






内容转载于思否: https://segmentfault.com/a/1190000016990089
一、重排 & 重绘
浏览器下载完页面所有的资源后,就要开始构建DOM树,与此同时还会构建渲染树(Render Tree)。(其实在构建渲染树之前,和DOM树同期会构建Style Tree。DOM树与Style Tree合并为渲染树)
DOM树:表示页面的结构
渲染树:表示页面的节点如何显示
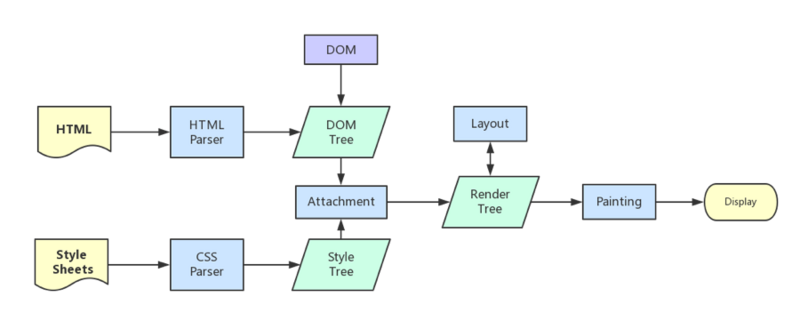
一旦渲染树构建完成,就要开始绘制(paint)页面元素了。
当DOM的变化引发了元素几何属性的变化(根本原理),比如改变元素的宽高,元素的位置,导致浏览器不得不重新计算元素的几何属性,并重新构建渲染树,这个过程称为“重排”。完成重排后,要将重新构建的渲染树渲染到屏幕上,这个过程就是“重绘”。
简单的说,重排负责元素的几何属性更新,重绘负责元素的样式更新。而且,重排必然带来重绘,但是重绘未必带来重排。比如,改变某个元素的背景,这个就不涉及元素的几何属性,所以只发生重绘。
二、 重排触发机制绘
上面已经提到了,重排发生的根本原理就是元素的几何属性发生了改变,那么我们就从能够改变元素几何属性的角度入手
- 添加或删除可见的DOM元素
- 元素位置改变
- 元素本身的尺寸发生改变
- 内容改变
- 页面渲染器初始化
- 浏览器窗口大小发生改变
三、 如何进行性能优化
重绘和重排的开销是非常昂贵的,如果我们不停的在改变页面的布局,就会造成浏览器耗费大量的开销在进行页面的计算,这样的话,我们页面在用户使用起来,就会出现明显的卡顿。现在的浏览器其实已经对重排进行了优化,比如如下代码:
var div = document.querySelector('.div');
div.style.width = '200px';
div.style.background = 'red'; //只重绘
div.style.height = '300px';
比较久远的浏览器,这段代码会触发页面2次重排,在分别设置宽高的时候,触发2次.
当代的浏览器对此进行了优化,这种思路类似于现在流行的MVVM框架使用的虚拟DOM,对改变的DOM节点进行依赖收集,确认没有改变的节点,就进行一次更新。但是浏览器针对重排的优化虽然思路和虚拟DOM接近,但是还是有本质的区别。大多数浏览器通过队列化修改并批量执行来优化重排过程。也就是说上面那段代码其实在现在的浏览器优化下,只构成一次重排。
但是还是有一些特殊的元素几何属性会造成这种优化失效。比如:
offsetTop, offsetLeft,...
scrollTop, scrollLeft, ...
clientTop, clientLeft, ...
getComputedStyle() (currentStyle in IE)
为什么造成优化失效呢?仔细看这些属性,都是需要实时回馈给用户的几何属性或者是布局属性,当然不能再依靠浏览器的优化,因此浏览器不得不立即执行渲染队列中的“待处理变化”,并随之触发重排返回正确的值。
接下来深入的介绍几种性能优化的小TIPS
3.1 最小化重绘和重排
既然重排&重绘是会影响页面的性能,尤其是糟糕的JS代码更会将重排带来的性能问题放大。既然如此,我们首先想到的就是减少重排重绘。
改变样式
考虑下面这个例子:
// javascript
var el = document.querySelector('.el');
el.style.borderLeft = '1px';
el.style.borderRight = '2px';
el.style.padding = '5px';
这个例子其实和上面那个例子是一回事儿,在最糟糕的情况下,会触发浏览器三次重排。然鹅更高效的方式就是合并所有的改变一次处理。这样就只会修改DOM节点一次,比如改为使用cssText属性实现:
var el = document.querySelector('.el');
el.style.cssText = 'border-left: 1px; border-right: 2px; padding: 5px';
沿着这个思路,聪明的老铁一定就说了,你直接改个类名不也妥妥的。没错,还有一种减少重排的方法就是切换类名,而不是使用内联样式的cssText方法。使用切换类名就变成了这样:
// css
.active {
padding: 5px;
border-left: 1px;
border-right: 2px;
}
// javascript
var el = document.querySelector('.el');
el.className = 'active';
批量修改DOM
如果我们需要对DOM元素进行多次修改,怎么去减少重排和重绘的次数呢?
有的同学又要说了,利用上面修改样式的方法不就行了吗。回过头看一下造成页面重排的几个要点里,可以明确的看到,造成元素几何属性发生改变就会触发重排,现在需要增加10个节点,必然涉及到DOM的修改,这个时候就需要利用批量修改DOM这种优化方式了,这里也能看到,改变样式最小化重绘和重排这种优化方式适用于单个存在的节点。
批量修改DOM元素的核心思想是:
- 让该元素脱离文档流
- 对其进行多重改变
- 将元素带回文档中
打个比方,我们主机硬盘出现了故障,常见的办法就是把硬盘卸下来,用专业的工具测试哪里有问题,待修复后再安装上去。要是直接在主板上面用螺丝刀弄来弄去,估计主板一会儿也要坏了...
这个过程引发俩次重排,第一步和第三步,如果没有这两步,可以想象一下,第二步每次对DOM的增删都会引发一次重排。那么知道批量修改DOM的核心思想后,我们再了解三种可以使元素可以脱离文档流的方法,注意,这里不使用css中的浮动&绝对定位,这是风马牛不相及的概念。
看一下下面这个代码示例:
// html
<ul id="mylist">
<li><a href="https://www.mi.com">xiaomi</a></li>
<li><a href="https://www.miui.com">miui</a></li>
</ul>
// javascript 现在需要添加带有如下信息的li节点
let data = [
{
name: 'tom',
url: 'https://www.baidu.com',
},
{
name: 'ann',
url: 'https://www.techFE.com'
}
]
首先,我们先写一个通用的用于将新数据更新到指定节点的方法:
// javascript
function appendNode($node, data) {
var a, li;
for(let i = 0, max = data.length; i < max; i++) {
a = document.createElement('a');
li = document.createElement('li');
a.href = data[i].url;
a.appendChild(document.createTextNode(data[i].name));
li.appendChild(a);
$node.appendChild(li);
}
}
首先我们忽视所有的重排因素,大家肯定会这么写:
let ul = document.querySelector('#mylist');
appendNode(ul, data);
使用这种方法,在没有任何优化的情况下,每次插入新的节点都会造成一次重排(这几部分我们都先讨论重排,因为重排是性能优化的第一步)。
考虑这个场景,如果我们添加的节点数量众多,而且布局复杂,样式复杂,那么能想到的是你的页面一定非常卡顿。我们利用批量修改DOM的优化手段来进行重构
1)隐藏元素,进行修改后,然后再显示该元素
let ul = document.querySelector('#mylist');
ul.style.display = 'none';
appendNode(ul, data);
ul.style.display = 'block';
这种方法造成俩次重排,分别是控制元素的显示与隐藏。对于复杂的,数量巨大的节点段落可以考虑这种方法。为啥使用display属性呢,因为display为none的时候,元素就不在文档流了,还不熟悉的老铁,手动Google一下三者的区别
display:none;
opacity: 0;
visibility: hidden
2)使用文档片段创建一个子树,然后再拷贝到文档中
let fragment = document.createDocumentFragment();
appendNode(fragment, data);
ul.appendChild(fragment);
我是比较喜欢这种方法的,文档片段是一个轻量级的document对象,它设计的目的就是用于更新,移动节点之类的任务,而且文档片段还有一个好处就是,当向一个节点添加文档片段时,添加的是文档片段的子节点群,自身不会被添加进去。
不同于第一种方法,这个方法并不会使元素短暂消失造成逻辑问题。上面这个例子,只在添加文档片段的时候涉及到了一次重排。
3)将原始元素拷贝到一个独立的节点中,操作这个节点,然后覆盖原始元素
let old = document.querySelector('#mylist');
let clone = old.cloneNode(true);
appendNode(clone, data);
old.parentNode.replaceChild(clone, old);
可以看到这种方法也是只有一次重排。总的来说,使用文档片段,可以操作更少的DOM(对比使用克隆节点),最小化重排重绘次数。
缓存布局信息
缓存布局信息这个概念,在《高性能JavaScript》DOM性能优化中,多次提到类似的思想.
比如我现在要得到页面ul节点下面的100个li节点,最好的办法就是第一次获取后就保存起来,减少DOM的访问以提升性能,缓存布局信息也是同样的概念。
前面有讲到,当访问诸如offsetLeft,clientTop这种属性时,会冲破浏览器自有的优化————通过队列化修改和批量运行的方法,减少重排/重绘版次。所以我们应该尽量减少对布局信息的查询次数,查询时,将其赋值给局部变量,使用局部变量参与计算。
看以下样例:
将元素div向右下方平移,每次移动1px,起始位置100px, 100px。性能糟糕的代码:
div.style.left = 1 + div.offsetLeft + 'px';
div.style.top = 1 + div.offsetTop + 'px';
这样造成的问题就是,每次都会访问div的offsetLeft,造成浏览器强制刷新渲染队列以获取最新的offsetLeft值。更好的办法就是,将这个值保存下来,避免重复取值
current = div.offsetLeft;
div.style.left = 1 + ++current + 'px';
div.style.top = 1 + ++current + 'px';

















 4065
4065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









