







共享单车作为一种便捷的出行方式,有效缓解了“最后一公里”难题,同时促进了绿色出行。然而,在高峰时段,供需不均和停车难成为普遍挑战,尤其是在通勤时间,热门地点如地铁站附近和办公区常常面临车辆短缺或停车位紧张的问题。为解决这一矛盾,借助数据分析与智能调度系统显得尤为重要。
数据工程师在此过程中扮演关键角色,他们能通过挖掘多源数据,包括天气状况、节假日、工作日模式、特殊活动安排以及地理位置信息,来预测特定时间和地点的共享单车需求与停放空间需求。这一过程不仅涉及从网络抓取数据,如利用爬虫技术收集城市区域特征,还包括调用API接口获取实时天气数据,综合分析这些因素对共享单车使用行为的影响,从而实现更精准的车辆投放与调度策略。
本文将以共享单车调度与天气因素的关联为例,深入探讨如何结合网络数据抓取技术和API应用,从百科网站抓取城市基础数据,并利用气象API实时获取天气信息,以此为基础推导出共享单车运营的优化方案,确保在用户需求最旺盛的时刻和地点,实现共享单车资源的高效配置,同时优化停放管理,提升用户体验。
网络抓取与API调用:数据工程的工具箱
网络抓取是一种数字化的信息检索方式,它类似于在网络上获取数据的智能助手。想象一下,我们在杂志中寻找与人工智能、机器学习、网络安全等相关的信息,而不是手动记录这些词汇,我们可以使用网络抓取工具,例如 Python 爬虫工具 BeautifulSoup ,能够快速、高效地完成这项任务。
API 是软件应用程序间相互交互的规则和协议集合,它们在软件背后扮演着重要角色,实现了应用程序间无缝集成和数据共享。这就像餐馆的菜单,提供了可选择的菜品清单和详细描述,用户点菜就如同发出数据请求,而厨房则为之准备菜品。在这个类比中,API 就是菜单,而订单则是对数据的请求。
API 的应用场景多种多样:
- 服务之间的通信:不同软件系统能够相互通信。
- 数据获取:API 允许应用程序从服务器获取数据,为用户提供动态内容。
- 功能共享:它们还允许服务与其他应用程序共享其功能,比如地图集成到多个应用程序中的情况。
这些 API 之于软件的重要性不言而喻,它们促成了跨应用程序的交互和数据共享,为用户提供了更加丰富和便捷的体验。相比之下,网页抓取则是一种从网页中提取信息的方式,通常是将网页内容转化成可用的数据格式。虽然两者都涉及数据的获取和处理,但 API 更多地关注于应用程序间的交互和数据共享,而网页抓取则更专注于从网页中提取信息。
下图中展示了使用 GET 请求的客户端和 API 服务器之间的基本交互。理解这个过程对于了解数据在 Web 应用程序中的交换和利用至关重要。
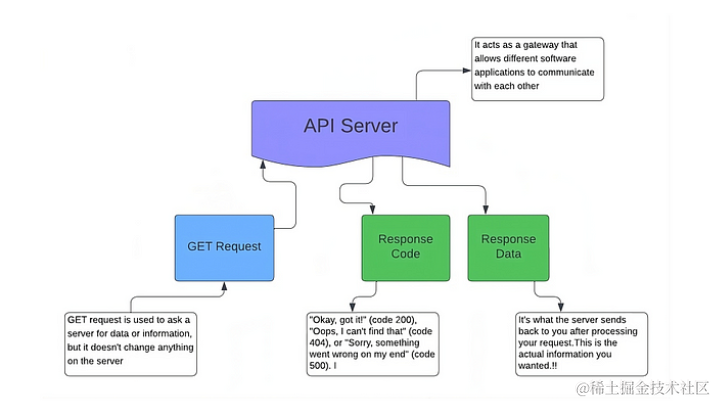
在此关系图的起点,API 服务器充当中介。它接收 GET 请求,对其进行处理,并根据请求的参数确定适当的响应。
GET 请求表示来自客户端(如网站或应用程序)向 API 服务器请求特定数据的查询,在请求之后,图中显示了服务器的响应。首先,发出响应代码,例如 200 表示成功,404 表示未找到。然后,返回响应数据,其中包含客户端请求的信息。
由此可以看出,API 与网页抓取的主要区别在于它们访问数据的方式:
- API 是访问数据的官方渠道。这就像有一张 VIP 通行证可以进入一场音乐会,在那里你可以直接获得某些信息。
- 另一方面,网络抓取就像坐在观众席上,记下正在播放的歌曲的歌词。这是一种无需使用官方 API 即可从网站提取数据的方法。
回到最开始提到的案例中。
城市信息可以从多个途径获取。一种方法是从官方统计等渠道的网站下载 CSV 文件。但要注意的是,城市信息可能会变动频繁,但网站更新的频率无法保障。
另一个方法是使用百科的数据。大量的用户在定期更新这些信息,所以只需要专注于选择正确的数据。
接下来,以使用 BeautifulSoup 进行网络抓取为案例。目标是什么?提取关键细节,例如名称、纬度、经度和人口数量,两个充满活力的城市:AAA 和 XXX。
此处作者使用的是 Jupyter Notebook 开发环境,对于交互式编程和数据可视化非常出色。当然,其他工具如 Atom、Visual Studio Code 或 IntelliJ IDEA 也有自己的优势。
分步Python指南:抓取数据实践
首先,让我们看一下用于推断 AAA 和 XXX 数据的代码。在本节中,将介绍构成项目骨干的 Python 库。
import requests
我们的第一个工具是 requests 库。这是互联网的关键——它帮助我们向网站发送 HTTP 请求。
from bs4 import BeautifulSoup
接下来,我们从 bs4 包中介绍 BeautifulSoup 。一旦我们有了目标网页,BeautifulSoup 就会解析 HTML 内容。
import pandas as pd
接下来是 pandas,这是数据科学中不可或缺的库。我们可以将抓取的数据转换为可读的表格,非常适合分析和可视化。
Python 中另一个常用的模块是 re 模块。它是一个用于处理正则表达式的库。
import reheaders = {
'Accept-Language': 'en-US,en;q=0.8'}
第一步是准备 Python 环境来接收来自web的数据。我们使用 requests 库来做到这一点,通过将“Accept-Language”设置为英语来确保我们的请求被普遍理解。
接下来,确定城市的 URL -AAA。这个 URL 将成为我们获取丰富信息的门户:
url_aaa = "https://en.wikipedia.org/wiki/aaa"
aaa = requests.get(url_aaa, headers=headers)
发送请求后,检查请求是否成功是至关重要的。状态码为 200 表示连接成功。
aaa.status_code # Should return 200
现在使用 BeautifulSoup 解析 AAA 的网页,将 HTML 内容转换为我们可以使用的格式。
soup_aaa = BeautifulSoup(aaa.content, "html.parser")
当提取特定数据时,就可以获得我们想要的结果:
- 检索到城市名称和国家,指向我们的研究主题
- 经纬度给了我们地理坐标
- 从人口数量可以看出城市的规模
下面是如何仔细检索这些细节的流程:
A_city = soup_aaa.select(".mw-page-title-main")[0].get_text()
A_country = soup_aaa.select('a[href="/wiki/CCC"]')[0].get_text()
A_latitude = soup_aaa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









