







G:\Java\1.JavaSE
1.Java入门介绍
2.变量_类型转换_运算符
3.流程控制
4.数组
5.方法
6.面向对象
7.异常
8.常用API
9.多线程
10.集合
11.IO流
12.网络编程
13.正则表达式
14.设计模式
15.JDK新特性
16.反射_注解
面向对象内容的三条主线:
1.Java类及类的成员:属性,方法,构造器,代码块,内部类
2.面向对象的特征:封装,继承,多态,(抽象)
3.其他关键字的使用:this,super,package,import,static,final,interface,abstract.
1. 面向对象的概述
面向对象,是软件开发中的一类编程风格、开发范式(函数式编程、面向对象、面向过程)。
面向过程编程思想:Process-Oriented Programming,简称POP
面向对象编程思想:Object-Oriented Programming,简称OOP,面向对象可以帮助我们从宏观上把握、从整体上分析整个系统。把复杂的步骤和功能进行封装,封装时根据不同的功能进行不同的封装,功能类似的封装在一起。
函数式编程思想:Functional Programming
1.1 程序设计的思路
面向过程的程序设计思想(Process-Oriented Programming),简称POP
面向过程的程序设计思想强调将程序分解为一系列的过程或函数。程序的主要结构是由函数调用组成,数据和操作通常是分开的。它适合于任务明确且可以通过步骤逐步执行的问题。主要特点包括:
- 模块化:程序通过函数模块进行组织,便于管理和复用。
- 顺序执行:程序的控制流通常是线性的,从上到下依次执行。
- 状态变化:通过函数对数据状态进行修改,强调操作的顺序性。
面向对象的程序设计思想(Object-Oriented Programming, OOP)
面向对象的程序设计思想将程序设计视为对象的集合。这些对象包含状态(数据)和行为(方法),通过对象之间的交互来构建程序。主要特点包括:
- 封装:将数据和操作封装在对象内部,限制对内部状态的直接访问。
- 继承:允许创建新类(子类)以继承现有类(父类)的属性和方法,促进代码重用。
- 多态:对象可以以不同的方式响应相同的方法调用,增加灵活性和可扩展性。
函数式编程思想(Functional Programming, FP)
函数式编程思想强调使用纯函数和不可变数据结构来构建程序。它关注函数的应用和组合,避免了状态和变化的副作用。主要特点包括:
- 纯函数:函数输出仅依赖于输入参数,没有副作用,确保函数行为的可预测性。
- 不可变性:数据结构一旦创建就不可更改,减少了由于状态变化引起的错误。
- 高阶函数:可以将函数作为参数传递或返回函数,支持更高层次的抽象和组合。
2. Java语言的基本元素:类和对象
类(Class)和对象(Instance)是面向对象的核心概念。
2.1 引入
Java是一种面向对象的编程语言,其核心概念包括类和对象。类是对象的蓝图或模板,而对象是类的实例。通过类和对象,Java允许程序员以更加模块化和可维护的方式进行软件开发。
类:类定义了对象的属性(数据成员)和行为(方法)。它提供了创建对象的结构和规范。类可以包含字段、方法、构造函数等,是Java程序的基本构建块。
对象:对象是类的具体实例,包含了类定义的属性和方法。每个对象都有其独特的状态,并可以通过调用方法来执行特定的操作。对象之间可以相互交互,实现复杂的功能。
通过类和对象,Java实现了封装、继承和多态等面向对象的特性,使得程序更加灵活和易于扩展。这种结构化的方法使得大型软件系统的开发和维护变得更加高效。
2.2 类和对象概述
1、什么是类
具有相同特征的事物的抽象描述,是抽象的、概念定义。
在Java中,类是面向对象编程的基本构建块,是创建对象的蓝图或模板。类定义了一组属性(数据字段)和行为(方法),这些属性和行为共同描述了对象的特征和功能。
类的主要组成部分:
属性(Fields):属性是类的变量,用于存储对象的状态。每个对象可以拥有不同的属性值。
方法(Methods):方法是类中定义的函数,描述对象可以执行的操作。方法可以操作对象的属性并实现特定的功能。
构造函数(Constructors):构造函数是特殊的方法,用于创建和初始化对象。当使用
new关键字实例化类时,构造函数会被调用。访问修饰符:类、属性和方法可以使用访问修饰符(如
public、private、protected)来控制其可见性和访问权限。
2、什么是对象
在Java中,对象是类的一个具体实例。它是根据类定义的蓝图创建的,包含了类中定义的属性和方法。对象是面向对象编程的核心概念之一,能够表示现实世界中的实体或抽象概念。
对象的主要特点:
状态:对象的状态由其属性(字段)决定。每个对象可以有不同的属性值,代表该对象的具体状态。
行为:对象的行为由其方法定义。通过调用对象的方法,可以执行特定的操作,改变对象的状态或与其他对象进行交互。
身份:每个对象在内存中都有一个唯一的身份,即使两个对象具有相同的属性值,它们仍然是不同的对象。
2.3 类的成员概述
面向对象程序设计的重点是类的设计。
类的设计,其实就是类的成员设计。
类的成员:
1.属性,成员变量,field(字段,域)。
2.方法,函数,method。
在Java中,类的成员主要包括属性(字段)、方法、构造函数和内部类。每个成员都有其特定的作用,共同构成了类的功能和特性。
1. 属性(Fields)
属性是类中的变量,用于存储对象的状态。每个对象可以有不同的属性值。
- 定义:通常在类的顶部定义,具有特定的数据类型。
- 访问修饰符:可以使用
private、public、protected等修饰符控制属性的访问权限。public class Car { private String color; // 属性 private String model; // 属性 }2. 方法(Methods)
方法是类中定义的函数,描述对象可以执行的操作。方法可以访问和修改对象的属性。
- 定义:方法可以有参数和返回值。
- 访问修饰符:与属性类似,方法也可以使用访问修饰符来控制可见性。
public void displayInfo() { System.out.println("Model: " + model + ", Color: " + color); }3. 构造函数(Constructors)
构造函数是特殊的方法,用于创建和初始化对象。构造函数的名称与类名相同,并且没有返回值。
- 重载:可以定义多个构造函数,以不同的参数列表实现对象的不同初始化方式。
public Car(String color, String model) { this.color = color; this.model = model; }4. 内部类(Inner Classes)
内部类是定义在另一个类内部的类,可以访问外部类的成员。它们用于逻辑上相关的类的组合,增强封装。
public class Car { // 内部类 public class Engine { private int horsepower; public Engine(int horsepower) { this.horsepower = horsepower; } public void start() { System.out.println("Engine started with horsepower: " + horsepower); } } }总结
类的成员包括属性、方法、构造函数和内部类。它们共同定义了类的结构和功能,使得类能够封装数据和行为,支持面向对象编程的原则,如封装、继承和多态。这种组织方式有助于提高代码的可读性、可维护性和复用性。
2.3.1 成员变量
1. 变量的分类
按照数据类型:基本数据类型(8种)、引用数据类型(数组、类、接口、枚举、注解、记录)
按照变量在类中声明的位置:成员变量(或属性),局部变量(方法内,方法形参,构造器内,构造器形参,代码块内)
2.属性的几个称谓:成员变量,属性,字段,域,field。
3.区分成员变量 VS 局部变量
3.1 相同点:
> 变量声明格式相同:数据类型 变量名 = 变量值;
> 变量都有其作用域,出了作用域无效
> 变量必须先声明,后赋值,再使用。
3.2 不同点
(1)类中声明的位置不同:
成员变量,类属性:声明在类顶层,方法外的变量。
局部变量:声明在方法内、方法形参,构造器内,构造器形参,代码块内。
(2)在内存中分配的位置不同:
属性:随着对象的创建,存储在堆空间中。
局部变量:存储在栈空间中。
(3)声明周期不同:
属性:随着对象的创建而创建,随着对象的消亡而消亡。
局部变量:随着方法对应的栈帧入栈,局部变量会在栈中分配;随着方法的栈帧出栈,局部变量消亡。
(4)作用域:
属性:在整个类的内部都是有效的。
局部变量:仅限于声明此局部变量所在的方法(构造器,代码块)中。
(5)是否可以有权限修饰符进行修饰:
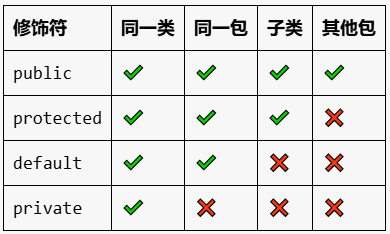
权限修饰符:public,缺省(default),protected,private
属性:可以使用权限修饰符进行修饰。
局部变量:不能使用权限修饰符进行修饰。
(6)是否有默认值。
属性:都有默认初始化值。
局部变量:都没有默认初始化值。意味着在使用局部变量之前,必须要显式的赋值,否则报错。
2.3.2 成员方法
- 方法是类或对象行为特征的抽象,用来完成某个功能操作,在某些语言中也称为函数或过程。
- 将功能封装为方法的目的是,可以实现代码重用,减少冗余,简化代码。
- Java里的方法不能独立存在,所有的方法必须定义在类里。
1. 方法声明的格式:
权限修饰符 [其他修饰符] 返回值类型 方法名(形参列表)[throws | extends | implement] {
方法体
}
2.权限修饰符
(1)Java规定的权限修饰符:private,(缺省),protected,public
3.返回值类型:描述当调用完此方法时,是否需要返回一个结果。
> 无返回值类型:使用 void 表示。
> 有具体的返回值类型:需要指明返回的数据的类型,基本数据类型和引用数据类型都可以。需要在方法内部配合使用“return” 关键字。
4.形参列表:形参,属于局部变量,且可以声明多个。
> 无形参列表、有形参列表
5.注意点:
> 在Java中方法不能独立存在,必须定义在类里。
> Java中的方法不调用,不执行,每调用一次,就执行一次。
> 方法内可以调用本类中的(其他)方法或属性。
> 方法内不能定义其他方法。
2.3.3 方法调用时的形参和实参
1. 形参和实参
形参(Formal Parameters):
- 在方法定义时声明的变量,用于接收传入参数的值。
- 形参的类型和数量在方法签名中指定。
实参(Actual Parameters):
- 在方法调用时传递给方法的具体值或对象。
- 可以是字面量、变量、表达式或对象。
2. 值传递机制
在Java中,方法参数传递采用值传递的方式。这意味着:
基本数据类型(如
int、char、boolean等):
- 传递的是实际值的拷贝。方法内部对形参的修改不会影响到原始实参的值。
引用数据类型(如对象、数组等):
- 传递的是对象引用的拷贝。虽然引用本身是拷贝的,但它仍指向同一个对象。因此,方法内部对对象的修改会影响到原始对象。
class ValueExample { public void changePrimitive(int num) { num = 20; // 这只会改变形参 num 的值 } public void changeObject(StringBuilder str) { str.append(" World"); // 这会改变原始对象的内容 } public static void main(String[] args) { ValueExample example = new ValueExample(); // 示例 1:基本数据类型 int a = 10; example.changePrimitive(a); System.out.println("After changePrimitive: " + a); // 输出:10 // 示例 2:引用数据类型 StringBuilder sb = new StringBuilder("Hello"); example.changeObject(sb); System.out.println("After changeObject: " + sb); // 输出:Hello World } }
2.4 面向对象完成功能的三步骤
步骤一:类的定义
步骤二:对象的创建
在Java中,除了使用
new关键字创建对象之外,还有几种其他方式可以创建对象。以下是一些常见的方法:1. 使用克隆(Clone)
通过实现
Cloneable接口并重写clone()方法,可以创建对象的副本。public class Car implements Cloneable { private String color; private String model; public Car(String color, String model) { this.color = color; this.model = model; } @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } } // 使用克隆创建对象 Car originalCar = new Car("Red", "Toyota"); Car clonedCar = (Car) originalCar.clone();2. 使用反射(Reflection)
通过反射,可以在运行时创建对象。这种方法通常用于框架或库中。
import java.lang.reflect.Constructor; Car car = (Car) Class.forName("Car").getConstructor(String.class, String.class) .newInstance("Blue", "Honda");3. 使用工厂方法(Factory Method)
可以定义静态工厂方法来创建对象。这种方式可以隐藏对象创建的复杂性。
public class CarFactory { public static Car createCar(String color, String model) { return new Car(color, model); } } // 使用工厂方法创建对象 Car myCar = CarFactory.createCar("Green", "Ford");4. 通过反序列化(Serialization)
通过反序列化可以从存储数据流中创建对象。这个过程将对象的状态恢复为一个新的对象。
import java.io.*; Car myCar; try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("car.ser"))) { myCar = (Car) ois.readObject(); }5. 使用构建者模式(Builder Pattern)
构建者模式提供了一种灵活的方式来创建对象,尤其是当对象的构造参数较多时。
public class Car { private String color; private String model; private Car(Builder builder) { this.color = builder.color; this.model = builder.model; } public static class Builder { private String color; private String model; public Builder setColor(String color) { this.color = color; return this; } public Builder setModel(String model) { this.model = model; return this; } public Car build() { return new Car(this); } } } // 使用构建者模式创建对象 Car myCar = new Car.Builder().setColor("Yellow").setModel("Chevrolet").build();总结
除了使用
new关键字创建对象外,Java 还支持克隆、反射、工厂方法、反序列化和构建者模式等多种创建对象的方法。这些方式提供了灵活性和适应性,使得对象的创建更加高效和可控。步骤三:对象调用属性或方法
(1)工厂方法模式与抽象工厂模式有何区别?
工厂方法模式和抽象工厂模式都是创建型设计模式,用于解决对象的创建问题,但它们在使用场景、设计结构和复杂性上有一些显著的区别。
1. 定义和目的
工厂方法模式:
- 定义一个创建对象的接口,但由子类决定实例化哪一个类。工厂方法模式使用继承来实现对象的创建。
- 主要用于创建一个单一产品的实例。
抽象工厂模式:
- 提供一个接口,用于创建一系列相关或相互依赖的对象,而无需指定它们具体的类。
- 主要用于创建多个产品族的实例,确保这些产品之间的兼容性。
2. 结构
工厂方法模式:
- 有一个单一的工厂接口和多个具体工厂类,每个工厂类创建一种产品。
- 例如:
CarFactory接口可以有ToyotaFactory和HondaFactory类。抽象工厂模式:
- 有一个抽象工厂接口和多个具体工厂,每个具体工厂创建多个产品的实例。
- 例如:
VehicleFactory可以有CarFactory和BikeFactory,每个工厂都可以创建多种车型或类型。3. 使用场景
工厂方法模式:
- 适用于需要对产品的创建进行控制的情况,特别是当产品的种类不多时。
- 适合于创建单一产品或一组相关产品。
抽象工厂模式:
- 适用于需要创建多个产品系列的情况,确保这些产品之间的兼容性。
- 适合于产品族的管理和扩展。
4. 复杂性
工厂方法模式:
- 结构相对简单,通常只涉及一个工厂和相关的产品。
- 易于实现和理解。
抽象工厂模式:
- 结构较为复杂,需要管理多个工厂和产品。
- 可能会导致更多的类和接口,增加了系统的复杂性。
总结
- 工厂方法模式适用于单个产品的创建,强调的是单一产品的实例化和控制。
- 抽象工厂模式则用于创建多个相关产品,强调的是产品族的管理和兼容性。
选择哪种模式取决于具体的需求、产品的复杂性以及系统的设计目标。
(2)克隆方法与构造者模式相比,哪个更适合深拷贝?
在讨论克隆方法与构造者模式的深拷贝适用性时,我们可以从以下几个方面进行比较:
克隆方法
深拷贝的实现:
- 克隆方法可以通过实现
Cloneable接口并重写clone()方法来进行深拷贝。需要在clone()方法中确保所有引用类型的字段也被克隆,而不仅仅是复制引用。- 深拷贝通常需要手动处理每个可变对象的克隆,以避免共享同一内存地址。
优点:
- 可以快速复制整个对象及其所有属性。
- 适合需要频繁复制对象的场景。
缺点:
- 实现复杂,特别是当对象嵌套多层且包含大量引用类型时。
- 可能导致代码的可读性和可维护性下降。
构造者模式
深拷贝的实现:
- 构造者模式通常用于创建新的对象实例,适合于对象的定制化和初始化。通过构造器,可以确保在创建新对象时复制所有必要的字段。
- 对于深拷贝,可以在构造器中直接传递原对象并复制其所有属性,确保创建的是新对象而不是引用。
优点:
- 代码清晰,易于理解和维护。
- 可以在构造过程中添加逻辑,确保深拷贝的每个部分都被正确处理。
缺点:
- 需要显式地定义所有字段的复制逻辑,可能会导致代码冗长。
适用性比较
克隆方法:
- 更适合快速复制对象,但需要小心处理深拷贝的复杂性。
- 在需要频繁复制相同对象的情况下可能更有效。
构造者模式:
- 更适合于深拷贝,因为可以在构建新对象时集中管理所有属性的复制。
- 对于需要高度定制和管理的对象,构造者模式提供了更好的灵活性和清晰性。
结论
如果你的目标是进行深拷贝,构造者模式通常会更适合,因为它提供了更好的可读性和维护性,允许你在构建新对象时清晰地定义所有属性的复制。同时,克隆方法在处理复杂对象时可能会增加实现的复杂性。因此,选择构造者模式更能有效地管理深拷贝的需求。
(3)克隆方法与构造者模式的深拷贝实现举例
下面是使用克隆方法和构造者模式实现深拷贝的示例。
1. 克隆方法实现深拷贝
class Engine implements Cloneable { private int horsepower; public Engine(int horsepower) { this.horsepower = horsepower; } @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } public int getHorsepower() { return horsepower; } } class Car implements Cloneable { private String model; private Engine engine; public Car(String model, Engine engine) { this.model = model; this.engine = engine; } @Override protected Object clone() throws CloneNotSupportedException { // 深拷贝:克隆引擎对象 Car clonedCar = (Car) super.clone(); clonedCar.engine = (Engine) engine.clone(); return clonedCar; } public void displayInfo() { System.out.println("Model: " + model + ", Engine Horsepower: " + engine.getHorsepower()); } } // 使用克隆方法进行深拷贝 public class Main { public static void main(String[] args) throws CloneNotSupportedException { Engine engine = new Engine(200); Car originalCar = new Car("Toyota", engine); Car clonedCar = (Car) originalCar.clone(); // 修改克隆对象的引擎 clonedCar.engine = new Engine(250); originalCar.displayInfo(); // 输出: Model: Toyota, Engine Horsepower: 200 clonedCar.displayInfo(); // 输出: Model: Toyota, Engine Horsepower: 250 } }2. 构造者模式实现深拷贝
class Engine { private int horsepower; public Engine(int horsepower) { this.horsepower = horsepower; } public Engine(Engine engine) { this.horsepower = engine.horsepower; // 复制构造函数 } public int getHorsepower() { return horsepower; } } class Car { private String model; private Engine engine; public Car(String model, Engine engine) { this.model = model; this.engine = new Engine(engine); // 深拷贝 } public void displayInfo() { System.out.println("Model: " + model + ", Engine Horsepower: " + engine.getHorsepower()); } // 构造器用于深拷贝 public Car(Car car) { this.model = car.model; this.engine = new Engine(car.engine); // 深拷贝 } } // 使用构造者模式进行深拷贝 public class Main { public static void main(String[] args) { Engine engine = new Engine(200); Car originalCar = new Car("Toyota", engine); Car clonedCar = new Car(originalCar); // 使用复制构造函数进行深拷贝 // 修改克隆对象的引擎 clonedCar = new Car("Honda", new Engine(250)); originalCar.displayInfo(); // 输出: Model: Toyota, Engine Horsepower: 200 clonedCar.displayInfo(); // 输出: Model: Honda, Engine Horsepower: 250 } }总结
- 克隆方法通过实现
Cloneable接口和重写clone()方法来进行深拷贝,需要手动克隆所有引用类型的字段。- 构造者模式通过使用复制构造函数,确保在创建新对象时复制所有需要的属性,提供了更清晰和可维护的深拷贝实现。
选择适合的方式取决于具体的需求和对象的复杂性。
3. 对象的内存解析
Java虚拟机内存结构
Java虚拟机(JVM)内存结构主要分为几个部分,用于管理程序的运行时数据。以下是JVM内存结构的主要组成部分:
1. 方法区(Method Area)
- 概述:
- 存储类的信息、常量、静态变量、即时编译(JIT)编译后的代码等。
- 特点:
- 共享所有线程,属于永久代(在某些JVM实现中)。
- 在Java 8及以后的版本中,方法区被称为元空间(Metaspace),使用本地内存来存储。
2. 堆(Heap)
概述:
- 用于存储所有对象实例和数组,是JVM内存中最大的一块区域。
特点:
- 由所有线程共享。
- 垃圾回收(Garbage Collection)在这里进行,以管理内存的分配和释放。
3. 栈(Stack)
概述:
- 每个线程都有一个独立的栈,用于存储局部变量、方法调用的参数、返回值等。
特点:
- 栈中的数据结构是“栈帧”(Stack Frame),每个栈帧对应一个方法的调用。
- 局部变量以及方法参数存储在栈帧中,栈帧在方法调用结束时被销毁。
4. 程序计数器(Program Counter Register)
概述:
- 每个线程都有一个程序计数器,用于记录当前线程所执行的字节码的地址。
特点:
- 是线程私有的,线程切换时不会影响其他线程的计数器。
5. 本地方法栈(Native Method Stack)
概述:
- 专门为JVM调用本地方法(Native Method)而准备的栈。
特点:
- 类似于Java栈,但用于处理本地方法的调用。
内存结构示意图
+--------------------+ | Program Counter | +--------------------+ | Stack | | (Thread Private) | | | | +--------------+ | | | Stack Frame | | | +--------------+ | | | +--------------------+ | Heap | | (Shared by all | | Threads) | +--------------------+ | Method Area | | (Class Metadata) | +--------------------+ | Native Method Stack | +--------------------+总结
Java虚拟机的内存结构通过将内存划分为不同的区域来管理程序的运行时数据,各区域各司其职。理解这些内存结构有助于开发者优化内存使用和提高程序性能。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









