






 本文介绍了使用Python requests和bs4库爬取中国城市天气信息,特别是如何处理黑龙江与城市名称的特殊情况,以及对城市最低温度进行排序,实现全国城市最低温度前二十的获取。过程中遇到了港澳台地区数据格式不同的问题。
本文介绍了使用Python requests和bs4库爬取中国城市天气信息,特别是如何处理黑龙江与城市名称的特殊情况,以及对城市最低温度进行排序,实现全国城市最低温度前二十的获取。过程中遇到了港澳台地区数据格式不同的问题。
这个网站没有robot协议
需求:
找出中国所有城市某一天的最低温度,找出最低的前二十名
技术路线:requests-bs4
开搞
打开浏览器,进入到中国天气的页面, http://www.weather.com.cn/textFC/hb.shtml
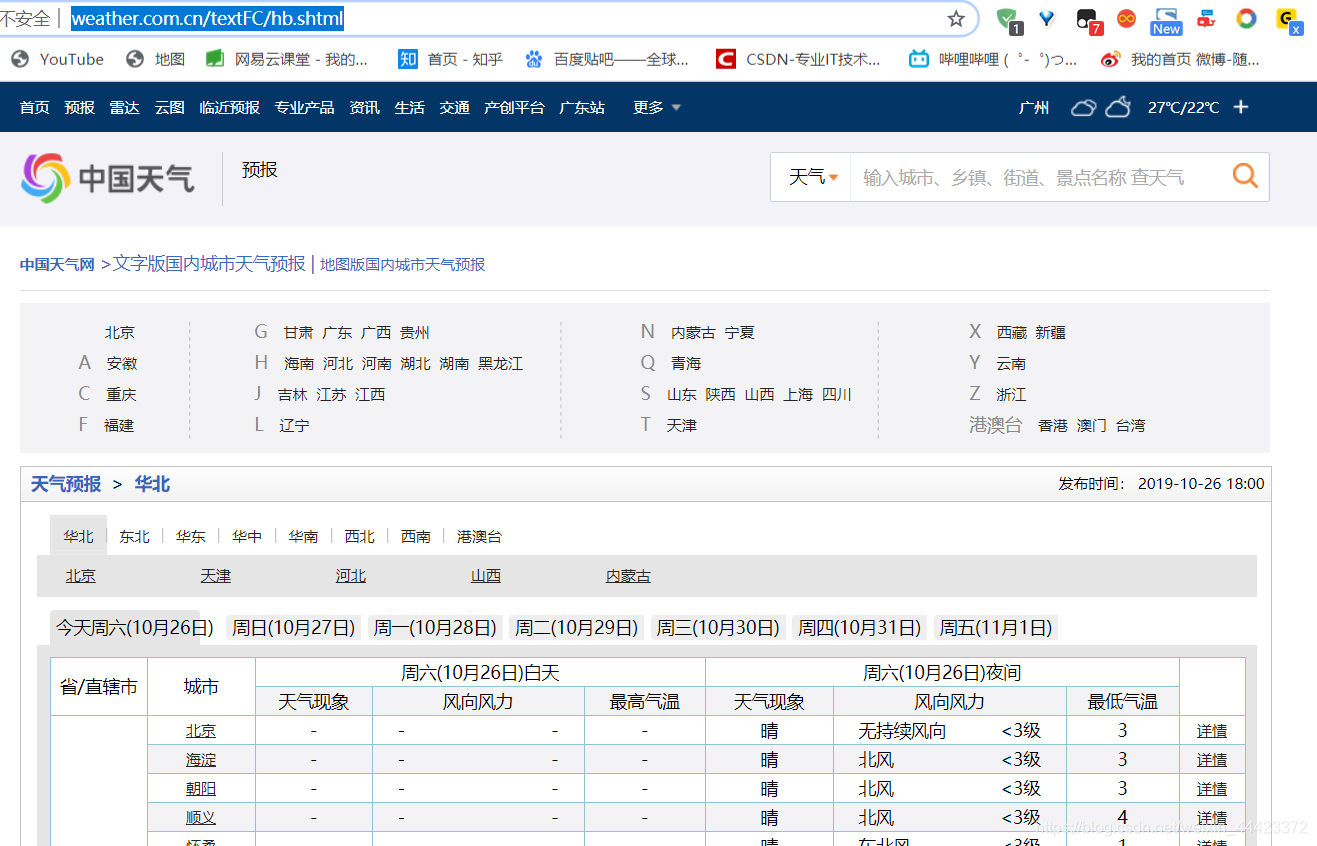
打开开发者工具,找到相应的需要的内容
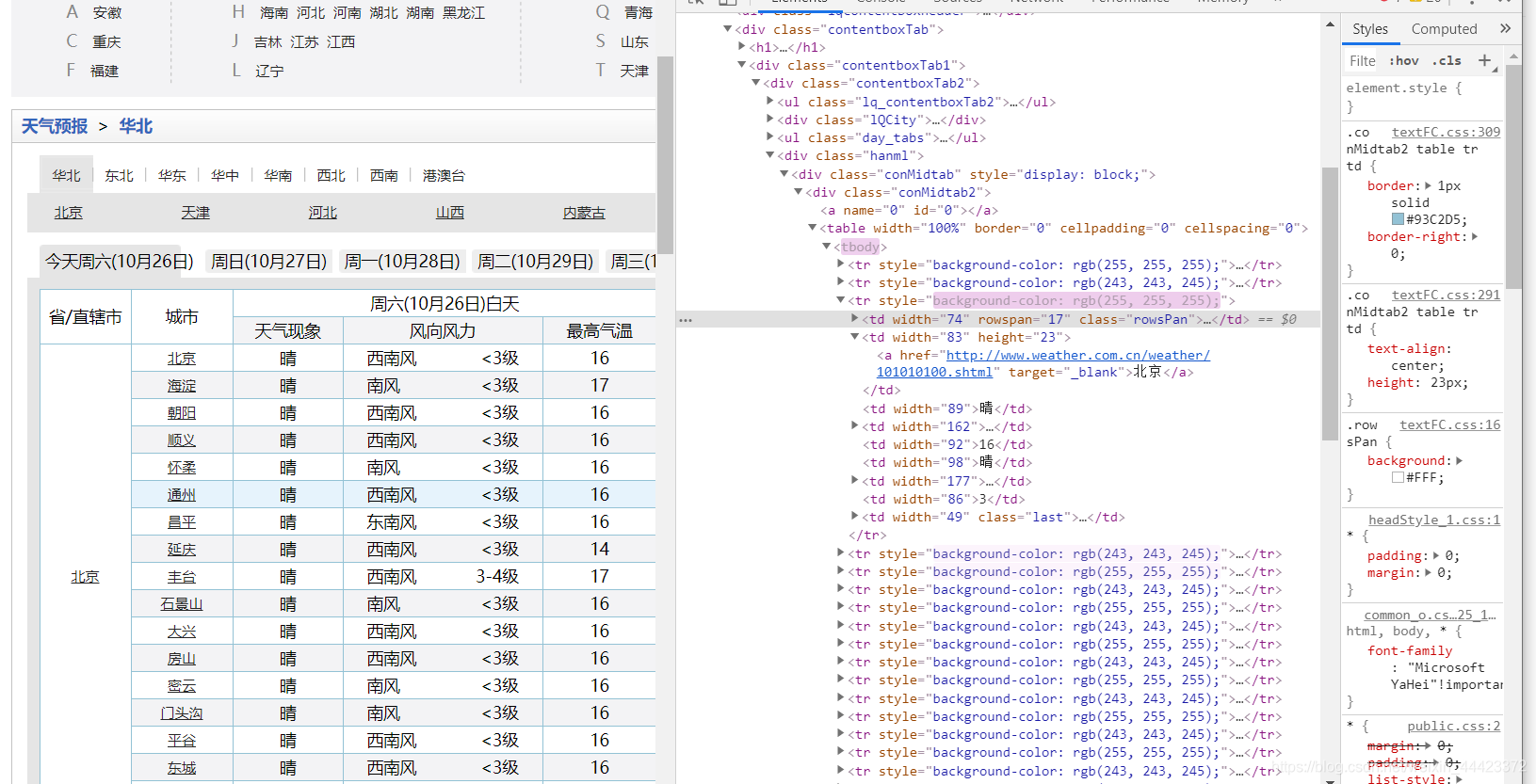
查找到的HTML标签顺序为 div class =‘conMidtab’ --> table --> tr --> td
开始写代码
import requests
from bs4 import BeautifulSoup
def getHTML(url):
try:
r = requests.get(url)
r.raise_for_status() # 确保连接成功
text = r.content.decode('utf-8') # 确保不会出现乱码情况
except:
return " "
soup = BeautifulSoup(text,'lxml') # 使用‘lxml’解析库的方式,解析html
con = soup.find('div', class_='conMidtab') # 根据开发者工作中,查找标签div,class = 'conMidtab'
tables = con.find_all('table') # 寻找全部的'table' 并赋给 tables
for table in tables: # 做一个循环遍历
trs = table.find_all('tr')[2:] # 寻找从2开始所有的‘tr’,因为第1个为省/直辖市,城市,没有用到
for tr in trs:
tds = tr.find_all('td') # 寻找所有的‘td’标签
city_td = tds[0] # 城市名称所在的 td键
city = list(city_td.stripped_strings)[0]
temp_td = tds[-2] # 温度所在的 td键
min_temp = list(temp_td.stripped_strings)[0]
print({"city":city,"min_temp":min_temp})
def main():
url = "http://www.weather.com.cn/textFC/hb.shtml" # 华北所有城市
getHTML(url)
main()
结果
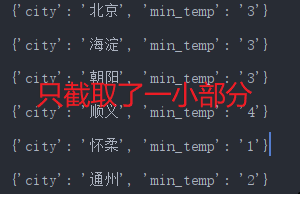
接下来,将url换成东北的。看看能不能通用,执行后,乍一看并没有问题,但细看,第一行,却是黑龙江。
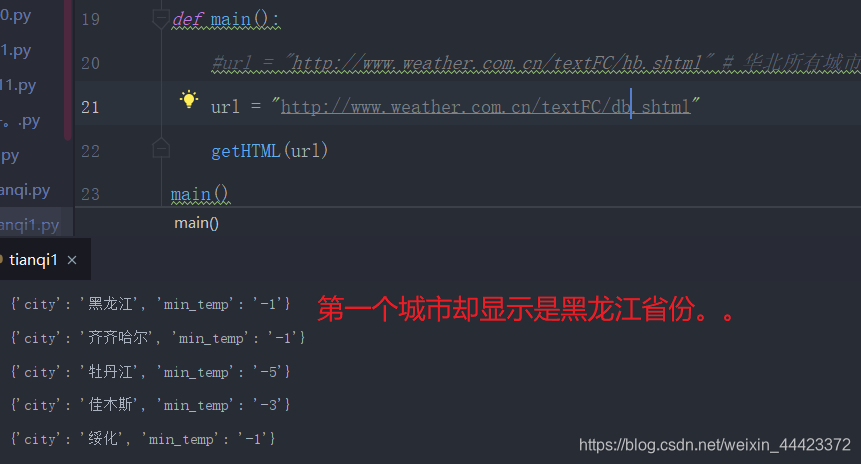
emmmm,去网页,查看以下
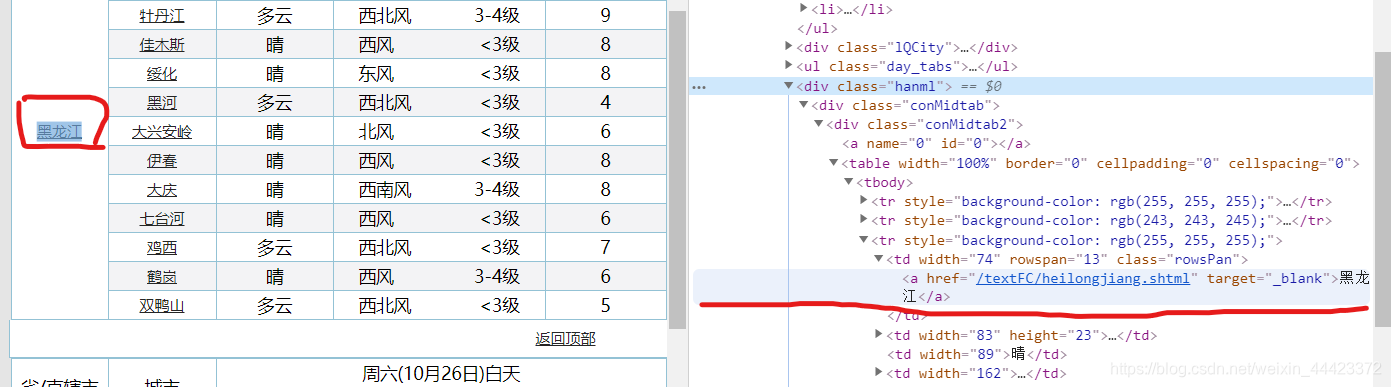
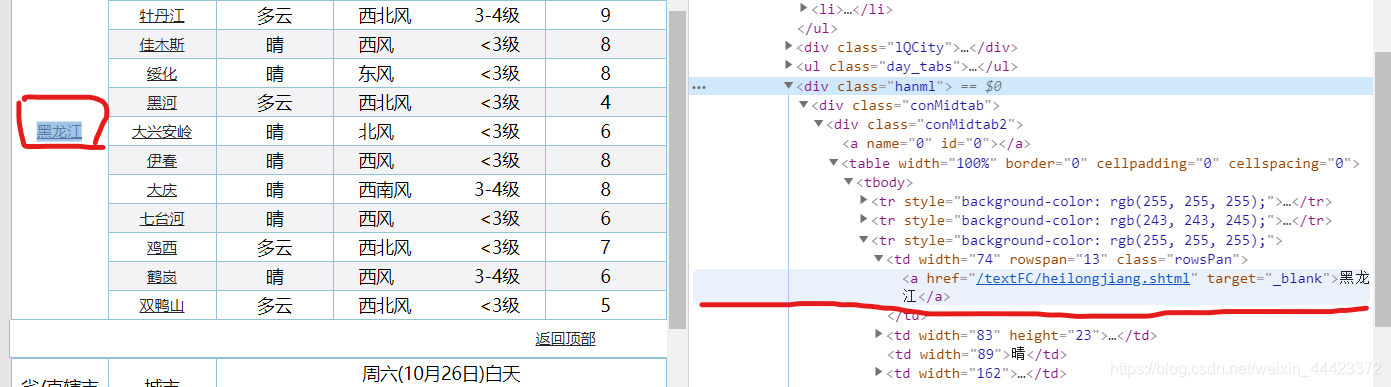
发现第一个标签是黑龙江,
第二个标签才是城市,哈尔滨,是真正的城市名称,那么按之前的取,就会取错,所以将td[0] 换成td[1]
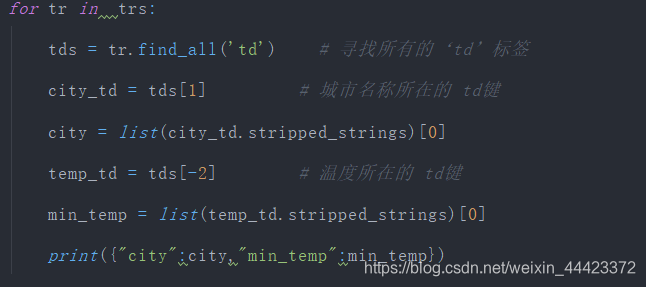
执行

发现,只是第一个哈尔滨是正确的,其余的城市名称都成了天气情况,这是因为把td[0]改成td[1]导致从第二个城市开始,td都是取第一个而并非原来真正的包含城市的名称的哪一个,简单的来说就是只有第一个城市的名称在第一个td[1],其他的城市的名称都在td[0]标签内,这是时候可以使用enumerate函数。
修改一下代码,
import requests
from bs4 import BeautifulSoup
def getHTML(url):
try:
r = requests.get(url)
r.raise_for_status() # 确保连接成功
text = r.content.decode('utf-8') # 确保不会出现乱码情况
except:
return " "
soup = BeautifulSoup(text,'lxml') # 使用‘lxml’解析库的方式,解析html
con = soup.find('div', class_='conMidtab') # 根据开发者工作中,查找标签div,class = 'conMidtab'
tables = con.find_all('table') # 寻找全部的'table' 并赋给 tables
for table in tables: # 做一个循环遍历
trs = table.find_all('tr')[2:] # 寻找从2开始所有的‘tr’,因为第1个为省/直辖市,城市,没有用到
for tr in trs:
tds = tr.find_all('td') # 寻找所有的‘td’标签
city_td = tds[1] # 城市名称所在的 td键
city = list(city_td.stripped_strings)[0]
temp_td = tds[-2] # 温度所在的 td键
min_temp = list(temp_td.stripped_strings)[0]
print({"city":city,"min_temp":min_temp})
def main():
#url = "http://www.weather.com.cn/textFC/hb.shtml" # 华北所有城市
url = "http://www.weather.com.cn/textFC/db.shtml"
getHTML(url)
main()
结果
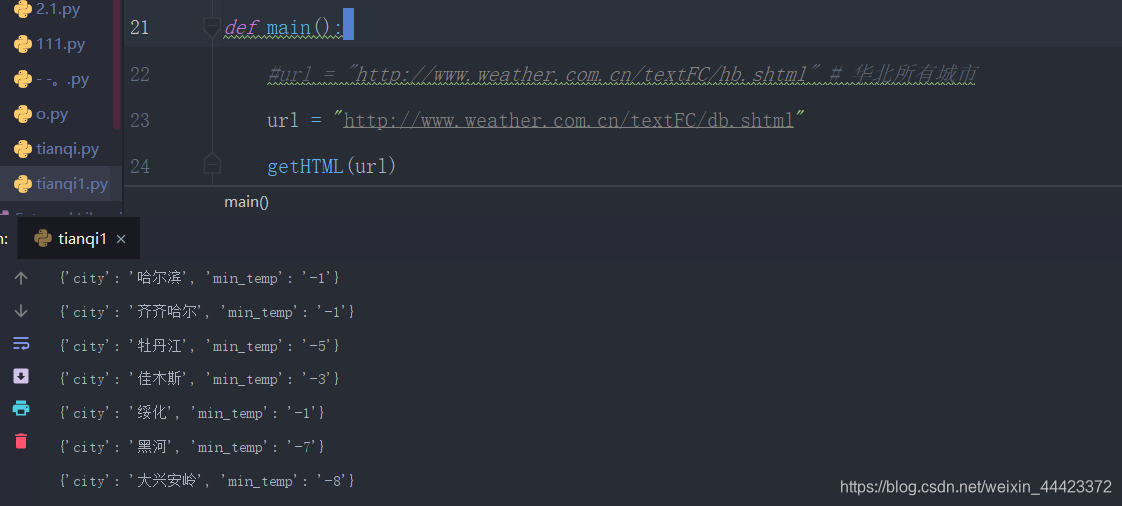
在欣喜的试了其他几个网站,都可以执行,很开心,但。。。。
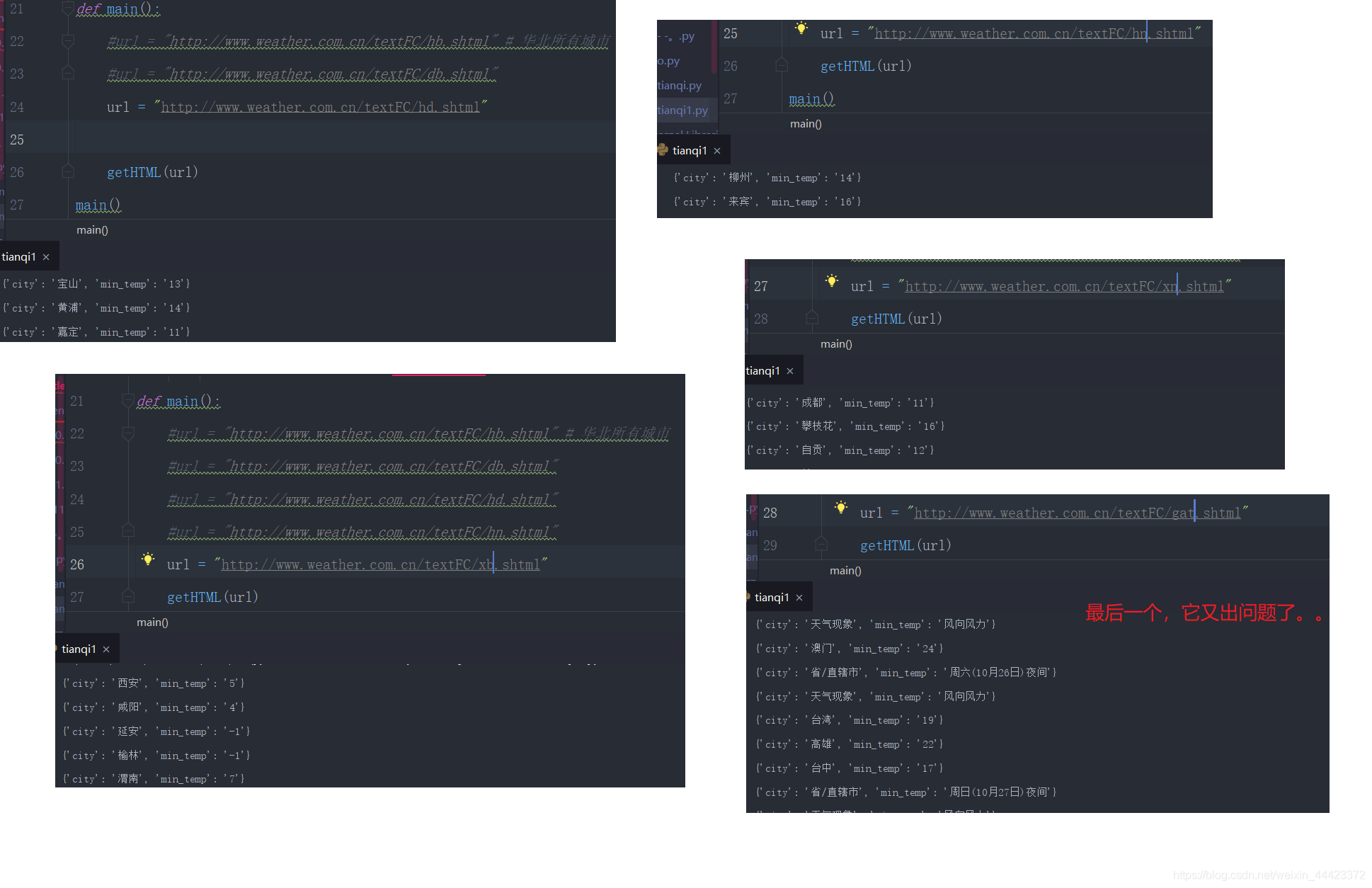
老规矩打开去网站F12,查看
图表格式与之前的不一样,emmmmmm,港澳台就。。。比较特殊。。。。毕竟历史原因嘛。。。。看了看,看出不来跟前者有什么鬼不同。。。
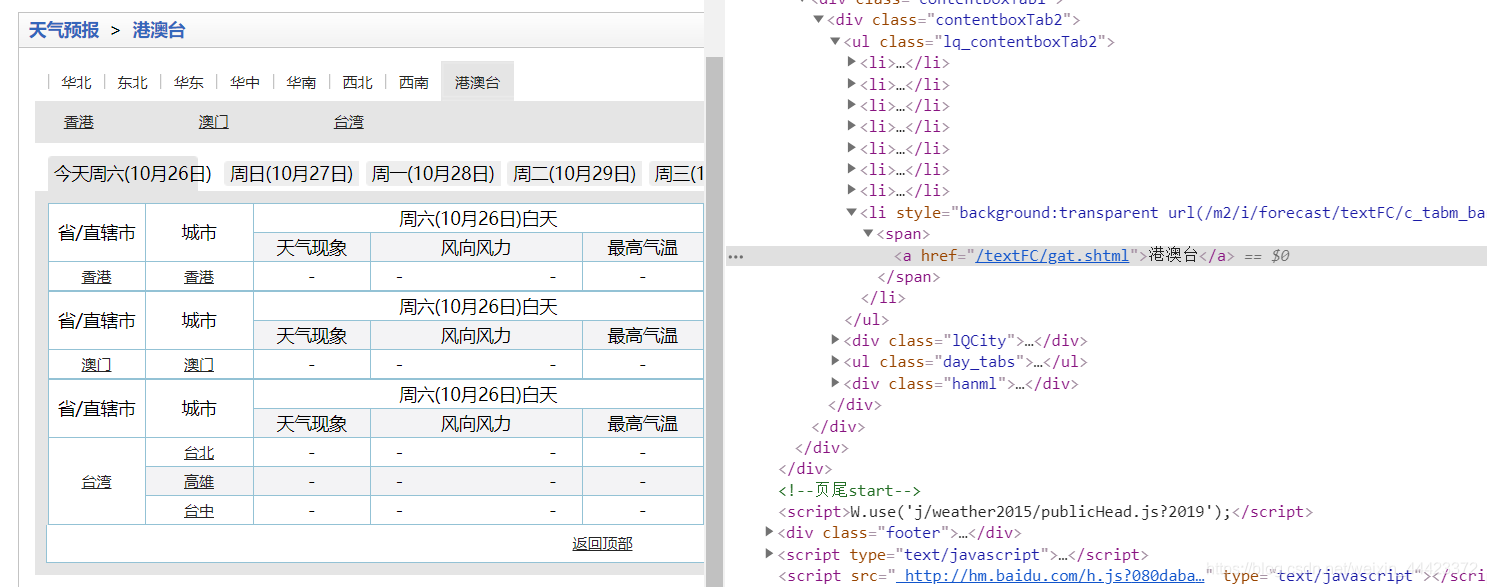
查看源代码,看看,发现了
键只有开始没有结束。。。。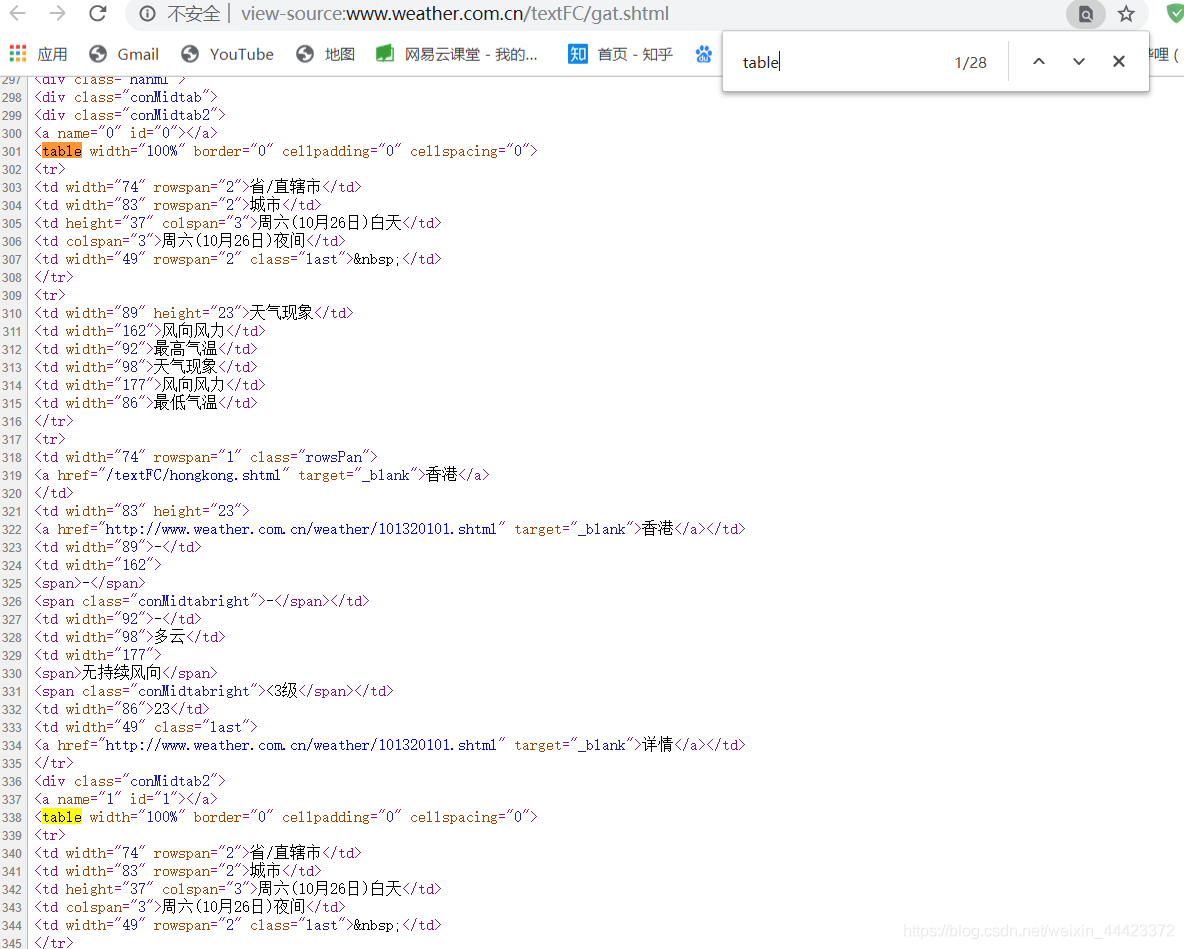
这时候,将之前的’lxml‘的解释器换成’html5lib‘,自动补全,就像刚才在开发者工具中看不原因,是因为开发者工具查看页面代码就是用‘html5lib’,会补全键。
这样就把所有港澳台城市的最低温度都找出来了
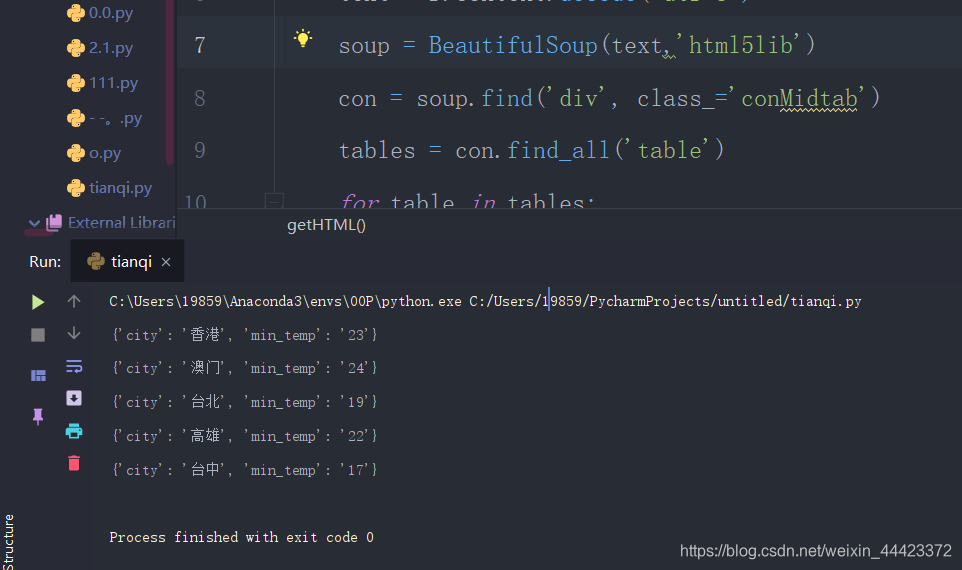
再稍微修改一下下,就可以把全中国所有城市的某日的最低温度的列出来了
import requests
from bs4 import BeautifulSoup
def getHTML(url):
try:
r = requests.get(url) # 确保连接成功
text = r.content.decode('utf-8') # 确保不会出现乱码情况
r.raise_for_status()
except:
return " "
soup = BeautifulSoup(text,'html5lib') # 使用‘html5lib’解析库的方式,解析html
con = soup.find('div', class_='conMidtab') # 根据开发者工作中,查找标签div,class = 'conMidtab'
tables = con.find_all('table') # 寻找全部的'table' 并赋给 tables
for table in tables: # 做一个循环遍历
trs = table.find_all('tr')[2:] # 寻找从2开始所有的‘tr’,因为第1个为省/直辖市,城市,没有用到
for index,tr in enumerate(trs):
tds = tr.find_all('td') # 寻找所有的‘td’标签
city_td = tds[0] # 城市名称所在的 td键
if index == 0: # 东北的页面的判断。。。
city_td = tds[1]
city = list(city_td.stripped_strings)[0]
temp_td = tds[-2] # 温度所在的 td键
min_temp = list(temp_td.stripped_strings)[0]
print({"city":city,"min_temp":min_temp})
def main():
urls = [
"http://www.weather.com.cn/textFC/hb.shtml",
"http://www.weather.com.cn/textFC/db.shtml",
"http://www.weather.com.cn/textFC/hd.shtml",
"http://www.weather.com.cn/textFC/hn.shtml",
"http://www.weather.com.cn/textFC/xb.shtml",
"http://www.weather.com.cn/textFC/xn.shtml",
"http://www.weather.com.cn/textFC/gat.shtml"
]
for url in urls:
getHTML(url)
main()
接下来
将城市最低温度进行排序
#### 下面代码不连贯!!!
ALL_DATA = [] # 定义一个空列表
# ”min_temp":min_temp 中的min_temp是字符串,需要转换成int类型
ALL_DATA.append({"city":city,"min_temp":int(min_temp)})# 将所有城市的温度的数值放入列表中
print({"city":city,"min_temp":int(min_temp)})# 在gethtml类中
ALL_DATA.sort(key=lambda data:data['min_temp']) # 在 main中
print(ALL_DATA)
## 全代码
import requests
from bs4 import BeautifulSoup
ALL_DATA = []
def getHTML(url):
try:
r = requests.get(url) # 确保连接成功
text = r.content.decode('utf-8') # 确保不会出现乱码情况
r.raise_for_status()
except:
return " "
soup = BeautifulSoup(text,'html5lib') # 使用‘html5lib’解析库的方式,解析html
con = soup.find('div', class_='conMidtab') # 根据开发者工作中,查找标签div,class = 'conMidtab'
tables = con.find_all('table') # 寻找全部的'table' 并赋给 tables
for table in tables: # 做一个循环遍历
trs = table.find_all('tr')[2:] # 寻找从2开始所有的‘tr’,因为第1个为省/直辖市,城市,没有用到
for index,tr in enumerate(trs):
tds = tr.find_all('td') # 寻找所有的‘td’标签
city_td = tds[0] # 城市名称所在的 td键
if index == 0: # 东北的页面的判断。。。
city_td = tds[1]
city = list(city_td.stripped_strings)[0]
temp_td = tds[-2] # 温度所在的 td键
min_temp = list(temp_td.stripped_strings)[0]
ALL_DATA.append({"city":city,"min_temp":int(min_temp)})
#print({"city":city,"min_temp":int(min_temp)})
def main():
urls = [
"http://www.weather.com.cn/textFC/hb.shtml",
"http://www.weather.com.cn/textFC/db.shtml",
"http://www.weather.com.cn/textFC/hd.shtml",
"http://www.weather.com.cn/textFC/hn.shtml",
"http://www.weather.com.cn/textFC/xb.shtml",
"http://www.weather.com.cn/textFC/xn.shtml",
"http://www.weather.com.cn/textFC/gat.shtml"
]
for url in urls:
getHTML(url)
ALL_DATA.sort(key=lambda data:data['min_temp'])
data = ALL_DATA[0:20]
print(data)
main()
结果为

pycharm效果不是很好,换IDEA看看


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









