合的,他的内部原理其实是一个迭代器,所以在遍历过程中不能对集合中的元素进行增删操作
-
for(元素的数据类型 变量:Collection集合or数组) //它用于遍历Collection和数组,通常只进行遍历元素,不要在遍历过程中对集合元素进行增删操作import java.util.ArrayList; /* public interface Collection<E>extends Iterable<E>:所有的单列集合都可以使用增强for public interface Iterable<T>实现这个接口允许对象成为 "foreach" 语句的目标。 */ public class Demo02Foreach { public static void main(String[] args) { demoo1(); System.out.println("============"); demo02(); } private static void demo02() { //创建String类型的ArrayList数组 ArrayList<String> list = new ArrayList<>(); list.add("aaa"); list.add("ccc"); list.add("ddd"); list.add("eee"); list.add("fff"); list.add("ggg"); list.add("bbb"); for(String i:list){ System.out.println(i); } System.out.println("================="); for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } } private static void demoo1() { int[] arr={1,2,3,4,5}; //增强型for循环遍历数组 for (int i:arr) { System.out.println(i); } System.out.println("=================="); //普通循环遍历数组 for (int i = 0; i < arr.length; i++) { System.out.println(arr[i]); } } }
泛型
- 泛型是一种未知的数据类型,当我们不知道使用何种数据类型的时候,可以使用泛型,泛型也可以看成一个变量,用来接收数据类型
- 集合中可以存储任意对象,只要把对象存储集合后,那么这时它们都会被提升成Object类型,当我们取出每一个对象,并且进行相应的操作,这是必须采用类型转换
- 使用泛型的好处
- 避免了类型转换的麻烦,存储的是什么类型,取出的就是什么类型
- 把运行前异常(代码运行之后会抛出的异常),提升到了编译器(写代码的时候直接报错)
- 使用泛型的弊端
- 泛型是什么类型,就只能存什么类型的数据
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Demo01Generic {
public static void main(String[] args) {
demo01();
System.out.println("=====");
demo02();
}
//使用泛型
private static void demo02() {
//创建Collection对象
Collection<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("ddd");
//增强型for循环遍历集合
for(String i:list){
System.out.println(i);
}
}
//不使用泛型
private static void demo01() {
//创建Collection对象
Collection col=new ArrayList();
col.add("aaa");
col.add(5);
//获取迭代器
Iterator iterator = col.iterator();
//迭代
while(iterator.hasNext()){
Object next = iterator.next();
System.out.println(next);
//如果我要使用子类特有的方法需要使用向下转型
//String s=(String)next;
// System.out.println(s.length());//Integer cannot be cast to java.lang.String
}
}
}
泛型的定义和使用
定义的格式
修饰符 class 类名<代表泛型的变量>{}
public class GenericClass<E> {
private E name;
private E age;
public E getName() {
return name;
}
public void setName(E name) {
this.name = name;
}
public E getAge() {
return age;
}
public void setAge(E age) {
this.age = age;
}
}
//
public class Demo01GenericClass {
public static void main(String[] args) {
//不是使用泛型默认是Object 类型
GenericClass gc=new GenericClass();
gc.setName("aaa");
Object name = gc.getName();
System.out.println(gc.getName());//aaa
//使用String 类型
GenericClass<String> gc1=new GenericClass<>();
gc1.setName("bbb");
String name1 = gc1.getName();//bbb
System.out.println(name1);
System.out.println("===========");
//使用Integer
GenericClass<Integer> gc2=new GenericClass<>();
gc2.setName(1);
int name2 = gc2.getName();//自动拆箱
System.out.println(name2);//1
}
}
定义泛型的方法
-
定义含有泛型的方法:泛型定义在方法的修饰符和返回值类型之间
-
格式
修饰符 <泛型> 返回值类型 方法名(参数列表(使用泛型)){ 方法体; } 含有泛型的方法,在调用方法的时候确定泛型的数据类型 传递什么类型的参数,泛型就是什么类型public class GenericMethod { public <M> void method01(M m){ System.out.println(m); } public static <M> void method02(M m){ System.out.println(m); } } // public class Demo01GenericMethod { public static void main(String[] args) { GenericMethod gc = new GenericMethod(); gc.method01("aaa"); gc.method01(111); gc.method01(true); gc.method01(9.9); GenericMethod.method02("1111"); GenericMethod.method02(111); GenericMethod.method02(""); } }
定义和使用含有泛型的接口
- 在实现类中指明要使用何种类型
- 跟类一样在创建对象的时候指明何种类型,注意这种泛型的接口要在类名和implements 后接上泛型通配符
public interface GenericInterface<I> {
public abstract void method(I i);
}
//方法一
public class GenericInterfaceImpl implements GenericInterface<String>{/*在实现类指明要实现的泛型类型*/
@Override
public void method(String s) {
System.out.println(s);
}
}
//方法二:
public class GenericInterfaceImpl01<I> implements GenericInterface<I> {/*注意在类名和implements后面都要指明泛型通配符*/
@Override
public void method(I i) {
System.out.println(i);
}
}
//
public class Demo01GnericInterface {
public static void main(String[] args) {
GenericInterfaceImpl gi = new GenericInterfaceImpl();
gi.method("HELLO WORLD");//HELLO WORLD
GenericInterfaceImpl01<String> gi1 = new GenericInterfaceImpl01<>();
gi1.method("hello kitty");//hello kitty
GenericInterface<Integer> gi2=new GenericInterfaceImpl01<>();
gi2.method(12);//12
}
}
泛型的通配符
泛型通配符的一般使用
import java.util.ArrayList;
import java.util.Iterator;
/*
泛型的通配符:?代表任意的通配符
使用方式:
不能创建对象使用
只能作为方法的参数使用
*/
public class Demo05Generic {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("ddd");
list.add("eee");
System.out.println("==========");
ArrayList<Object> list1 = new ArrayList<>();
list1.add(1);
list1.add(2);
list1.add(3);
list1.add(4);
list1.add(5);
System.out.println("=====");
printArray(list);
System.out.println("=========");
printArray(list1);
System.out.println("=======");
printArray01(list1);
System.out.println("=======");
printArray01(list);
/*ArrayList<?> list2 = new ArrayList<>();
list2.add(1);*///这种写法报错
/* ArrayList<Object> list2 = new ArrayList<>();
list2.add("heool");
list2.add(111);
list2.add(true);
printArray(list2);*///集合不使用泛型默认就是object类型
}
//使用增强型for循环遍历集合
private static void printArray01(ArrayList<?> list) {
for (Object next:list) {
System.out.println(next);
}
}
//定义一个遍历的方法可以分别遍历String 和Integer集合
private static void printArray(ArrayList<?> list) {
Iterator<?> it = list.iterator();
while(it.hasNext()){
Object next = it.next();//Object 类型才可以接受任何类型的数据
System.out.println(next);
}
}
}
泛型通配符和泛型方法的区别
?泛型对象是只读的,不可修改,因为?类型是不确定的,可以代表范围内任意类型;
而泛型方法中的泛型参数对象是可修改的,因为类型参数T是确定的(在调用方法时确定),因为T可以用范围内任意类型指定;
注意,前者是代表,后者是指定,指定就是确定的意思,而代表却不知道代表谁,可以代表范围内所有类型;
泛型的上限限定和下限限定
- 泛型的上限限定:?extends E 代表使用的泛型只能是E类的子类或者本身
- 泛型的下限限定:?super E 代表使用的泛型只能是E类的本身或者父类
import java.util.ArrayList;
import java.util.Collection;
public class Demo06Generic {
public static void main(String[] args) {
Collection<Integer> list1=new ArrayList<>();
Collection<Number> list2=new ArrayList<>();
Collection<String> list3=new ArrayList<>();
Collection<Object> list4=new ArrayList<>();
method01(list1);//Integer 是Number的子类符合
method01(list2);//Number本身
// method01(list3);//报错
// method01(list4);//报错
//method02(list1);//不是Number本身或者父类
method02(list2);//Number本身
//method02(list3);//报错
method02(list4);//Number的父类
}
private static void method02(Collection<? super Number> col1) {
}
private static void method01(Collection<? extends Number> col) {
}
}
斗地主案例的实现
-
分析
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ISxOtEXt-1591523106778)(C:\myNote\java_learning\斗地主代码分析.PNG)]
-
实现
import java.util.ArrayList; import java.util.Collections; /* 1.准备牌 2.洗牌 3.发牌 4.看牌 */ public class DouDiZhu { public static void main(String[] args) { //准备牌,定义 ArrayList<String> poker = new ArrayList<>(); poker.add("大王"); poker.add("小王"); //花色,和点牌 String[] color={"♠","♥","♦","♣"}; String[] number={"2","A","k","Q","J","10","9","8","7","6","5","4","3"}; //遍历花色和点牌,添加到poker集合中,组成一副牌 for (int i = 0; i < color.length; i++) { for (int i1 = 0; i1 < number.length; i1++) { // System.out.println(color[i]+number[i1]); poker.add(color[i]+number[i1]); } } //洗牌动作 Collections.shuffle(poker); System.out.println(poker); //发牌,遍历牌库poker ArrayList<String> person1 = new ArrayList<>(); ArrayList<String> person2 = new ArrayList<>(); ArrayList<String> person3 = new ArrayList<>(); ArrayList<String> dipai = new ArrayList<>(); for (int i = 0; i < poker.size(); i++) { System.out.println(poker.get(i)); if(i>=51){ //给底牌发牌 dipai.add(poker.get(i)); }else if(i%3==0){ //给玩家一发牌 person1.add(poker.get(i)); }else if(i%3==1){ //给玩家2发牌 person2.add(poker.get(i)); }else if(i%3==2){ //给玩家3发牌 person3.add(poker.get(i)); } } //看牌 System.out.println("刘德华 "+person1); System.out.println("周润发 "+person2); System.out.println("周星驰 "+person3); System.out.println("底牌 "+dipai); } }
数据结构
数据存储的常用结构有:栈,队列,数组,链表和红黑树
栈
特点:先进后出,压栈,弹栈,栈顶,栈底
队列
特点:先进先出
栈和队列总结
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0XByYcsI-1591523106780)(C:\myNote\java_learning\栈和队列总结.PNG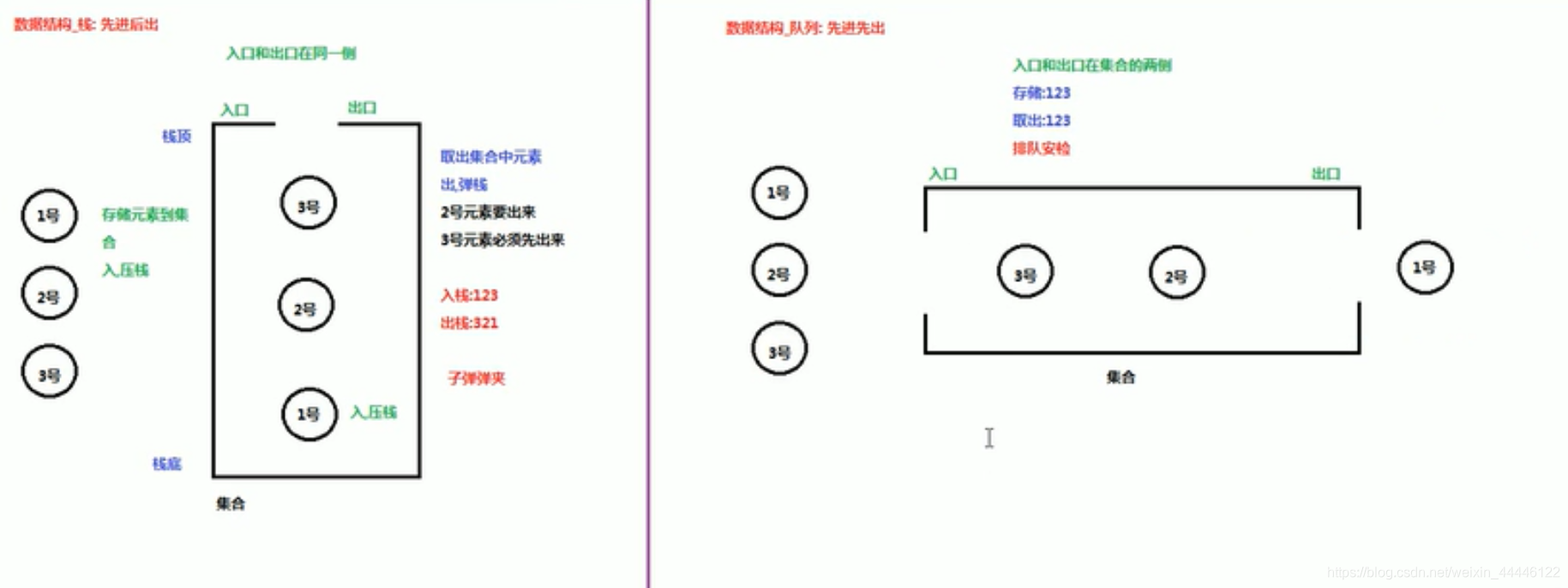 )]
)]
数组
特点:查询快,增删慢
查询快:数组的地址是连续的,我们通过数据的首地址可以找到数组,通过数组的索引何以快速的找到某一个元素
增删慢:增删慢:数组的长度是固定的,我们想要增加/删除一个元素,必须创建一个新数组,把元素的数据赋值过来
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I3CQatBv-1591523106784)(C:\myNote\java_learning\数据结构_数组.PNG)]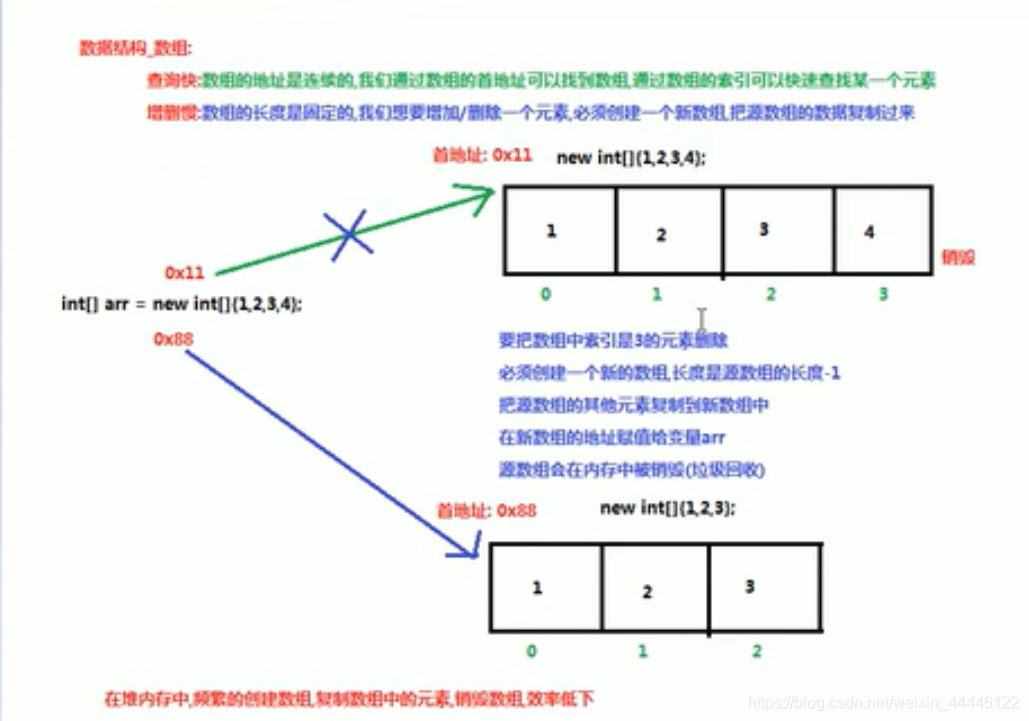
链表(linked list)
特点:查询慢,增删快
/*
查询慢:链表中地址不是连续的,每次查询都得从头开始查询
增删快:链表结构,增加/删除一个元素,对链表的整体没有影响,所以增删快
单向链表:无序
双向链表:有序,两条链子,上一节点知道下一节点的地址,下一节点也知道上一节点的地址
*/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m98CXeE6-1591523106788)(C:\myNote\java_learning\数据结构_链表.PNG)]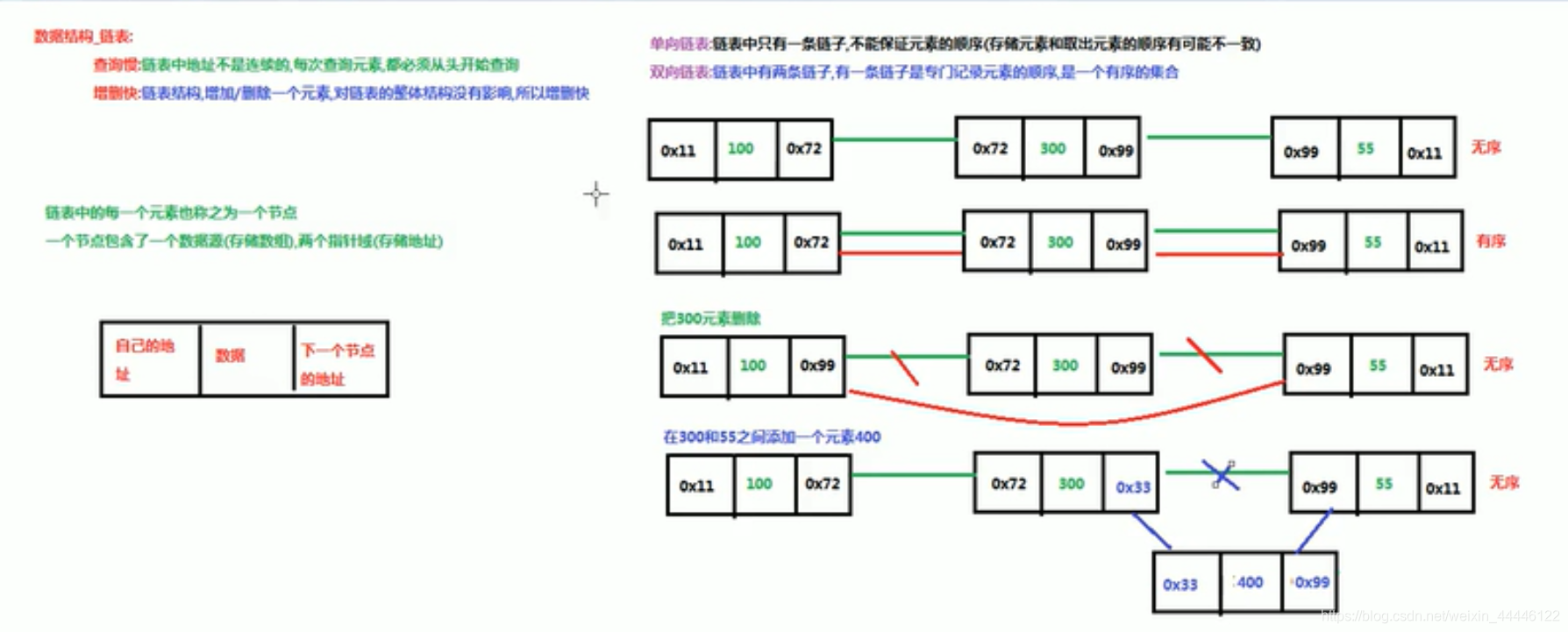
红黑树
特点:趋近于平衡树,查询的速度非常快,查询叶子节点最大次数不会超过最小次数的2倍
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上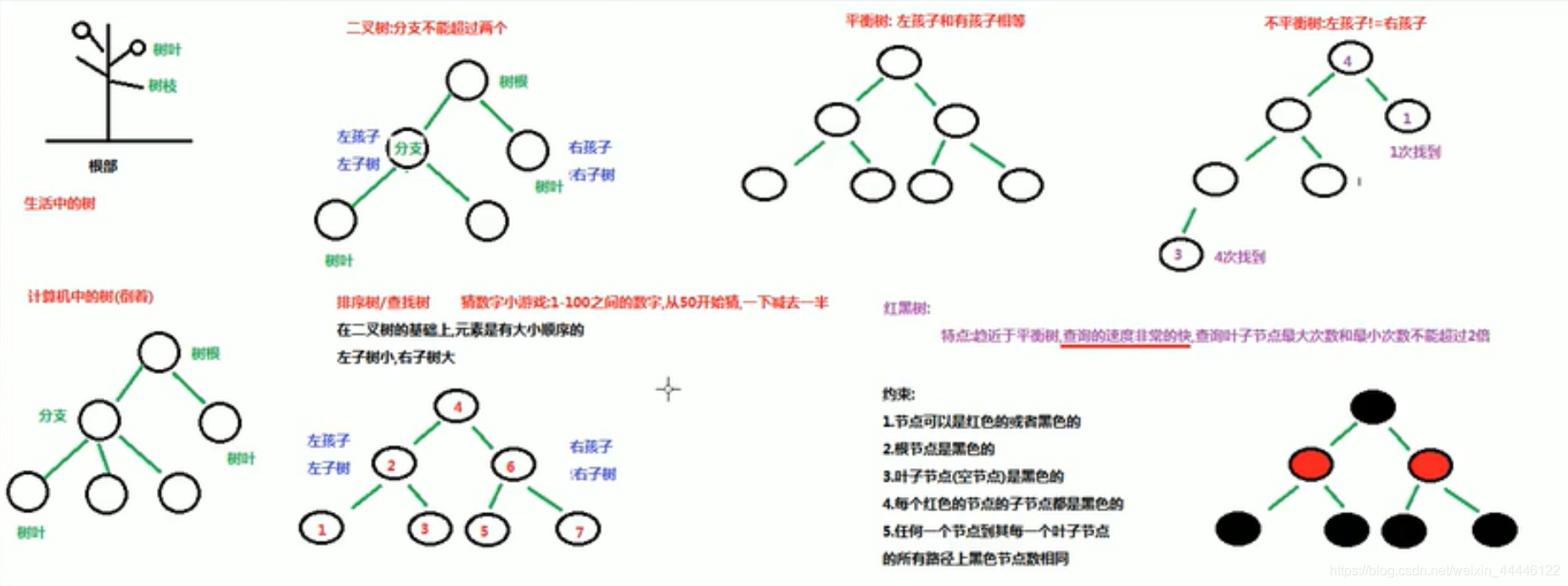 传(img-ddUePClH-1591523106790)(C:\myNote\java_learning\数据j结构_红黑树.PNG)]
传(img-ddUePClH-1591523106790)(C:\myNote\java_learning\数据j结构_红黑树.PNG)]
List集合
List接口的常用方法
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/*
java.util.List 接口继承Collection接口
List接口的特点:
1.有序的集合,存储元素和取出元素的顺序是一致的(存储1,2,3取出1,2,3)
2.有索引,包含一些带索引的方法
3.允许重复的元素
List接口中常用的带索引的方法有:
--public void add(int indesx,E element):将指定的元素,添加到该集合中的指定位置上
--public E get(int index):返回集合中指定位置的元素
--public E remove(int index):移除例表中指定位置的元素,返回的是被移除的元素
--public E set(int index,E element):用指定的元素替换集合中指定位置的元素,返回值的更新前的元素
注意:
操作索引的时候,一定防止索引越界
*/
public class Demo01List {
public static void main(String[] args) {
//创建一个List集合对象,多态,向上转型
List<String> list=new ArrayList<>();
//使用add ,可以添加重复元素
list.add("a");
list.add("a");
list.add("b");
list.add("c");
list.add("d");
System.out.println(list);//list接口中重写了toString()方法,有序的集合,存取顺序一致
System.out.println("===============");
//在指定位置添加元素
list.add(0,"justin");
System.out.println(list);
//移除元素返回的是被移除的元素
String remove = list.remove(0);//返回的是移除的元素
System.out.println(remove);
System.out.println(list);
//替换元素,返回被替换的元素
String b = list.set(3, "b");
System.out.println(b);
System.out.println(list);
//遍历集合取数
System.out.println("第一种遍历方法:");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("第二种遍历方法:");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println("第三种遍历方法:");
for(String s:list){
System.out.println(s);
}
}
}
List接口的实现类
ArrayList集合
- 底层是由byte[]实现的,在java 8之前是char[]数组实现的,根据之前我们学过的数据结构我们可以得知,ArrayList集合增删慢,查询速度较快,由于日常开发中使用最多的功能是查询数据,遍历数据,所以ArrayList是最常用的集合
- 但是非常随意的使用
ArrayList集合是不提倡的
LinkedList集合
- 底层数据结构是链表结构的,方便元素的添加,删除的集合,
LinkedList还是一个双向链表,是有序的,查询慢,增删快
import java.util.LinkedList;
import java.util.List;
/*
java.util.LinkedList集合 implements List接口
LinkedList集合的特点:(除了List的特点外,特有的特点)
1.底层是一个双向链表结构,查询慢,增删快
2.里面包含了大量操作首尾元素的方法
注意:使用LinkedList集合特有的方法,不能使用多态,但是可以向下转型
常用特有方法
--public void addFirst(E e):将指定的元素插入到此列表的开头
--public void addLast(E E):将指定元素添加到此列表的结尾,此方法等效于add()方法
--public void push(E e):将此方法推入此列表所表示的堆栈,此方法等效于addFirst()
--public E getFirst():返回此列表的第一个元素
--public E getLast():返回此列表的最后一个元素
--public E removeFirst():移除并返回此列表的第一个元素
--public E removeLast():移除并返回此列表的最后一个元素
--public E pop():从此列表所表示的堆栈中弹出第一个元素
--public Boolean isEmpty():如果此列表不包含元素,则返回true
*/
public class Demo02LinkedList {
public static void main(String[] args) {
demo1();
System.out.println("show02()方法开始执行:");
show02();
System.out.println("show03()方法开始执行了:");
show03();
}
private static void show03() {
LinkedList<String> objects = new LinkedList<>();
objects.add("oo");
objects.add("pp");
objects.add("qq");
objects.add("kk");
objects.add("ll");
//移除元素
String s = objects.removeFirst();
System.out.println(objects);//[pp, qq, kk, ll]
objects.removeLast();
System.out.println(objects);//[pp, qq, kk]
}
private static void show02() {
LinkedList<String> linkedList=new LinkedList<>();
linkedList.add("a");
linkedList.add("b");
linkedList.add("c");
linkedList.add("d");
//清空集合中的元素
linkedList.clear();
if(!linkedList.isEmpty()){
System.out.println(linkedList.getFirst());
System.out.println(linkedList.getLast());
}else{
System.out.println("集合中没有元素了!!!!");
}
}
private static void demo1() {
List<String> linkedList=new LinkedList();
//linkedList.addFirst();不能使用LinkedList特有的方法
//为了使用特有的方法使用向下转型
if(linkedList instanceof LinkedList){
LinkedList<String> ll=(LinkedList)linkedList;
ll.add("aaa");
ll.add("bbb");
ll.add("ccc");
ll.add("ddd");
ll.add("aaa");
System.out.println(ll);
ll.addFirst("www");
System.out.println(ll);//[www, aaa, bbb, ccc, ddd, aaa]
System.out.println("=====");
ll.push("www");
System.out.println(ll);//[www, www, aaa, bbb, ccc, ddd, aaa]
ll.addLast("baidu");
System.out.println(ll);//[www, www, aaa, bbb, ccc, ddd, aaa, baidu]
ll.add("baidu");
System.out.println(ll);//[www, www, aaa, bbb, ccc, ddd, aaa, baidu, baidu]
}
}
}
Vector集合
Vector类可以实现可增长的对象数组。从 Java 2 平台 v1.2 开始,此类改进为可以实现List接口,使它成为 Java Collections Framework 的成员。与新 collection 实现不同,Vector是同步的。
Set集合
Set接口的特点
- 不允许存储重复的数据
- 没有索引,没有带索引的方法,也不能使用普通的for循环遍历
java.util.Set接口继承Collection接口
Set接口的实现类
HashSet
- 不允许存储重复的元素
- 没有索引
- 是一个无序的集合,存储元素和取出元素的顺序可能不一致
- 底层是一个哈希表结构(查询的速度非常快)
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/*
*/
public class Demo01Set {
public static void main(String[] args) {
Set<String> set=new HashSet<>();
set.add("aaa");
set.add("aaa");//不能存储重复数据
set.add("bbb");
set.add("ccc");
//不能使用普通for循环遍历
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println("增强型for循环遍历:");
for(String s:set){
System.out.println(s);//aaa ccc bbb
System.out.println("增强型for循环的快捷键是set.for");
}
for (String s : set) {
System.out.println(s);
}
}
}
HashSet集合存储数据的结构(哈希表)
- 哈希值:是一个十进制的整数,有系统随机给出(就是对象的地址值,是一个逻辑地址,是模拟出来的地址,不是数据实际存储的物理地址)
- 在Object类有一个方法何以获取对象的哈希值
/*
int hashCode()返回该对象的哈希码值
public native int hashCode();
native 代表的是调用的是本地操作系统的方法
*/
public class Demo01HashCode {
public static void main(String[] args) {
Person person = new Person();
int i = person.hashCode();
System.out.println(i);//460141958
Person person1 = new Person();
int i1 = person1.hashCode();
System.out.println(i1);//1163157884
/*
toString中的源码:返回的是16进制的hashCode
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
*/
String s = person.toString();
String s1 = person1.toString();
System.out.println(s);//com.itheima.day14.demo03.Person@1b6d3586
System.out.println(s1);//com.itheima.day14.demo03.Person@4554617c
boolean equals = person.equals(person1);
System.out.println(equals);//false String 中重写了equals方法
/*
* String 类的哈希值
* String 类重写了Object类的hashCode方法
* */
String s2="abc";
String s3="abc";
boolean equals1 = s2.equals(s3);
System.out.println(equals1);//true 常量池的作用
System.out.println(s2.hashCode());//96354
System.out.println(s3.hashCode());//96354
//注意重地和通话两个字符串不同但是hashCode值是一样的
System.out.println("重地".hashCode());//1179395
System.out.println("通话".hashCode());//1179395
}
}
哈希表结构
- 初始容量为啥是16?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yXKMTh49-1591523106791)(C:\myNote\java_learning\HashSet集合的数据结构_哈希表.PNG)]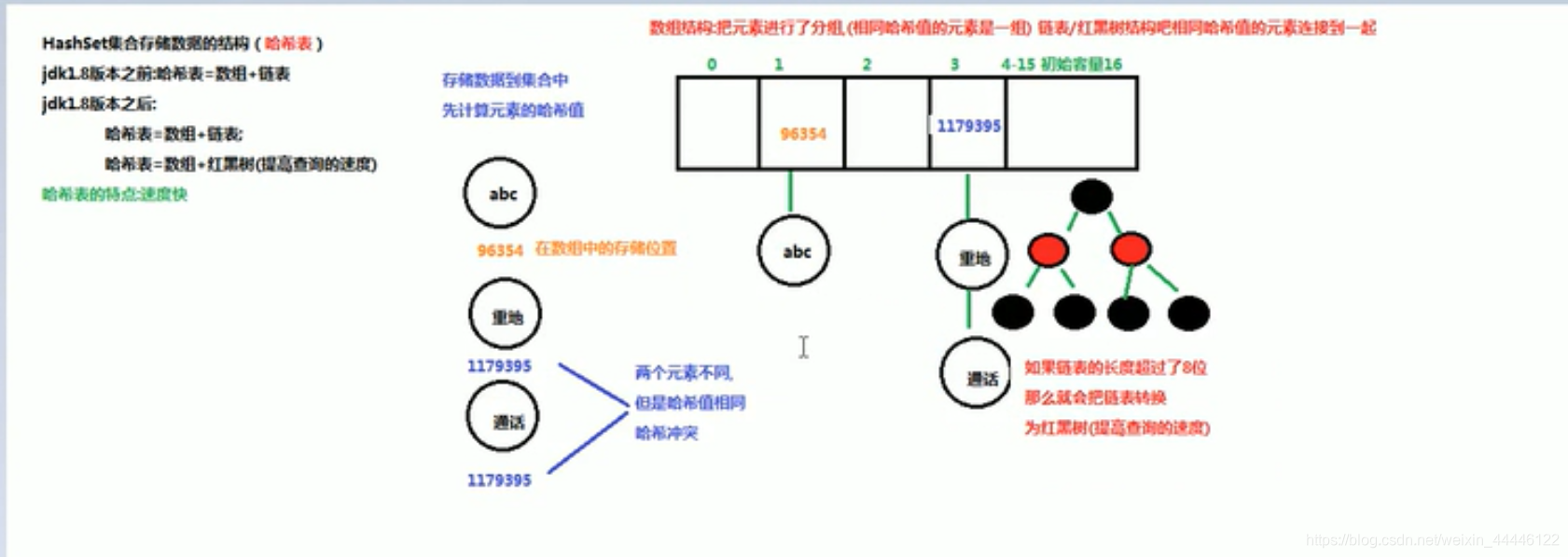
Set集合存储数据不重复的原理
- 前提:存储的元素必须重写果
hashCode()和equals()方法
import java.util.HashSet;
import java.util.Set;
/*
Set集合不允许存储重复数据的原理
*/
public class Demo02HashSetSaveString {
public static void main(String[] args) {
Set<String> set=new HashSet();
String s1=new String("abc");
String s2=new String("abc");
set.add(s1);
set.add(s2);
set.add("重地");
set.add("通话");
set.add("abc");
System.out.println(set);//[重地, 通话, abc]
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fo0nFVjC-1591523106793)(C:\myNote\java_learning\Set集合存储元素不重复的原理.PNG)]
HashSet存储自定义类型的数据
- 给
HashSet中存放自定义类型的元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet中的对象的唯一
import java.util.Objects;
public class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
//主函数
import java.util.HashSet;
/*
HashSet存储自定义类型元素
Set集合保存元素唯一
*/
public class Demo03HashSetSavePerson {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
Person p1 = new Person("rion",19);
Person p2 = new Person("julia",20);
Person p3 = new Person("rion",19);
set.add(p1);
set.add(p2);
set.add(p3);
//Person类没有重写toString方法,存储的时对象属性的地址值
System.out.println(set);//[com.itheima.day14.demo02.Person@74a14482, com.itheima.day14.demo02.Person@4554617c, com.itheima.day14.demo02.Person@1b6d3586]
System.out.println(set);//[Person{name='rion', age=19}, Person{name='julia', age=20}, Person{name='rion', age=19}] 可以看到有重复数据,这时还没有重写hashCode()和equals方法
System.out.println(p1.hashCode());//460141958
System.out.println(p3.hashCode());//460141958
System.out.println(p1.equals(p3));//false,在没有重写equals 方法前,equals和==等效
System.out.println(p1==p3);//false
System.out.println("重写equals和hashCode方法后:");
set.clear();
System.out.println(set);
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println(p1.equals(p3));//true
System.out.println(p1==p3);//false
System.out.println(p1.hashCode()==p3.hashCode());//true
System.out.println(p1.hashCode());//108520510
System.out.println(set);//[Person{name='rion', age=19}, Person{name='julia', age=20}] 没有重复数据了
}
}
LinkedHashSet
- java.util.LinkedHashSet集合继承HashSet集合
- LinkedHashSet集合的特点:底层是一个哈希表(数组+链表/红黑树)+链表,双向链表的结构,有序
import java.util.HashSet;
import java.util.LinkedHashSet;
public class Demo04LinkedHashSet {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("ddd");
set.add("bbb");
set.add("aaa");
set.add("ccc");
set.add("bbb");
System.out.println(set);//存取顺序不一致,是无序的[aaa, ccc, bbb, ddd],但是元素不重复
System.out.println("=======");
LinkedHashSet<String> linked = new LinkedHashSet<>();
linked.add("ddd");
linked.add("bbb");
linked.add("aaa");
linked.add("ccc");
linked.add("bbb");
System.out.println(linked);//[ddd, bbb, aaa, ccc] 存取顺序一致,有序,不重复
}
}
可变参数
- 在java1.5之后,如果我们定义一个方法需要接受多个参数,并且各个参数的类型一致,我们可以简化成如下格式:
修饰符 返回值类型 方法名(参数类型...形参名){
方法体
}
//等价于
修饰符 返回值类型 方法名(参数类型[] 形参名){},只是后面这种定义,在调用的时候必须传递数组,而前者可以直接传递数据即可
/*
可变参数:是JDK1.5之后出现的新特性
使用前提:
当方法的参数列表的类型是已经确定的,但是参数的个数不确定,就可以使用可变参数
使用格式:定义方法时使用
修饰符 返回值类型 方法名(数据类型...变量名){}
可变参数的原理:
可变参数底层就是一个数组,根据传递参数的个数的不同,会创建不同长度的数组,来存储这些参数,传递的参数个数可以时0个,1,2....
可变参数的注意事项
1.一个方法的参数列表,只能有一个可变参数
错误写法:
public static void method(int...a,String... b);
2.如果方法的参数有多个,那么可变参数必须写在参数列表的末尾
正确写法:
public static void method1(String a,double b,int d,int... e);
可变参数的特殊(终极)写法:
public static void method(Object... obj);
*/
public class Demo01VarArgs {
public static void main(String[] args) {
//传递一个参数
int add = add(1);
System.out.println(add);
System.out.println("====");
//求和
int i = add1(10, 20);//30
System.out.println(i);
System.out.println("=====");
int i1 = add2(10, 20, 30, 40, 50);
System.out.println(i1);//150
}
private static int add2(int... a) {
int sum=0;
for (int i : a) {
sum+=i;
}
return sum;
}
private static int add1(int... arr) {
int sum=0;
for (int i = 0; i < arr.length; i++) {
sum+=arr[i];
}
return sum;
}
private static int add(int... a) {
//传递0个参数
//System.out.println(a);//[I@1b6d3586 [代表数组,I代表整型
return 0;
}
//定义一个求0-n个整数的和
}
集合工具类Collections
-
常用方法
/* public static <T> boolean addAll(Collection<? super T> c, T... elements)//往集合中添加一些元素 public static void shuffle(List<?> list)//打乱集合中元素的顺序 public static <T extends Comparable<? super T>> void sort(List<T> list) //排序,默认升序,只能时List集合,sotr()方法使用的前提,被排序的集合里面存储的元素必须实现Comparaable,重写compareTo定义的排序的规则, Comparable接口的排序规则: 自己(this)-参数 升序 public static <T> void sort(List<T> list,Comparator<? super T> c)//Comparator和Comparable的区别 Comparable:自己(this)和别人(参数)进行比较,自己要实现Comparable接口,需要重写compareTo()方法,compareTo()比较方法其实是两两比较,所以this.age以后面的为准 Comparator:相当于找一个第三方的裁判,比较两个,相当于传两个参数进去打擂台 */import java.util.ArrayList; import java.util.Collections; public class Demo01Collections { public static void main(String[] args) { ArrayList<String> arr = new ArrayList<>(); //往集合中批量添加元素 Collections.addAll(arr,"1","2","3","4","5"); System.out.println(arr);//[1, 2, 3, 4, 5] //打乱集合中元素的顺序 Collections.shuffle(arr); System.out.println(arr);//[3, 2, 5, 1, 4] } } //工具类中的sort()方法 import java.util.ArrayList; import java.util.Collections; public class Demo02Sort { public static void main(String[] args) { ArrayList<String> arr = new ArrayList<>(); Collections.addAll(arr,"a","b","e","c","f"); System.out.println(arr);//[a, b, e, c, f] //排序后 Collections.sort(arr); System.out.println(arr);//[a, b, c, e, f] System.out.println("============="); //存储自定义的数据,需要实现 Comparable<T>接口,重写public int compareTo(T o);方法 ArrayList<Person> arr1 = new ArrayList<>(); arr1.add(new Person("rion",19)); arr1.add(new Person("julia",18)); arr1.add(new Person("justin",20)); System.out.println(arr1);//[Person{name='rion', age=19}, Person{name='julia', age=18}, Person{name='justin', age=20}] System.out.println("把arr1按照年龄升序排序后的结果如下:"); Collections.sort(arr1); System.out.println(arr1);//[Person{name='julia', age=18}, Person{name='rion', age=19}, Person{name='justin', age=20}] } } // public class Person implements Comparable<Person> { private String name; private int age; public Person() { } public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override //实现Comparable接口中的compareTo()方法 public int compareTo(Person o) { System.out.println("this.age的值是:"+this.age); System.out.println("0.getAge的值是:"+o.getAge()); return this.age-o.getAge();//升序 //return o.getAge()-this.age 降序 } }import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; /* java.util.Collections 是集合的工具类,用来对集合进行操作,部分方法如下 public static <T> void sort(List<T> list,Comparator<? super T> c) Comparator和Comparable的区别 Comparable:自己(this)和别人(参数)进行比较,自己要实现Comparable接口,需要重写compareTo()方法,compareTo()比较方法其实是两两比较,所以this.age以后面的为准 Comparator:相当于找一个第三方的裁判,比较两个,相当于传两个参数进去打擂台 */ public class Demo03Sort { public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); Collections.addAll(list,1,2,3,4,9,8,7,6,5); System.out.println(list);//[1, 2, 3, 4, 9, 8, 7, 6, 5] //使用匿名内部类 Collections.sort(list, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1-o2; } }); System.out.println(list);//[1, 2, 3, 4, 5, 6, 7, 8, 9] System.out.println("自定义对象进行排序:"); ArrayList<Student> list1 = new ArrayList<>(); Collections.addAll(list1,new Student("a迪丽热巴",18),new Student("b杨幂",18),new Student("杨幂",17),new Student("古力娜扎",20)); System.out.println(list1);//[Student{name='a迪丽热巴', age=18}, Student{name='b杨幂', age=18}, Student{name='杨幂', age=17}, Student{name='古力娜扎', age=20}] System.out.println("按照年龄进行升序排序,如果年龄相同按照首字母升序排序:"); Collections.sort(list1, new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { int i = o1.getAge() - o2.getAge();//年龄升序 if(i==0){ i = o1.getName().charAt(0) - o2.getName().charAt(0); } return i; } }); System.out.println(list1);//[Student{name='杨幂', age=17}, Student{name='a迪丽热巴', age=18}, Student{name='b杨幂', age=18}, Student{name='古力娜扎', age=20}] } } //Student类 public class Student { private String name; private int age; public Student(String name, int age) { this.name = name; this.age = age; } public Student() { } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } }
Map集合
Map集合和Collection集合的区别
Collection集合是单列集合,每次存储一个元素Collection<E>Map集合,元素是成对出现的,每个元素由键和值组成,键值是不能重复的,但是值是可以重复的,键和值是一一对应的关系,靠键来维护它们之间的关系
Map接口中常用的方法
import java.util.HashMap;
import java.util.Map;
public class Demo01Map {
public static void main(String[] args) {
show01();
System.out.println("remove()方法开始执行....");
show02();
System.out.println("get()方法开始执行....");
show03();
System.out.println("ContainsKey()方法开始执行....");
show04();
}
/*
boolean containsKey(Object key)判断集合中书否包含指定的键
包含返回true ,不包含返回false
*/
private static void show04() {
Map<String,Integer> map=new HashMap<>();
map.put("迪丽热巴",18);
boolean b = map.containsKey("迪丽热巴");
System.out.println(b);//true
boolean b1 = map.containsKey("马尔扎哈");
System.out.println(b1);//false
}
/*
public V get(Object key):根据指定的键,在Map集合中获取对应的值
返回值V
key 存在返回的是V,被删除的元素
key 不存在,返回null值
*/
private static void show03() {
Map<String,Integer> map=new HashMap<>();
map.put("迪丽热巴",18);
map.put("古力娜扎",19);
map.put("马尔扎哈",40);
Integer i = map.get("马尔扎哈");
System.out.println(i);//40
Integer i2 = map.get("rion");
System.out.println(i2);//null
}
/*
public V remove(Object key):把指定的键,所对应的键值对元素,在Map集合中删除,返回被删除元素的值
返回值V
key 存在返回的是V,被删除的元素
key 不存在,返回null值
*/
private static void show02() {
Map<String,Integer> map=new HashMap<>();
map.put("迪丽热巴",18);
map.put("古丽娜扎",19);
map.put("马尔扎哈",40);
//map.put("迪丽热巴",18); key值不允许重复
System.out.println(map);//{迪丽热巴=18, 古丽娜扎=19, 马尔扎哈=40}
Integer v = map.remove("迪丽热巴");
System.out.println(v);//18 返回被删除的Value值
Integer v2 = map.remove("迪丽热巴");
// int v3 = map.remove("迪丽热巴");//Integer-->int 自动拆箱,但是int NullPointerException报错,尽量使用包装类
System.out.println(v2);//null
// System.out.println(v3);
}
/*
public V put(K key,V value):把指定的键与值添加到Map集合中
返回值:V
如果key值不重复,就相当于添加了一个新的元素进去,返回null
如果key值已经存在了,会使用新的Value替换旧的Value,返回的是旧的Vaule
*/
private static void show01() {
Map<String, String> map = new HashMap<>();
String v = map.put("rion", "justin");
System.out.println(v);//null
String v2 = map.put("rion", "julia");
System.out.println("v2:"+v2);//justin 返回被替换的值
System.out.println(map);//{rion=julia} Map重写了toString()元素
map.put("冷风","龙小云");
map.put("杨过","小龙女");
map.put("尹志平","小龙女");
System.out.println(map);//{杨过=小龙女, rion=julia, 尹志平=小龙女, 冷风=龙小云} value 可以重复
}
}
Map集合遍历的方式
Set<K> keySet()
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
/*
Map集合的第一种遍历方式:通过键找值的方式
Map集合中的方法:
Set<K> keySet(),返回此映射中包含的Set视图
实现步骤:
1.使用Map集合中的方法KeySet(),把Map集合中所有的key取出来,存储到一个set集合中
2.遍历Set集合,获取Map集合中的每一个Key
3.通过Map集合中的get(key),通过key找到Value
*/
public class Demo02KeySet {
public static void main(String[] args) {
Map<String,String> map=new HashMap<>();
map.put("rion","J");
map.put("julia","K");
map.put("lucie","M");
System.out.println(map);//{rion=J, julia=K, lucie=M}
//1.使用Map集合中的方法KeySet(),把Map集合中所有的key取出来,存储到一个set集合中
Set<String> set = map.keySet();
//2.遍历Set集合,获取Map集合中的每一个Key,方法一使用迭代器
Iterator<String> it = set.iterator();
while(it.hasNext()){
String key = it.next();
String value = map.get(key);
System.out.println("key:"+key+" value:"+value);////key:rion value:J key:julia value:K key:lucie value:M
}
//使用增强for
System.out.println("使用增强型for循环遍历Set集合:");
for (String key : set) {
String value = map.get(key);
System.out.println("key:"+key+" value:"+value);//key:rion value:J key:julia value:K key:lucie value:M
}
}
}
Entry<K,V>
[外链图片转存失败,源站可能有防盗链机制,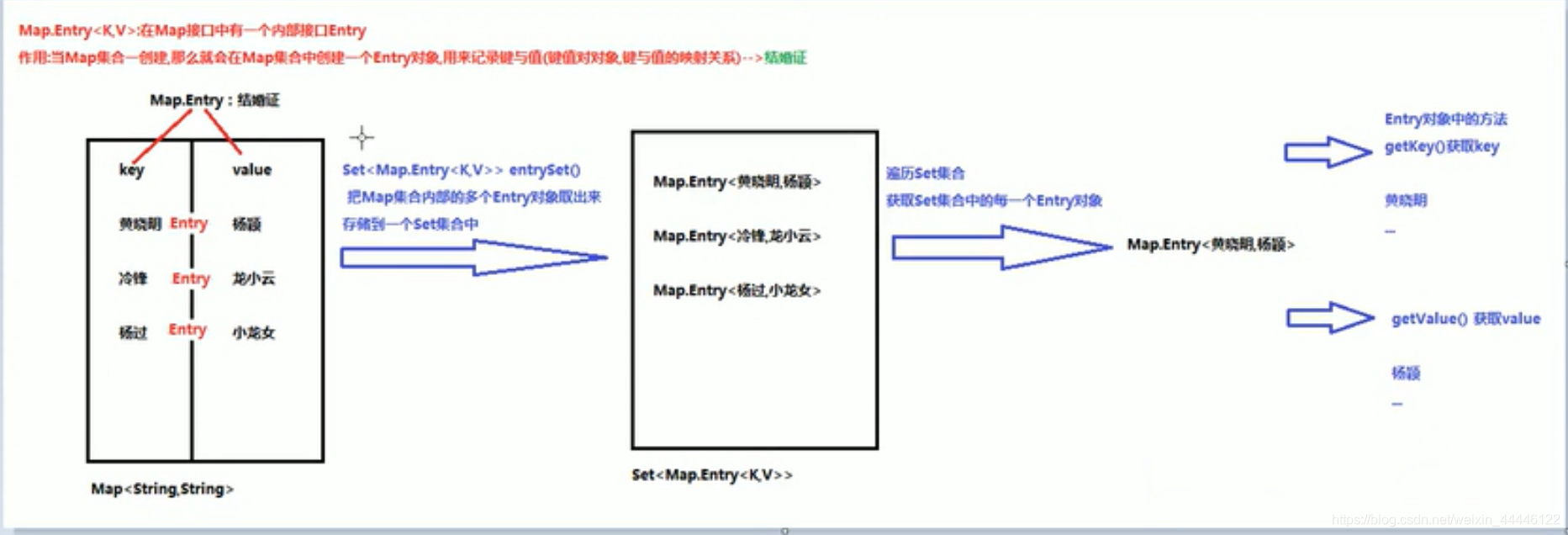 建议将图片保存下来直接上传(img-5zp8rrpc-1591523106794)(C:\myNote\java_learning\Entry键值对对象.PNG)]
建议将图片保存下来直接上传(img-5zp8rrpc-1591523106794)(C:\myNote\java_learning\Entry键值对对象.PNG)]
//MAP集合遍历的第二种方式
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
/*
Map集合的第二种遍历方式:使用Entry对象遍历
Map集合中的方法
Set<Map.Entry<K,V>> entrySet()
实现步骤:
1.使用Map集合中的方法entrySet(),把Map集合中多个Entry对象取出来,存储到一个Set集合当中
2.遍历Set集合,获取每一个Entry对象
3.使用Entry对象中的方法getKey()和getValue()获取键和值
*/
public class Demo03EntrySet {
public static void main(String[] args) {
Map<String,String> map=new HashMap<>();
//map.put("justin","A");
map.put("rion","J");
map.put("julia","K");
map.put("lucie","M");
System.out.println(map);
// 1.使用Map集合中的方法entrySet(),把Map集合中多个Entry对象取出来,存储到一个Set集合当中
Set<Map.Entry<String, String>> set = map.entrySet();
//2.遍历Set集合,获取每一个Entry对象
Iterator<Map.Entry<String, String>> it = set.iterator();
while(it.hasNext()){
Map.Entry<String, String> entry = it.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"="+value);//rion=J julia=K lucie=M
}
System.out.println("----------------------------------------------");
for(Map.Entry<String, String> entry:set) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"="+value);//rion=J julia=K lucie=M
}
}
}
Map接口的子类
HashMap
-
HashMap集合底层是哈希表,查询的速度非常快,在JDK1.8之前,数组+单向链表,JDK1.8之后数组+单向链表/红黑树(链表的长度超过8,链表就会被替换为红黑树),目的是为了提高查询的速度
-
HashMap是一个无序的集合,存储元素和取出元素的顺序可能不一致//HashMap存储自定义的数据 import java.util.HashMap; import java.util.Map; import java.util.Set; /* HashMap存储自定义的键值 Map集合需要保证key是唯一的, 作为Key的元素必须要保证重写hashCode()方法和equals方法,以保证key唯一,因为HashMap底层是哈希表,所以是不能重复的 */ public class Demo01HashMapSavePerson { public static void main(String[] args) { show01();//key 为String value 为Person System.out.println("===================="); show02();//Key为Student value 为String } private static void show02() { HashMap<Student, String> map = new HashMap<>(); map.put(new Student("rion",18),"J"); map.put(new Student("rion",18),"K"); map.put(new Student("julia",19),"J"); System.out.println(map); //遍历Map 使用entrySet Set<Map.Entry<Student, String>> set = map.entrySet(); for (Map.Entry<Student, String> entry : set) { String value = entry.getValue(); Student key = entry.getKey(); //重写前 System.out.println(key+"=="+value);//Student{name='julia', age=19}==J Student{name='rion', age=18}==K Student{name='rion', age=18}==J //重写hashCode 和equals方法后 //Student{name='rion', age=18}==K //Student{name='julia', age=19}==J } } private static void show01() { HashMap<String, Person> map = new HashMap<>(); map.put("japan",new Person("rion",18)); map.put("china",new Person("julia",19)); map.put("japan",new Person("julia",20)); //因为String 类重写了hashCode()和equals方法,记得要手动重写Person类的toString 方法 //使用keySet 遍历 Set<String> set = map.keySet(); for (String key : set) { Person value = map.get(key); System.out.println(key+"="+value);//china=Person{name='julia', age=19} japan=Person{name='julia', age=20} 将rion 18 替换掉了 } } } // public class Person { private String name; private int age; public Person() { } public Person(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } } // import java.util.Objects; public class Student { private String name; private int age; public Student() { } public Student(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Objects.equals(name, student.name); } @Override public int hashCode() { return Objects.hash(name, age); } }
LinkedHashMap
java.util.LinkedHashMap<K,V>集合继承HashMap<K,V>集合LinkedHashMap集合底层是哈希表+链表(保证迭代的顺序),双向链表,有序LinkedHashMap集合是一个有序的集合,存储元素的顺序和取出的顺序是一致的
import java.util.HashMap;
import java.util.LinkedHashMap;
/*
java.util.LinkedHashMap<K,v> extends HashMap<K,V>
底层原理:链表+哈希表,具有可预知的顺序
*/
public class Demo01LinkedHashMap {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put("a","a");
map.put("b","a");
map.put("c","a");
map.put("e","a");
map.put("d","a");
System.out.println(map);//{a=a, b=a, c=a, d=a, e=a} 存取顺序不一致
LinkedHashMap<String, String> linked = new LinkedHashMap<>();
linked.put("a","a");
linked.put("c","a");
linked.put("b","a");
linked.put("d","a");
linked.put("e","a");
System.out.println(linked);//{a=a, c=a, b=a, d=a, e=a} 存取数据一致
}
}
Hashtable
java.util.Hashtable<K,V>集合 implements Map<K,V>接口Hashtable底层也是一个哈希表,是一个线程安全的集合,是单线程集合,速度慢HashMap底层是一个哈希表,是一个线程不安全的集合,是多线程的集合,速度快HashMap集合之前所有的集合都可以存储null 值,包括键和value,Hashtable不能存储null值Hashtable和Vector集合一样,在jdk1.2版本之后被更先进的集合取代了(HashMap,ArrayList)- 要注意Hashtable的子类
Properties是一个唯一和IO流相结合的集合
import java.util.HashMap;
import java.util.Hashtable;
public class Demo02Hashtable {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put(null,null);
map.put("a",null);
map.put(null,"b");
System.out.println(map);//{null=b, a=null} Map集合是可以存放null值的
System.out.println("====================");
Hashtable<String, String> table = new Hashtable<>();
//table.put(null,null);//NullPointerException
}
}
Map集合练习
import java.util.HashMap;
import java.util.Iterator;
import java.util.Scanner;
import java.util.Set;
/*
计算一个字符串中每个字符出现的次数
分析
1.使用Scanner获取用户输入的字符串
2.创建Map集合,key是字符串中的字符,value是个数
3.遍历字符串,获取每一个字符
4.使用获取到的字符,去Map集合判断key值是否存在
key存在:
通过字符key,获取value(字符个数)
value++
put(key,value)把新的value存储到Map集合中
key不存在:
put(key,1)
5.遍历Map集合输出结果
*/
public class Demo03MapTest {
public static void main(String[] args) {
//1.使用Scanner获取用户输入的字符串
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个字符串");
String str = sc.next();
//2.创建Map集合,key是字符串中的字符,value是个数
HashMap<Character, Integer> map = new HashMap<>();
System.out.println(map);//{}此时map是空的
//遍历字符串
for(char c:str.toCharArray()){
if(map.containsKey(c)){
Integer value = map.get(c);
value++;
map.put(c,value);
}else{
map.put(c,1);
}
}
//遍历Map
Set<Character> set = map.keySet();
for (Character key : set) {
Integer value = map.get(key);
System.out.println(key+"="+value);
}
System.out.println("最后的map是:"+map);
System.out.println("使用迭代其进行遍历:");
Iterator<Character> it = map.keySet().iterator();
while (it.hasNext()){
Character key1 = it.next();
Integer value1 = map.get(key1);
System.out.println(key1+"="+value1);
}
}
}
JDK9新特性
List接口,Set接口,Map接口,里面新增了一个静态的方法of,可以给集合一次性添加多个元素- static List of (E… elements)
- 使用前提:当集合中存储的元素个数已经确定了,不在改变时使用
- of 方法只适用于List 接口,Set接口,Map接口,不适用于接口的实现类
- of 方法的返回值是一个不能改变的集合,集合不能再使用add,put方法添加元素,会抛出异常
- Set接口和Map接口在调用of方法的时候,不能有重复的元素,否则会抛出异常
Debug追踪
package com.itheima.day15.demo05;
/*
DeBug调试程序
可以让代码逐行进行执行,查看代码执行的过程,调试程序中出现的bug
使用方式:
在行号的右边,鼠标左键单击,添加断点
右键,选择Debug执行程序
程序就会停留在添加的第一个断点处
执行程序:
f8:逐行执行程序
f7:进入到方法中
shift+f8:跳出方法
f9:跳到下一个断点,如果没有下一个断点,那么就结束程序
ctr+f2:退出Debug模式,停止程序
console:切换到控制台
*/
public class Demo01Debug {
public static void main(String[] args) {
/*int a=10;
int b=20;
int sum=a+b;
System.out.println(sum);*/
/*for (int i = 0; i < 3; i++) {
System.out.println(i);
}*/
method();
}
private static void method() {
System.out.println("hello world");
System.out.println("hello world");
System.out.println("hello world");
System.out.println("hello world");
}
}
JDK9新特性
List接口,Set接口,Map接口,里面新增了一个静态的方法of,可以给集合一次性添加多个元素- static List of (E… elements)
- 使用前提:当集合中存储的元素个数已经确定了,不在改变时使用
- of 方法只适用于List 接口,Set接口,Map接口,不适用于接口的实现类
- of 方法的返回值是一个不能改变的集合,集合不能再使用add,put方法添加元素,会抛出异常
- Set接口和Map接口在调用of方法的时候,不能有重复的元素,否则会抛出异常
Debug追踪
package com.itheima.day15.demo05;
/*
DeBug调试程序
可以让代码逐行进行执行,查看代码执行的过程,调试程序中出现的bug
使用方式:
在行号的右边,鼠标左键单击,添加断点
右键,选择Debug执行程序
程序就会停留在添加的第一个断点处
执行程序:
f8:逐行执行程序
f7:进入到方法中
shift+f8:跳出方法
f9:跳到下一个断点,如果没有下一个断点,那么就结束程序
ctr+f2:退出Debug模式,停止程序
console:切换到控制台
*/
public class Demo01Debug {
public static void main(String[] args) {
/*int a=10;
int b=20;
int sum=a+b;
System.out.println(sum);*/
/*for (int i = 0; i < 3; i++) {
System.out.println(i);
}*/
method();
}
private static void method() {
System.out.println("hello world");
System.out.println("hello world");
System.out.println("hello world");
System.out.println("hello world");
}
}

















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









