







1.MyBatis学习
这次用了一周多的时间学习了mybatis。
简介
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
什么是持久层
持久层,可以理解成数据 保存在 数据库或者 硬盘一类可以保存很长时间的设备里面,不像放在内存中那样断电就消失了,也就是把数据存在持久化设备上,mybatis就是持久层。
官方文档 https://mybatis.org/mybatis-3/zh/index.html
2.搭建环境
- 我们使用maven来构建项目,直接构建一个空的项目。
- 导入如下依赖
<!--导入mybatis依赖 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!--数据库驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
<!-- 测试-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
- 在resources文件夹下书写配置文件mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="XXX"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/yxx/dao/DepartmentDao.xml"/>
</mappers>
</configuration>
- 创建一个工具类MybatisUtil 在工具类中得到SqlSession
public class MybatisUtil {
private static SqlSessionFactory sqlSessionFactory;
static{
String resource = "mybatis-config.xml";
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//获取session从sqlSessionFactory工厂中
public SqlSession getSqlSession(){
return sqlSessionFactory.openSession();
}
}
- 创建实体类Department 这里省略get set tostring 构造方法 (下面的也是)
public class Department {
private int id;
private String departmentName;
}
对应数据库
create table department(
id int primary key,
departmentName varchar(20)
)
- dao层 DepartmentDao
public interface DepartmentDao {
//查询全部
public List<Department> findAll();
}
DepartmentDao.xml 这个名字应用上面dao层名字对应
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace绑定一个对应的XXXDao -->
<mapper namespace="com.yxx.dao.DepartmentDao">
<select id="findAll" resultType="com.yxx.pojo.Department">
select * from yxx.department
</select>
</mapper>
- 测试
@Test
public void test(){
MybatisUtil mybatisUtil = new MybatisUtil();
SqlSession session = mybatisUtil.getSqlSession();
DepartmentDao mapper = session.getMapper(DepartmentDao.class);
List<Department> list = mapper.findAll();
for (Department department : list) {
System.out.println(department);
}
session.close();//一定记得使用完后关闭session
}
3.配置文件(xml)
管网里有很多配置的东西 我只会用一些
3.1.属性 properties
属性你可以从外部进行配置,并可以进行动态替换。也可以在xml文件中进行配置
- 从外部配置
我们需要导入properties文件
<!--这些属性可以在外部进行配置,并可以进行动态替换。你既可以在典型的 Java 属性文件中配置这些属性,也可以在 properties 元素的子元素中设置 -->
<properties resource="db.properties"/>
- 在xml文件中配置
<properties resource="db.properties">
<property name="username" value="root"/>
<property name="password" value="123"/>
</properties>
db.properties中配置的属性
driver=com.mysql.cj.jdbc.Driver
url=XXX
username=root
pwd=123456
导入属性配置文件就可以在xml如下使用
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${pwd}"/>
</dataSource>
</environment>
</environments>
读取顺序 :他会先去外部properties文件中找属性,如果没找到再从xml文件中配置的属性中找
3.2.设置(Settings)
这个官方就更多了,我也只知道熟悉几个
- mapUnderscoreToCamelCase
是否开启驼峰命名自动映射,即从经典数据库列名 A_COLUMN 映射到经典 Java 属性名 aColumn。
- logImpl
指定 MyBatis 所用日志的具体实现,未指定时将自动查找。
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="multipleResultSetsEnabled" value="true"/>
<setting name="useColumnLabel" value="true"/>
<setting name="useGeneratedKeys" value="false"/>
<setting name="autoMappingBehavior" value="PARTIAL"/>
<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
<setting name="defaultExecutorType" value="SIMPLE"/>
<setting name="defaultStatementTimeout" value="25"/>
<setting name="defaultFetchSize" value="100"/>
<setting name="safeRowBoundsEnabled" value="false"/>
<setting name="mapUnderscoreToCamelCase" value="false"/>
<setting name="localCacheScope" value="SESSION"/>
<setting name="jdbcTypeForNull" value="OTHER"/>
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
</settings>
3.3.配置别名 (typeAliases)
配置别名后就不需要每次在返回值ResultType中书写全限定类名,只需要写你自己配置的别名即可
你只需要在mybatis的配置文件中加上如下几行
<!--类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写
type:类型
alias : 别名
-->
<typeAliases>
<typeAlias type="com.yxx.pojo.Department" alias="Department"/>
</typeAliases>
当你的项目中有很多实体类是,这样一个一个的配置别名会显得代码太多,所以我们还有一种方法配置别名,那就是扫描包,但是这种方法你不能自己定义别名,他的别名就是类的名字
<typeAliases>
<package name="com.yxx.pojo"/>
</typeAliases>
3.4.mappers 映射器
mappers映射器是为了告诉我们mybatis到哪里去找到我们写的sql语句
官网中有四种方式 但我感觉常用的也就三种把
- 使用resource引用
<mappers>
<mapper resource="com/yxx/dao/DepartmentDao.xml"/>
</mappers>
- 使用映射器接口实现类的完全限定类名
<mappers>
<mapper class="com.yxx.dao.DepartmentDao"/>
</mappers>
使用这种方法必须保证类的名字与书写sql中的名字一样
- 扫描包
<!-- 将包内的映射器接口实现全部注册为映射器 -->
<mappers>
<package name="com.yxx.dao"/>
</mappers>
4.sql模糊查询
代码中的注解写的很清楚
- dao层中的xml
<!--模糊查询 两种方法
方法一List<Department> departmentList = mapper.fuzzyQuery("%部%"); 查询时加上转义符%
方法二select * from yxx.department where departmentName like "%"#{value}"%"
直接写死在查询语句中
-->
<select id="fuzzyQuery" resultType="com.yxx.pojo.Department">
select * from yxx.department where departmentName like "%"#{value}"%"
</select>
- 测试
@Test
public void fuzzyQuery(){
MybatisUtil mybatisUtil = new MybatisUtil();
SqlSession session = mybatisUtil.getSqlSession();
DepartmentDao mapper = session.getMapper(DepartmentDao.class);
List<Department> departmentList = mapper.fuzzyQuery("部");
for (Department department : departmentList) {
System.out.println(department);
}
session.close();
}
5.解决属性名与数据库列名不对应
这个我们需要使用结果映射,因为这里不涉及多对一和一对多所以简单结果映射即可
resultMap 元素是 MyBatis 中最重要最强大的元素。它可以让你从 90% 的 JDBC ResultSets 数据提取代码中解放出来,并在一些情形下允许你进行一些 JDBC 不支持的操作。实际上,在为一些比如连接的复杂语句编写映射代码的时候,一份 resultMap 能够代替实现同等功能的数千行代码。ResultMap 的设计思想是,对简单的语句做到零配置,对于复杂一点的语句,只需要描述语句之间的关系就行了。
当你的pojo类属性与数据库的列名不同时即可使用,一对多,多对一时使用
当属性与数据库的列名不同时
Department类
public class Department {
private int id;
private String name;
}
数据库中列名
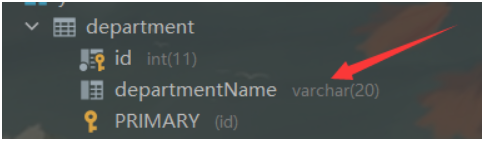
name 与 departmentName不同时当我们直接查询
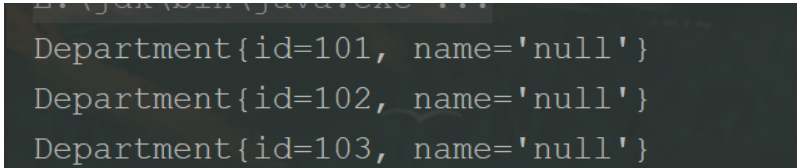
查出来name为null 为什么为null了,当然是因为没有找到name属性因为我们没有对应数据库中列表的名字
有两种解决问题的方法
- 直接给查询语句加别名
<select id="findAll" resultType="departmen">
select id,departmentName as name from yxx.department
</select>
- 使用ResultMap结果映射
可以只映射不相同的部分
<resultMap id="departmentmap" type="department">
<!--column:对应的列表名 property:对用pojo类的属性名 -->
<result column="id" property="id"/><!--这里可以不写 因为id对应了列表名 -->
<result column="departmentName" property="name"/>
</resultMap>
<select id="findAll" resultMap="departmentmap">
select * from yxx.department
</select>
6.mybatis分页
思考为什么需要分页?
减少数据的处理量,不分页一下查询的东西太多
6.1.Limit分页
使用limit语句分页
- dao
//limit分页查询
public List<Department> queryByLimit(Map<String,Object> map);
- xml
<!--startIndex 表示开始的位置, pageSize 表示一页的大小-->
<select id="queryByLimit" parameterType="map" resultType="Department">
select * from department limit #{startIndex},#{pageSize}
</select>
- 测试
@Test
public void limit(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
DepartmentDao mapper = sqlSession.getMapper(DepartmentDao.class);
Map<String,Object> map = new HashMap<>();
map.put("startIndex",0);
map.put("pageSize",3);
List<Department> departments = mapper.queryByLimit(map);
for (Department department : departments) {
System.out.println(department);
}
sqlSession.close();
}
- 结果
6.2.RowBounds分页
不使用sql语句实现分页。这个方法其实不怎么好用因为他不能用获取mapper的形式来使用sql语句。他必须如下使用,很jj麻烦
sqlSession.selectList("com.yxx.dao.DepartmentDao.queryByRowBounds", null, rowBounds);
- dao
//RowBounds分页查询
public List<Department> queryByRowBounds();
- xml
<select id="queryByRowBounds" resultType="Department">
select * from department
</select>
- 测试
@Test
public void rowBounds(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
RowBounds rowBounds = new RowBounds(1,2);
List<Department> departments = sqlSession.selectList("com.yxx.dao.DepartmentDao.queryByRowBounds", null, rowBounds);
for (Department department : departments) {
System.out.println(department);
}
sqlSession.close();
}
- 结果

6.3.使用插件分页(pagehelper)
我还没学
7.使用注解写sql
使用注解写sql可以免去写XXXDao.xml文件也可以免去配置mappers,但是他只能完成简单的CURD复杂的还是必须写XXXDao.xml并配置mappers
简单的sql语句可以用注解来简化代码,但是复杂的sql或者pojo与数据库列名不对应时,使用注解不能达到我们想要的效果
- dao
@Select("select * from department where id = #{id}")
public Department queryById(@Param("id") String id);
- 测试
@Test
public void queryById(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
DepartmentDao mapper = sqlSession.getMapper(DepartmentDao.class);
Department department = mapper.queryById("101");
System.out.println(department);
sqlSession.close();
}
8.多对一 一对多处理
对于学生而言 一个学生关联一个老师
对于老师而言 一个老师管理多个学生
8.1.搭建环境
- 搭建数据库
CREATE TABLE `teacher` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO teacher(`id`, `name`) VALUES (1, 秦老师);
CREATE TABLE `student` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
`tid` INT(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fktid` (`tid`),
CONSTRAINT `fktid` FOREIGN KEY (`tid`) REFERENCES `teacher` (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8INSERT INTO `student` (`id`, `name`, `tid`) VALUES (1, 小明, 1);
INSERT INTO `student` (`id`, `name`, `tid`) VALUES (2, 小红, 1);
INSERT INTO `student` (`id`, `name`, `tid`) VALUES (3, 小张, 1);
INSERT INTO `student` (`id`, `name`, `tid`) VALUES (4, 小李, 1);
INSERT INTO `student` (`id`, `name`, `tid`) VALUES (5, 小王, 1);
- 实体类pojo
Student:
public class Student {
private int id;
private String sname;
private Teacher teacher;//实现多对一
}
Teacher:
public class Teacher {
private int id;
private String tname;
/*
老师应该这样写的因为一个老师管理多个学生
但我们这里只讨论多以一
一对多在下面在讨论
private List<Student> students;
*/
}
- mapper(dao) 接口
public interface TeacherMapper {
}
public interface StudentMapper {
}
8.2.多对一
一个学生关联一个老师
关联的不同之处是,你需要告诉 MyBatis 如何加载关联。MyBatis 有两种不同的方式加载关联:
- 嵌套 Select 查询:通过执行另外一个 SQL 映射语句来加载期望的复杂类型。
- 嵌套结果映射:使用嵌套的结果映射来处理连接结果的重复子集。
- 嵌套select查询
- mapper(dao)
public Student getStudent(@Param("id") int id);
- xml
<mapper namespace="com.yxx.dao.StudentMapper">
<!--select嵌套查询下面三个是一体的 -->
<select id="getStudent" resultMap="studentMap">
select * from student where id = #{id}
</select>
<resultMap id="studentMap" type="student">
<result property="id" column="id"/>
<result property="sname" column="sname"/>
<!--复杂的属性我们需要单独处理
association:对象
collection:集合
-->
<association property="teacher" column="tid" javaType="teacher" select="getTeacher"/>
</resultMap>
<select id="getTeacher" resultType="teacher">
select * from teacher where id = #{tid}
</select>
</mapper>
- 测试
@Test
public void getStudent(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Student student = mapper.getStudent(1);
System.out.println(student);
sqlSession.close();
}
这种方式虽然很简单,但在大型数据集或大型数据表上表现不佳。这个问题被称为“N+1 查询问题”。 概括地讲,N+1 查询问题是这样子的:
- 你执行了一个单独的 SQL 语句来获取结果的一个列表(就是“+1”)。
- 对列表返回的每条记录,你执行一个 select 查询语句来为每条记录加载详细信息(就是“N”)。
这个问题会导致成百上千的 SQL 语句被执行。有时候,我们不希望产生这样的后果。
好消息是,MyBatis 能够对这样的查询进行延迟加载,因此可以将大量语句同时运行的开销分散开来。 然而,如果你加载记录列表之后立刻就遍历列表以获取嵌套的数据,就会触发所有的延迟加载查询,性能可能会变得很糟糕。
- 关联的嵌套结果映射
- mapper(dao)
//嵌套结果映射
public Student getStudent2(@Param("id") int id);
- xml
<select id="getStudent2" resultMap="studentMap2">
select s.id sid,s.sname sname,t.tname tname,t.id tid
from student s,teacher t
where s.tid = t.id and s.id = #{id}
</select>
<resultMap id="studentMap2" type="student">
<result property="id" column="sid"/>
<result property="sname" column="sname"/>
<association property="teacher" javaType="teacher">
<result property="id" column="tid"/>
<result property="tname" column="tname"/>
</association>
</resultMap>
- 测试
@Test
public void getStudent2(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Student student = mapper.getStudent2(1);
System.out.println(student);
sqlSession.close();
}
8.3.一对多
前面说了多对一的例子是一个学生关联一个老师,那么反过来就是一个老师管理(集合)多个学生。
因为前面老师没做一对多的属性,所以这里需要加上
teacher类:
也有两种方式实现
- 集合的嵌套 Select 查询
- mapper(dao)
//集合的嵌套 Select 查询
public Teacher getTeacherSelect(@Param("id") int id);
- xml
<!--嵌套select查询(子查询) -->
<select id="getTeacherSelect" resultMap="teachermap">
select * from teacher where id = #{id}
</select>
<resultMap id="teachermap" type="teacher">
<!--实体类与数据库列名相对应的可以不写映射-->
<result property="id" column="id"/>
<result property="tname" column="tname"/>
<!--复杂类型单独处理
javaType
ofType 确认List里泛型的东西
-->
<collection property="students" column="id" javaType="ArrayList" ofType="student" select="getStudent"/>
</resultMap>
<select id="getStudent" resultType="student">
select * from student where tid = #{id}
</select>
- 测试
@Test
public void getTeacher(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
TeacherMapper mapper = sqlSession.getMapper(TeacherMapper.class);
Teacher teacher = mapper.getTeacherSelect(1);
System.out.println(teacher);
sqlSession.close();
}
你可能会立刻注意到几个不同,但大部分都和我们上面学习过的关联元素非常相似。 首先,你会注意到我们使用的是集合元素。 接下来你会注意到有一个新的 “ofType” 属性。这个属性非常重要,它用来将 JavaBean(或字段)属性的类型和集合存储的类型区分开来。 所以你可以按照下面这样来阅读映射:
<collection property="students" column="id" javaType="ArrayList" ofType="student" select="getStudent"/>读作: “students是一个存储 student的 ArrayList 集合”
在一般情况下,MyBatis 可以推断 javaType 属性,因此并不需要填写。所以很多时候你可以简略成:
<collection property="students" column="id" ofType="student" select="getStudent"/>
- 集合的嵌套结果映射
- mapper(dao)
//集合的嵌套结果映射
public Teacher getTeacherSelect2(@Param("id") int id);
- xml
<!-- 集合的嵌套结果映射-->
<select id="getTeacherSelect2" resultMap="teachermap2">
select t.id tid,t.tname tname,s.id sid,s.sname sname
from teacher t,student s
where t.id = #{id} and t.id = s.tid
</select>
<resultMap id="teachermap2" type="teacher">
<result property="id" column="tid" />
<result property="tname" column="tname" />
<collection property="students" javaType="ArrayList" ofType="student">
<result property="id" column="sid"/>
<result property="sname" column="sname"/>
</collection>
</resultMap>
- 测试
@Test
public void getTeacher2(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
TeacherMapper mapper = sqlSession.getMapper(TeacherMapper.class);
Teacher teacher = mapper.getTeacherSelect2(1);
System.out.println(teacher);
sqlSession.close();
}
9.动态sql
动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦。
使用动态 SQL 并非一件易事,但借助可用于任何 SQL 映射语句中的强大的动态 SQL 语言,MyBatis 显著地提升了这一特性的易用性。
如果你之前用过 JSTL 或任何基于类 XML 语言的文本处理器,你对动态 SQL 元素可能会感觉似曾相识。在 MyBatis 之前的版本中,需要花时间了解大量的元素。借助功能强大的基于 OGNL 的表达式,MyBatis 3 替换了之前的大部分元素,大大精简了元素种类,现在要学习的元素种类比原来的一半还要少。
9.1.搭建环境
- 数据库
/*
Navicat Premium Data Transfer
Source Server : test
Source Server Type : MySQL
Source Server Version : 80018
Source Host : localhost:3306
Source Schema : mybatis
Target Server Type : MySQL
Target Server Version : 80018
File Encoding : 65001
Date: 09/05/2021 15:16:33
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for blog
-- ----------------------------
DROP TABLE IF EXISTS `blog`;
CREATE TABLE `blog` (
`id` varchar(50) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL COMMENT '博客id',
`title` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL COMMENT '博客标题',
`author` varchar(30) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL COMMENT '博客作者',
`create_time` datetime(0) NOT NULL COMMENT '创建时间',
`view` int(30) NOT NULL COMMENT '浏览量'
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
- 实体类Blog
public class Blog {
private String id;
private String title;
private String author;
private Date createTime;
private int view;
}
- 插入数据写的java代码
@Test
public void addTest(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
Blog blog = new Blog();
blog.setId(IDUtil.getId());
blog.setTitle("java");
blog.setAuthor("喻老师");
blog.setCreateTime(new Date());
blog.setView(100);
mapper.addBlog(blog);
blog.setId(IDUtil.getId());
blog.setTitle("c");
blog.setAuthor("喻老师");
blog.setCreateTime(new Date());
blog.setView(100);
mapper.addBlog(blog);
blog.setId(IDUtil.getId());
blog.setTitle("c++");
blog.setAuthor("喻老师");
blog.setCreateTime(new Date());
blog.setView(100);
mapper.addBlog(blog);
blog.setId(IDUtil.getId());
blog.setTitle("python");
blog.setAuthor("喻老师");
blog.setCreateTime(new Date());
blog.setView(100);
mapper.addBlog(blog);
sqlSession.close();
}
- 生产id用的一个UUID
package com.yxx.util;
import org.junit.Test;
import java.util.UUID;
public class IDUtil {
public static String getId(){
return UUID.randomUUID().toString();
}
@Test
public void test(){
System.out.println(IDUtil.getId());
}
}
9.2.if
用例子来说明
- mapper(dao)
//动态if语句
public List<Blog> queryIf(Map map);
- xml
<!--满足if条件就拼接语句 -->
<select id="queryIf" parameterType="map" resultType="blog">
select * from blog
where 1 = 1
<if test="title != null">
and title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</select>
- 测试
@Test
public void queryIf(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<String, Object>();
//map.put("title","java");
//map.put("author","喻老师");
List<Blog> blogs = mapper.queryIf(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
sqlSession.close();
}
可以看出我们是屏蔽了map的两个参数,这个时候就sql就应该没有拼接语句 应当查出所有
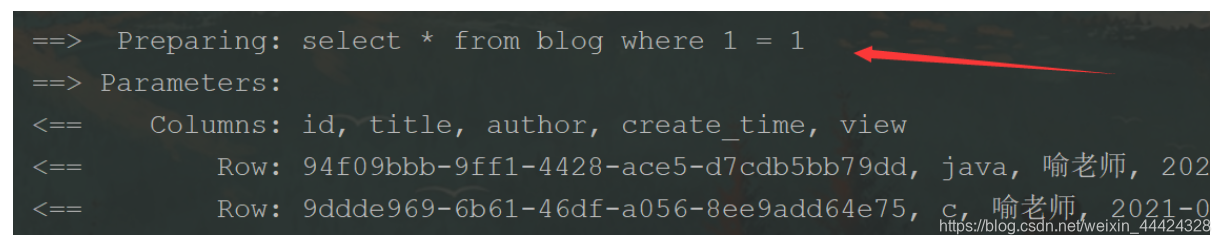
可以看出并没有拼接语句
当我们传入一个title参数时

明显可以看到拼接了一条sql语句,传入另一个或者两个类似
9.3.choose、when、otherwise
有得时候我们只想要多个条件中的一个,针对这种情况,就该用choose元素了,和java中的switch语句类似
还是上面的例子,但是策略变为:传入了 “title” 就按 “title” 查找,传入了 “author” 就按 “author” 查找的情形。若两者都没有传入,就返回全部
- mapper(dao)
//动态choose语句
public List<Blog> queryChoose(Map map);
- xml
<select id="queryChoose" parameterType="map" resultType="blog">
select * from blog
where 1 = 1
<choose>
<when test="title != null">
and title = #{title}
</when>
<when test="author != null">
and author = #{author}
</when>
<otherwise>
and 1 = 1
</otherwise>
</choose>
</select>
- 测试
@Test
public void queryChooseTest(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("title","java");
//map.put("author","喻老师");
List<Blog> blogs = mapper.queryChoose(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
sqlSession.close();
}

我们发现他拼接title = ?,因为他在choose里第一个满足。
如果map传入两个参数,还是只会选择一个条件拼接,他会选择第一个满足的条件拼接
9.4.trim、where、set
9.4.1.where
前面几个例子已经方便的解决了动态sql的问题,但是仔细看看我们前面写的sql语句
select * from blog
where 1 = 1
这个where 1 = 1是不是不符合规范,但是我们将1 = 1去掉,如果下面的语句不满足条件,查询语句就变成了
select * from blog
where
这样的查询就有问题,有bug查不出数据。如果下面语句满足条件,查询语句就变成了
select * from blog
where and
这样查询语句还是有问题,这样这个问题就很难解决,当然你可以像前面一样写一个不规范的1 = 1,这样的确可以解决这个问题。那就没必要学习trim、where、set了
我们只需要加上where标签即可
<!--满足if条件就拼接语句 -->
<select id="queryIf" parameterType="map" resultType="blog">
select * from blog
<where>
<if test="title != null">
and title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</where>
</select>
测试
@Test
public void queryIf(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("title","java");
//map.put("author","喻老师");
List<Blog> blogs = mapper.queryIf(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
sqlSession.close();
}
- 但我们传入一个参数时
select * from blog WHERE title = ?
直接帮我们拼接了一个语句
where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
如果 where 元素与你期望的不太一样,你也可以通过自定义 trim 元素来定制 where 元素的功能。比如,和 where 元素等价的自定义 trim 元素为:
<trim prefix="WHERE" prefixOverrides="AND |OR "> ... </trim>
9.4.2.set
用于动态更新语句的类似解决方案叫做 set。set 元素可以用于动态包含需要更新的列,忽略其它不更新的列
- mapper(dao)
//动态set语句
public int querySet(Map map);
- xml
<update id="querySet" parameterType="map" >
update blog
<set>
<if test="title != null"> title = #{title},</if>
<if test="author != null"> author = #{author},</if>
<if test="view != null"> view = #{view}</if>
</set>
where id = #{id}
</update>
- 测试
@Test
public void querySetTest(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("id","9ddde969-6b61-46df-a056-8ee9add64e75");
map.put("author","小明");
mapper.querySet(map);
sqlSession.close();
}
这个例子中,set 元素会动态地在行首插入 SET 关键字,并会删掉额外的逗号(这些逗号是在使用条件语句给列赋值时引入的)。
来看看与 set 元素等价的自定义 trim 元素吧:
<trim prefix="SET" suffixOverrides=","> ... </trim>
9.5.foreach
动态 SQL 的另一个常见使用场景是对集合进行遍历(尤其是在构建 IN 条件语句的时候)
- mapper(dao)
//动态Foreach语句
public List<Blog> queryForeach(Map map);
- xml
<select id="queryForeach" parameterType="map" resultType="blog">
select * from blog
<where>
<if test="ids != null">
id in
<!-- open:开始
separator:分隔符
close:结束
-->
<foreach collection="ids" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</if>
</where>
</select>
- 测试
@Test
public void queryForeachTest(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<String, Object>();
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
if(list.size() > 0)
map.put("ids",list);
mapper.queryForeach(map);
sqlSession.close();
}
foreach 元素的功能非常强大,它允许你指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。这个元素也不会错误地添加多余的分隔符,看它多智能!
提示 你可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。当使用可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









