









1. Hudi概述
1.1 Hudi简介 What is Apache Hudi
Apache Hudi is the next generation streaming data lake platform. Apache Hudi brings core warehouse and database functionality directly to a data lake. Hudi provides tables, transactions, efficient upserts/deletes, advanced indexes, streaming ingestion services, data clustering/compaction optimizations, and concurrency all while keeping your data in open source file formats.
Apache Hudi 是下一代流式数据湖平台。Apache Hudi 将核心的数据仓库和数据库功能直接引入数据湖。Hudi 提供了表、事务、高效的更新/删除、先进的索引、流式摄取服务、数据聚类/压缩优化以及并发处理,同时保持数据在开源文件格式中。
行式存储: .avro
列式存储: .parquet
Not only is Apache Hudi great for streaming workloads, but it also allows you to create efficient incremental batch pipelines. Read the docs for more use case descriptions and check out who's using Hudi, to see how some of the largest data lakes in the world including Uber, Amazon, ByteDance, Robinhood and more are transforming their production data lakes with Hudi.
Apache Hudi 不仅适用于流式工作负载,还允许您创建高效的增量批处理管道。请阅读文档以获取更多用例描述,并查看谁在使用 Hudi,了解一些全球最大的数 据湖如何利用 Hudi 转型他们的生产数据湖,包括 Uber、亚马逊、字节跳动、Robinhood 等公司。
Apache Hudi can easily be used on any cloud storage platform. Hudi’s advanced performance optimizations, make analytical workloads faster with any of the popular query engines including, Apache Spark, Flink, Presto, Trino, Hive, etc.
Apache Hudi 可以轻松地在任何云存储平台上使用。Hudi 的高级性能优化可以加快与任何流行查询引擎(包括 Apache Spark、Flink、Presto、Trino、Hive 等)一起进行的分析工作负载。
2. 编译Hudi
2.1 编译环境准备
相关组件版本如下:
| Hadoop | 3.3.1 |
| Hive | 3.1.3 |
| Flink | 1.13.6,scala-2.12 |
| Spark | 3.3.1,scala-2.12 |
1)安装Maven
(1)上传apache-maven-3.6.1-bin.tar.gz到/opt/software目录,并解压更名
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /opt/module/
mv apache-maven-3.6.1 maven-3.6.1
(2)添加环境变量到/etc/profile中
sudo vim /etc/profile.d/my_env.sh
#MAVEN_HOME
export MAVEN_HOME=/opt/module/maven-3.6.1
export PATH=$PATH:$MAVEN_HOME/bin
(3)测试安装结果
source /etc/profile
mvn -v
2)修改为阿里镜像
(1)修改setting.xml,指定为阿里仓库地址
vim /opt/module/maven-3.6.1/conf/settings.xml
<!-- 添加阿里云镜像-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>2.2 下载源码包
https://github.com/apache/hudi/blob/release-0.12.3/README.md
wget https://dlcdn.apache.org/hudi/0.12.3/hudi-0.12.3.src.tgz
1)修改pom.xml,添加以下仓库地址:
<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>2)修改依赖的组件版本
<hadoop.version>3.3.1</hadoop.version>
<hive.version>3.1.3</hive.version>

2.3 编译命令
mvn clean package -DskipTests -Dspark3.3 -Dflink1.13 -Dscala-2.12 -Dhadoop.version=3.3.1 -Pflink-bundle-shade-hive3直接编译报错:
hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java

原因:hadoop2 和hadoop3兼容性问题
hadoop2 的API:

修改为hadoop3的API:

其他地方都不修改:





2.4 解决Spark模块依赖冲突
java.lang.AbstractMethodError: org.apache.hudi.org.apache.jetty.server.AllowedResourceAliasChecker$AllowedResourceAliasCheckListener.lifeCycleFailure(Lorg/apache/hudi/org/apache/jetty/util/component/LifeCycle;Ljava/lang/Throwable;)V

修改了Hive版本为3.1.3,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。
1)修改hudi-spark-bundle的pom文件,排除低版本jetty,添加hudi指定版本的jetty:
vim /opt/software/hudi-0.12.3/packaging/hudi-spark-bundle/pom.xml
<!-- Hive -->
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency><dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service-rpc</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
</dependency><dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency><dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
</dependency><dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
<scope>${spark.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency><!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
2)修改hudi-utilities-bundle的pom文件,排除低版本jetty,添加hudi指定版本的jetty:
vim /opt/software/hudi-0.12.3/packaging/hudi-utilities-bundle/pom.xml
修改如下(红色部分)
<!-- Hive -->
<dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>org.apache.hbase</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency><dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-service-rpc</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
</dependency><dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency><dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-metastore</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>org.apache.hbase</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
</dependency><dependency>
<groupId>${hive.groupid}</groupId>
<artifactId>hive-common</artifactId>
<version>${hive.version}</version>
<scope>${utilities.bundle.hive.scope}</scope>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency><dependency>
<groupId>org.apache.htrace</groupId>
<artifactId>htrace-core</artifactId>
<version>${htrace.version}</version>
<scope>compile</scope>
</dependency><!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
再次编译:
mvn clean package -DskipTests -Dspark3.3 -Dflink1.13 -Dscala-2.12 -Dhadoop.version=3.3.1 -Pflink-bundle-shade-hive3

3. 核心概念
3.1 基本概念
3.1.1 时间轴(TimeLine)

At its core, Hudi maintains a timeline of all actions performed on the table at different instants of time that helps provide instantaneous views of the table, while also efficiently supporting retrieval of data in the order of arrival. A Hudi instant consists of the following components
Hudi的核心是维护表上在不同的即时时间(instants)执行的所有操作的时间轴(timeline),这有助于提供表的即时视图,同时还有效地支持按到达顺序检索数据。一个instant由以下三个部分组成:
在其核心,Hudi维护了一个时间轴,记录了表在不同时间点上执行的所有操作,这有助于提供即时的表视图,同时还能高效地支持按到达顺序检索数据。Hudi的一个时间点包括以下组件。
instantaneous:即时的,瞬时的
instant:
n. 瞬息;顷刻;刹那;(某一)时刻
adj. 立即的;即刻的;速溶的;即食的;速食的;紧急的;紧迫的;迫切的;本月的;正在考虑中的
retrieval:[n.] 检索;恢复;取回;找回;恢复
Instant action: Type of action performed on the tableInstant time: Instant time is typically a timestamp (e.g: 20190117010349), which monotonically increases in the order of action's begin time.state: current state of the instant
即时行动:在表上执行的某种操作;
即时时间:通常是一个时间戳(例如:20190117010349),它按照动作开始时间的顺序单调递增。
状态:instant当前的状态。monotonically:adv.单音调地;音调不变地;单调地
Hudi guarantees that the actions performed on the timeline are atomic & timeline consistent based on the instant time.
Hudi保证在时间轴上执行的操作基于即时时间是原子且时间一致的。
Key actions performed include
COMMITS- A commit denotes an atomic write of a batch of records into a table.CLEANS- Background activity that gets rid of older versions of files in the table, that are no longer needed.DELTA_COMMIT- A delta commit refers to an atomic write of a batch of records into a MergeOnRead type table, where some/all of the data could be just written to delta logs.COMPACTION- Background activity to reconcile differential data structures within Hudi e.g: moving updates from row based log files to columnar [kəˈlʌmnə] formats. Internally, compaction manifests as a special commit on the timelineROLLBACK- Indicates that a commit/delta commit was unsuccessful & rolled back, removing any partial files produced during such a writeSAVEPOINT- Marks certain file groups as "saved", such that cleaner will not delete them. It helps restore the table to a point on the timeline, in case of disaster/data recovery scenarios.
主要的操作(Actions)包括:
- 提交(COMMITS)- 提交表示将一批记录原子性地写入表中。
- 清理(CLEANS)- 用于清除表中不再需要的旧文件版本的后台活动。
- 增量提交(DELTA_COMMIT)- 增量提交指的是将一批记录原子性地写入MergeOnRead类型的表中,其中部分或全部数据可能刚刚写入增量日志。
- 压缩(COMPACTION)- 后台活动,用于协调Hudi中的差异数据结构,例如将更新操作从基于行的日志文件合并到列式存储的数据文件中。在内部,Compaction表现为时间轴上的特殊提交。
- 回滚(ROLLBACK)- 表示提交/增量提交失败并回滚,删除在此类写入期间生成的任何部分文件。
- 保存点(SAVEPOINT)- 将某些文件组标记为“已保存”,以便清理器不会删除它们。它有助于在发生灾难需要数据恢复场景中将表恢复到时间轴上的某个点。
denote:vt. 表示;表明;代表;象征;意思是
reconcile [ˈrekənˌsaɪl]:vt.使接受;使顺从;使甘心于;使和解;使和好;使一致;使和谐;使(遭亵渎的教堂等)再次圣化。vi.和解;和好
Any given instant can be in one of the following states
REQUESTED- Denotes an action has been scheduled, but has not initiatedINFLIGHT- Denotes that the action is currently being performedCOMPLETED- Denotes completion of an action on the timeline
任何instant都处于以下状态之一:
REQUESTED——表示某个action已经调度,但尚未启动;
INFLIGHT——表示动作目前正在执行中;
COMPLETED——表示时间轴上的动作已完成。
两个时间概念:区分两个重要的时间概念:
Arrival time: 数据到达 Hudi 的时间,commit time。
Event time: record 中记录的时间。

上图中采用时间(小时)作为分区字段,从 10:00 开始陆续产生各种 commits,10:20 来了一条 9:00 的数据,根据event time该数据仍然可以落到 9:00 对应的分区,通过 timeline 直接消费 10:00 (commit time)之后的增量更新(只消费有新 commits 的 group),那么这条延迟的数据仍然可以被消费到。
Example above shows upserts happenings between 10:00 and 10:20 on a Hudi table, roughly every 5 mins, leaving commit metadata on the Hudi timeline, along with other background cleaning/compactions. One key observation to make is that the commit time indicates the arrival time of the data (10:20AM), while the actual data organization reflects the actual time or event time, the data was intended for (hourly buckets from 07:00). These are two key concepts when reasoning about tradeoffs between latency and completeness of data.
上述示例显示,在Hudi表上发生了UPSERT操作,时间范围是10:00到10:20,大约每5分钟一次,并在Hudi时间轴上留下了提交元数据,以及其他后台清理/压缩。一个关键的观察点是,提交时间指示了数据到达的时间(上午10:20),而实际的数据组织反映了数据意图所在的实际时间或事件时间(从07:00开始的小时桶)。这是关于数据延迟和完整性的权衡时需要考虑的两个关键概念。
When there is late arriving data (data intended for 9:00 arriving >1 hr late at 10:20), we can see the upsert producing new data into even older time buckets/folders. With the help of the timeline, an incremental query attempting to get all new data that was committed successfully since 10:00 hours, is able to very efficiently consume only the changed files without say scanning all the time buckets > 07:00.
当有延迟到达的数据(预期9点到达的数据在10点20晚到达>1小时)时,我们可以看到upsert将新数据生成到更早的时段/文件夹中。在时间轴的帮助下,一个增量查询可以高效地获取自10点以来成功提交的所有新数据,只需要消费发生变化的文件即可,而不需要扫描所有大于7点的时间桶。
3.1.2 文件布局(File Layout)
Hudi将一个表映射为如下文件结构:

The following describes the general file layout structure for Apache Hudi
- Hudi organizes data tables into a directory structure under a base path on a distributed file system
- Tables are broken up into partitions
- Within each partition, files are organized into file groups, uniquely identified by a file ID
- Each file group contains several file slices
- Each slice contains a base file (.parquet) produced at a certain commit/compaction instant time, along with set of log files (.log.*) that contain inserts/updates to the base file since the base file was produced.
Hudi adopts Multiversion Concurrency Control (MVCC), where compaction action merges logs and base files to produce new file slices and cleaning action gets rid of unused/older file slices to reclaim space on the file system.
以下描述了 Apache Hudi 的一般文件布局结构:
- Hudi 将数据表组织成分布式文件系统上一个基础路径下的目录结构。
- 表被划分为多个分区。
- 在每个分区内,文件被组织成文件组,每个文件组由一个唯一的文件 ID 标识。
- 每个文件组包含多个文件切片。
- 每个切片包含一个基文件(.parquet),该文件是在某个提交/压缩瞬间生成的,以及一组日志文件(.log.*),这些日志文件包含自基文件生成以来对基文件的插入/更新。
Hudi 采用多版本并发控制(MVCC),其中压缩操作将日志和基文件合并以生成新的文件切片,而清理操作则移除未使用的/旧的文件切片,以回收文件系统上的空间。
adopt: vt.
(承)认…为有某种关系的人;(尤指)收养,领养;收养;领养;采取;采纳;使用;摆出;采用;使用;选定;选用;批准;通过;接受…为候选人
Hudi存储分为两个部分:
(1)元数据:.hoodie目录对应着表的元数据信息,包括表的版本管理(Timeline)、归档目录(存放过时的instant也就是版本),一个instant记录了一次提交(commit)的行为、时间戳和状态,Hudi以时间轴的形式维护了在数据集上执行的所有操作的元数据;
(2)数据:和hive一样,以分区方式存放数据;分区里面存放着Base File(.parquet)和Log File(.log.*);

(1)Hudi将数据表组织成 分布式文件系统基本路径(basepath)下的目录结构;
(2)表被划分为多个分区,这些分区是包含该分区的数据文件的文件夹,类似于Hive表;
(3)在每个分区中,文件被组织成文件组,每个文件组由一个唯一的文件ID标识;
(4)每个文件组包含多个文件切片(FileSlice)
(5)每个文件切片包含:
1)一个基本文件(.parquet):在某个commit/compaction 瞬时时间(instant time)生成的(MOR表可能没有);
2)多个日志文件(*.log.*):这些日志文件包含自生成基本文件以来对基本文件的插入/更新(COW表没有)
(6)Hudi采用了多版本并发控制(MVCC:Mutilversion Concurrency Control)
1)compaction操作:合并日志和基本文件产生新的文件片;
2)clean操作:清楚不使用的/旧的文件片以回收文件系统上的空间。
(7)Hudi每个文件的文件名都带有其归属的 FileID(即 FileGroup Identifier)和 base commit time(即 InstanceTime)。通过文件名的 group id 组织 FileGroup 的 logical 关系;通过文件名的 base commit time 组织 FileSlice 的逻辑关系。
(8)Hudi的base file(parquet 文件)在footer的meta去记录了record key组成的BloomFilter,用于在file based index的实现中实现高效率的key contains检测。只有不在BloomFilter的key才需要扫描整个文件消灭假阳。(当一个 key不在这个 BloomFilter中时,意味着它绝对不存在于文件中,因此需要扫描整个文件来查找这个 key就可以了。相反,如果一个 key在 BloomFilter中,那么它很可能存在于文件中,因此只需要扫描包含该值的行即可。这种方式可以大大提高查询效率和性能)
(9)Hudi的log(avro文件)是自己编码的,通过积攒数据buffer以LogBlock为单位写出,每个LogBlock包含magic number/size/content/footer等信息,用于数据读/校验和过滤。
3.1.3 索引(Index)
1) 原理
Hudi通过索引机制提供高效的upsets,具体是将给定的hoodie key(record key + partition path) 与文件id(文件组)建立唯一映射.这种映射关系,数据第一次写入文件后保持不变,所以,一个FileGroup包含了一批record的所有版本记录.Index用于区分消息是INSERT还是UPDATE.
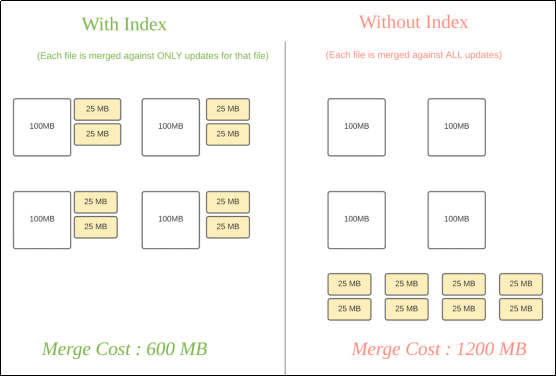
Hudi为了消除不必要的读写,引入了索引的实现.在有了索引之后,更新的数据可以快速被定位到对应的FileGroup.上图为例,白色是基本文件,黄色是更新数据,有了索引机制,可以做到:避免读取不需要的文件,避免更新不必要的文件,无需将更新数据与历史数据做分布式关联,只需要在FileGroup内做合并.
2) 索引选项
| Index类型 | 原理 | 优点 | 缺点 |
| Bloom Index | 默认配置,使用布隆过滤器来判断记录存在与否,也可选使用record key的范围裁剪需要的文件 | 效率高,不依赖外部系统,数据和索引保持一致性 | 因假阳性问题,还需要回溯原文件查找一遍 |
| Simple Index | 把update/delete操作的新数据和老数据进行join | 实现最简单,无需额外的资源 | 性能比较差 |
| HBase Index | 把Index存放在HBase里面.在插入FileGroup定位阶段所有Task向HBase发送Batch Get请求,获取Record Key的Mapping信息 | 对于小批次的keys,查询效率高 | 需要外部的系统,增加了运维压力 |
| Flink State-based Index | Hudi在0.8.0版本中实现的Flink Writer,采用了Flink的State作为底层的Index存储,每个records在写入之前会先计算目标Bucket ID. | 不同于BloomFilter Index,避免了每次重复的文件Index查询 | 如果索引过大,那么Flink的状态就会很大影响Flink的checkpoint,从而影响Flink对资源的使用. |
注意: Flink只有一种State based Index,其他Index是 Spark可选配置.
3) 全局索引和非全局索引
全局索引:全局索引在全表的所有分区范围下强制要求键的唯一性,也就是确保对给定的键有且只有一个对应的记录.全局索引提供了更强的保证,但是随着表增大,update/delete操作损失的性能越高,因此更适用于小表.
非全局索引:默认的索引实现,只能保证数据在分区的唯一性.非全局索引依靠写入器为同一个记录的update/delete提供一致的分区路径,同时大幅提高了效率,更适用于大表.
从Index的维护成本和写入性能的角度考虑,维护一个global Index的难度更大,对写入性能的影响也更大,所以需要non-global Index.
HBase索引本质上是一个全局索引,Bloom和Simple Index 都有全局选项:
hoodie.index.type=GLOBAL_BLOOM
hoodie.index.type=GLOBAL_SIMPLE
4) 索引的选择策略
(1) 对事实表的延迟更新
许多公司会在NoSQL数据存储中存放大量的交易数据.例如共享出行的行程表,股票买卖的记录的表,和电商的订单表.这些表通常一直在增长,且大部分的更新随机发生在较新的记录上,而对旧记录有着长尾分布型的更新.这通常是源于交易关闭或者数据更正的延迟性.换句话说,大部分更新会发生在最新的几个分区上而小部分会在旧的分区.
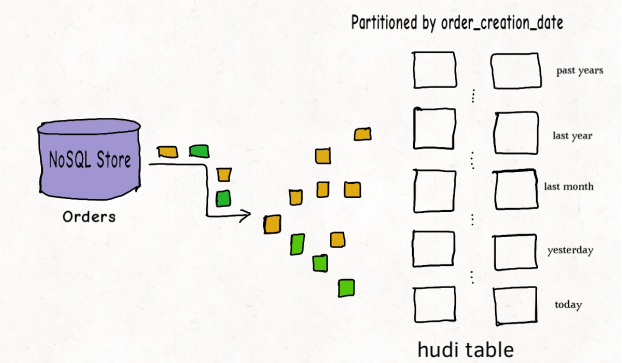
对于这样的作业模式,布隆索引就能表现地很好,因为查询索引可以靠设置得当的布隆过滤器来裁剪很多数据文件.另外,如果生成的键可以以某种顺序排列,参与比较的文件数会进一步通过范围裁剪而减少.Hudi用所有文件的键域来构造区间树,这样能高效地依据输入的更删记录的键域来排除不匹配的文件
3.1.4 表类型(Table Types)
3.1.5 查询类型(Query Types)
3.2 数据写
3.2.1 写操作
3.2.2 写流程(UPSERT)
3.2.3 写流程(INSERT)
3.2.4 写流程(INSERT OVERWRITE)
3.2.5 Key生成策略
3.2.6 删除策略
3.2.7 总结
3.3 数据读
3.3.1 Snapshot读
3.3.2 Incremental读
3.3.3 Streaming读
3.4 Compaction
4. 集成Spark
4.1 环境准备
4.2 spark-shell 方式
1)启动命令
# Spark 3.3
spark-shell \
--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.3 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
# Spark 3.2
spark-shell \
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.12.3 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
# Spark 3.1
spark-shell \
--packages org.apache.hudi:hudi-spark3.1-bundle_2.12:0.12.3 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
# Spark 2.4
spark-shell \
--packages org.apache.hudi:hudi-spark2.4-bundle_2.11:0.12.3 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
Please note the following
- For Spark 3.2 and above, the additional spark_catalog config is required: --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
- We have used hudi-spark-bundle built for scala 2.12 since the spark-avro module used can also depend on 2.12.
2)设置表名,基本路径和数据生成器
// spark-shell
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator存储选择对象存储:
// spark-shell
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
val tableName = "hudi_trips_cow"
val basePath1 = "obs://bigdata-teach/tmp/hudi_trips_cow"
val dataGen = new DataGeneratorThe DataGenerator can generate sample inserts and updates based on the the sample trip schema here.
hudi-spark-datasource/hudi-spark/src/main/java/org/apache/hudi/QuickstartUtils.java
3)Create Table
// scala
// No separate create table command required in spark. First batch of write to a table will create the table if not exists.
4)插入数据
新增数据,生成一些数据,将其加载到DataFrame中,然后将DataFrame写入Hudi表。
// spark-shell
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath1)Mode(overwrite)将覆盖重新创建表(如果已存在)。可以检查/tmp/hudi_trps_cow 路径下是否有数据生成。
We provided a record key (
uuidin schema), partition field (region/country/city) and combine logic (tsin schema) to ensure trip records are unique within each partition. For more info, refer to Modeling data stored in Hudi and for info on ways to ingest data into Hudi, refer to Writing Hudi Tables. Here we are using the default write operation :upsert. If you have a workload without updates, you can also issueinsertorbulk_insertoperations which could be faster. To know more, refer to Write operations .我们提供了一个记录键(Schema中的uuid)、分区字段(地区/国家/城市)和组合逻辑(Schema中的ts),以确保每个分区内的行程记录是唯一的。有关更多信息,请参阅Hudi中存储的数据建模,以及有关将数据导入Hudi的方法,请参阅编写Hudi表。在这里,我们使用默认的写操作:upsert。如果您的工作负载没有更新操作,您还可以使用insert或bulk_insert操作,这可能更快。要了解更多信息,请参阅写操作。
4.3 spark-sql方式
# Spark 3.3
spark-sql --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.3 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
create table hudi_cow_pt_tbl (
id bigint,
name string,
ts bigint,
dt string,
hh string
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'ts'
)
partitioned by (dt, hh)
location 'obs://bigdata-test1233/tmp/tmp/hudi/hudi_cow_pt_tbl';
spark-sql (default)> show create table hudi_cow_nonpcf_tbl;
createtab_stmt
CREATE TABLE default.hudi_cow_nonpcf_tbl (
_hoodie_commit_time STRING,
_hoodie_commit_seqno STRING,
_hoodie_record_key STRING,
_hoodie_partition_path STRING,
_hoodie_file_name STRING,
uuid INT,
name STRING,
price DOUBLE)
USING hudi
LOCATION 'obs://bigdata-test1233/tmp/tmp/hudi/hudi_cow_pt_tbl'
TBLPROPERTIES (
'primaryKey' = 'uuid',
'type' = 'cow')

insert into hudi_cow_nonpcf_tbl select 1, 'a1', 20;






















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









