






Java 数据库连接(JDBC)作为 Java 程序与各种关系型数据库之间的桥梁,为我们提供了强大而灵活的数据库操作能力。然而,仅仅掌握基本的 JDBC 操作是远远不够的,在实际开发场景中,我们常常会遇到诸如处理大二进制数据、将数据库数据映射到 Java 对象、获取自增长主键值、批量插入数据以及实现数据库事务等复杂需求。本文将探讨一下这些 JDBC 的高级应用场景,通过代码示例和解释,帮助更好地理解和运用这些技术,从而提升数据库操作的效率和质量。
1. 操作BLOB类型字段
BLOB(Binary Large Object)类型字段用于存储大量的二进制数据,如图片、音频、视频等。操作BLOB类型的数据必须使用 PreparedStatement,因为BLOB类型的数据无法使用字符串拼接写的。
如果在指定了相关的Blob类型以后,还报错:
xxx too large,那么在mysql的安装目录下,找my.ini文件加上如下的配置参数:max_allowed_packet=16M。同时注意:修改了
my.ini文件之后,需要重新启动mysql服务。
1.1 向数据表中插入BLOB类型
插入 BLOB 类型数据通常使用 setBlob 方法。使用 setBlob 方法需要先创建 Blob 对象,再将其设置到 PreparedStatement 中。
//获取连接
public class InsertBlobExample {
public static void main(String[] args) {
String url = "jdbc:mysql://10.10.20.235:3306/rpa_database";
String user = "root";
String password = "root";
try (Connection conn = DriverManager.getConnection(url, user, password)) {
// 假设表名为 your_table,有一个 BLOB 类型的字段名为 blob_column
String sql = "INSERT INTO r_table (blob_column) VALUES (?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
// 读取文件
File file = new File("path/to/your/file.jpg");
try (FileInputStream fis = new FileInputStream(file)) {
// 创建 Blob 对象
Blob blob = conn.createBlob();
blob.setBytes(1, fis.readAllBytes());
// 设置 Blob 对象到 PreparedStatement 中
pstmt.setBlob(1, blob);
pstmt.executeUpdate();
System.out.println("BLOB 数据插入成功");
} catch (IOException e) {
e.printStackTrace();
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
1.2 从数据表中查询BLOB类型
查询 BLOB 类型数据时,可使用 getBlob 方法获取 Blob 对象,再将其转换为字节数组或输出到文件。
public class QueryBlobExample {
public static void main(String[] args) {
String url = "jdbc:mysql://10.10.20.235:3306/rpa_database";
String user = "root";
String password = "root";
try (Connection conn = DriverManager.getConnection(url, user, password)) {
String sql = "SELECT blob_column FROM r_table WHERE id = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, 1); // 假设查询 id 为 1 的记录
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
Blob blob = rs.getBlob("blob_column");
byte[] data = blob.getBytes(1, (int) blob.length());
// 将数据写入文件
try (OutputStream os = new FileOutputStream("path/to/output/file.jpg")) {
os.write(data);
System.out.println("BLOB 数据查询并保存成功");
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
2. 实体类和ORM
在使用JDBC操作数据库时,会发现数据都是零散的,明明在数据库中是一行完整的数据,到了Java中变成了一个一个的变量,不利于维护和管理。
而Java是面向对象的,一个表对应的是一个类,一行数据就对应的是Java中的一个对象,一个列对应的是对象的属性,所以我们要把数据存储在一个载体里,这个载体就是实体类!
- ORM(Object Relational Mapping)思想,对象到关系数据库的映射,作用是在编程中,把面向对象的概念跟数据库中表的概念对应起来,以面向对象的角度操作数据库中的数据,即一张表对应一个类,一行数据对应一个对象,一个列对应一个属性!
- 当下JDBC中这种过程我们称其为手动ORM。后续我们也会学习ORM框架,比如MyBatis、JPA等。
- 实体类举例
package com.test.pojo;
//类名和数据库名对应,但是表名一般缩写,类名要全写!
public class Employee {
private Integer empId;//emp_id = empId 数据库中列名用下划线分隔,属性名用驼峰!
private String empName;//emp_name = empName
private Double empSalary;//emp_salary = empSalary
private Integer empAge;//emp_age = empAge
//省略get、set、无参、有参、toString方法。
}
- JDBC代码
public void querySingleRow() throws SQLException {
//1.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取数据库连接
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root","root");
//3.创建PreparedStatement对象,并预编译SQL语句,使用?占位符
PreparedStatement preparedStatement = connection.prepareStatement("select emp_id,emp_name,emp_salary,emp_age from t_emp where emp_id = ?");
//4.为占位符赋值,索引从1开始,执行SQL语句,获取结果
preparedStatement.setInt(1, 1);
ResultSet resultSet = preparedStatement.executeQuery();
//预先创建实体类变量
Employee employee = null;
//5.处理结果
while (resultSet.next()) {
int empId = resultSet.getInt("emp_id");
String empName = resultSet.getString("emp_name");
Double empSalary = Double.valueOf(resultSet.getString("emp_salary"));
int empAge = resultSet.getInt("emp_age");
//当结果集中有数据,再进行对象的创建
employee = new Employee(empId,empName,empSalary,empAge);
}
System.out.println("employee = " + employee);
//6.释放资源(先开后关原则)
resultSet.close();
preparedStatement.close();
connection.close();
}
3. 自增长主键回显实现
在数据库操作中,自增长主键回显指的是在插入一条新记录后,获取数据库自动生成的自增长主键值。
- MySQL实现自增长主键回显
MySQL 支持在插入数据后通过 Statement.getGeneratedKeys() 方法获取自动生成的主键值。
@Test
public void returnPrimaryKey() throws ClassNotFoundException, SQLException {
// 1.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2.获取连接
Connection connection = DriverManager.getConnection("jdbc:mysql://10.10.20.235/rpa_database", "root", "root");
// 3.编写SQL
String sql = "Insert into rpa_jnhl_customer_table(account,department_code,erp_code) values(?,?,?)";
// 4.创建PS对象
PreparedStatement preparedStatement = connection.prepareStatement(sql,Statement.RETURN_GENERATED_KEYS);
// 5.占位符赋值
preparedStatement.setObject(1,12345);
preparedStatement.setObject(2,201921);
preparedStatement.setObject(3,"LH12345");
// 6.发送SQL语句
int rows = preparedStatement.executeUpdate();
// 7.输出结果
if (rows > 0) {
System.out.println("数据插入成功!");
ResultSet generatedKeys = preparedStatement.getGeneratedKeys();
generatedKeys.next();
int id = generatedKeys.getInt(1);
System.out.println("id:"+ id );
} else {
System.out.println("数据插入失败!");
}
// 8. 关闭资源
preparedStatement.close();
connection.close();
}
【注意点】
- 在创建 PreparedStatement 对象时,使用
PreparedStatement.RETURN_GENERATED_KEYS作为第二个参数,表明要返回自动生成的键,也可以直接使用1代替。- 调用
pstmt.getGeneratedKeys()方法获取包含自动生成主键的 ResultSet 对象,然后从结果集中获取主键值。
4. 批量数据插入
在 JDBC 中进行批量数据插入可以显著提高数据插入的效率,因为它减少了与数据库的交互次数。以下将详细介绍使用 JDBC 进行批量数据插入的方法,包含基本思路、示例代码以及注意事项。
当需要成批插入或者更新记录时,可以采用Java的 批量更新 机制,这一机制允许多条语句一次性提交给数据库批量处理。通常情况下比单独提交处理更有效率。
- mysql服务器默认是关闭批处理的,我们需要通过一个参数,让mysql开启批处理的支持。将
?rewriteBatchedStatements=true写在url后面,允许批量插入。- 插入语句中,不能出现
;结束。注意是插入SQL语句,不是Java语句。- 不是执行每条SQL语句,而是先批量添加之后,统一批量执行。
- 批量处理语句方法:
addBatch(String):添加需要批量处理的SQL语句或是参数;executeBatch():执行批量处理语句;clearBatch():清空缓存的数据;
- 批量插入代码示例
@Test
public void BatchInsert() throws ClassNotFoundException, SQLException {
// 1.注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2.获取连接
Connection connection = DriverManager.getConnection("jdbc:mysql://10.10.20.235/rpa_database?rewriteBatchedStatements=true", "root", "root");
// 3.编写SQL
String sql = "Insert into rpa_jnhl_customer_table(account,department_code,erp_code) values (?,?,?)";
// 4.创建PS对象
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// 5.占位符赋值
for (int i = 0; i < 10000; i++) {
preparedStatement.setObject(1,12345+i);
preparedStatement.setObject(2,201921+i);
preparedStatement.setObject(3,"LH12345"+i);
preparedStatement.addBatch(); // 不执行,追加到values后面
}
// 6.发送SQL语句
int[] ints = preparedStatement.executeBatch();// 执行批量操作
// 7.输出结果
int rows = ints.length;
if (rows > 0) {
System.out.println("数据插入成功!");
} else {
System.out.println("数据插入失败!");
}
// 8. 关闭资源
preparedStatement.close();
connection.close();
}
注意:在批量插入时,建议使用事务处理,以确保数据的一致性。如果在批量插入过程中出现异常,可以使用 conn.rollback() 方法回滚事务。
5. 数据库事务实现
5.1 事务概念
数据库事务是数据库管理系统执行过程中的一个逻辑单元,由一个或多个 SQL 语句组成,这些语句作为一个整体要么全部执行成功,要么全部不执行,以确保数据库的一致性和完整性。
简单来讲就是一组数据库操作,要么一起成功提交操作,要么有失败操作全部回滚到初始状态。
- 事务的特性(ACID)
- 原子性(Atomicity):事务是一个不可分割的工作单位,事务中的所有操作要么都执行,要么都不执行。
- 一致性(Consistency):事务执行前后,数据库的完整性约束没有被破坏。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不能被其他事务干扰,每个事务都感觉不到其他事务在并发执行。
- 持久性(Durability):事务一旦提交,它对数据库所做的修改就会永久保存下来,即使系统出现故障也不会丢失。
- 事务类型
- 自动提交:每条语句自动存储一个事务中,执行成功自动提交,执行失败自动回滚!
- 手动提交:手动开启事务,添加语句,手动提交或者手动回滚即可!
5.2 JDBC事务处理
5.2.1 关闭自动提交
- mysql数据库关闭自动提交,执行语句
SET AUTOCOMMIT = OFF;或者SET AUTOCOMMIT = 0;。- JDBC关闭自动提交,需要执行连接对象的方法
connection.setAutoCommit(false);。
值得注意的是,关闭自动提交并不会百分百实现,对于一些特殊情况,关闭自动提交设置并不会生效。
- 在 MySQL 中,使用 ALTER TABLE、CREATE INDEX 等数据定义语言(DDL)语句时,无论 AUTOCOMMIT 的设置如何,这些操作都会隐式地提交当前事务。这是因为 DDL 操作通常会对数据库的结构产生影响,为了保证数据一致性,数据库会自动提交事务。
- 某些数据库连接池或数据库驱动可能会忽略 SET AUTOCOMMIT 的设置,而使用其自身的默认配置。在使用一些 Java 数据库连接池(如 HikariCP)时,如果连接池配置中设置了 autoCommit 属性为 true,那么即使在应用程序中执行 SET AUTOCOMMIT = 0,也可能无法关闭自动提交,因为连接池的设置会覆盖数据库层面的设置。
- 在存储过程或函数内部,如果没有正确处理事务,即使外部设置了关闭自动提交,也可能无法按预期生效。例如存储过程中可能包含了自动提交的语句,或者没有遵循事务的正确提交和回滚逻辑,导致事务在存储过程执行过程中自动提交。
- 当数据库连接因网络问题、超时等原因断开后又重新连接时,可能会恢复到默认的自动提交模式。这是因为重新建立连接时会使用默认的连接参数,之前设置的 SET AUTOCOMMIT = 0 就会失效。
如果多个操作,每个操作使用的是自己单独的连接,则无法保证事务。即同一个事务的多个操作必须在同一个连接下。 还有,默认在关闭连接时,会自动的提交数据。
5.2.2 作为一个事务执行
在 JDBC 里,若要让多个 SQL 语句作为一个事务执行,你可以按以下步骤操作:
- 关闭自动提交模式。调用 Connection 对象的
setAutoCommit(false)以取消自动提交事务。
执行一系列 SQL 语句。 - 若所有语句都执行成功,就调用
commit()方法提交事务; - 若有语句执行失败,就调用
rollback()方法回滚到最近一次提交之后。
若此时 Connection 没有被关闭,还可能被重复使用,则需要恢复其自动提交状态 setAutoCommit(true)。尤其是在使用数据库连接池技术时,执行close()方法前,建议恢复自动提交状态。
5.2.3 转账举例
- 数据表数据
-- 维续在数据库中创建银行表
CREATE TABLE t_bank(
id INT PRINARY KEY AUTO_INCREMENT COMMENT '账号主键',
account VARCHAR(20) NOT NULL UNIQUE COMMENT '账号',
money INT UNSIGNED COMHENT '金额,不能为负值');
INSERT INTO t_bank(account,money) VALUES ('ergouzi',1000),('lvdandan',1000);
- 代码结构设计
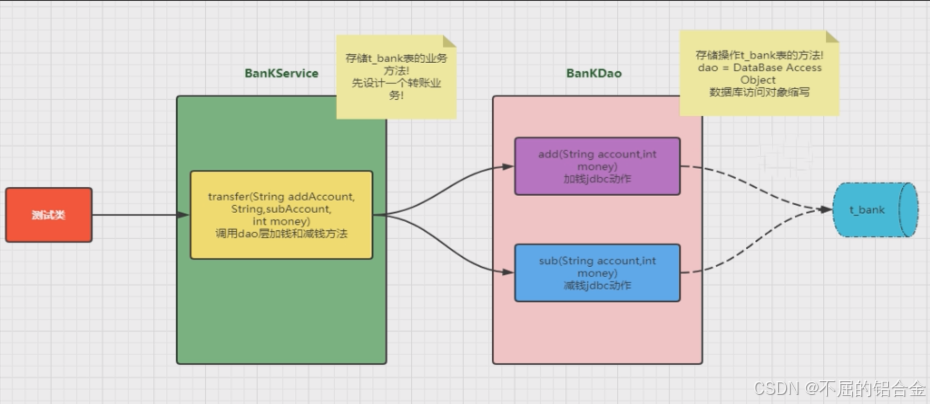
- BankDao类
package com.test.expand;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class BankDao {
/**
* 加钱方法
* @param account
* @param money
* @param connection 业务传递的connection和减钱是同一个! 才可以在一个事务中!
* @return 影响行数
*/
public int addMoney(String account, int money,Connection connection) throws ClassNotFoundException, SQLException {
String sql = "update t_bank set money = money + ? where account = ? ;";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//占位符赋值
preparedStatement.setObject(1, money);
preparedStatement.setString(2, account);
//发送SQL语句
int rows = preparedStatement.executeUpdate();
//输出结果
System.out.println("加钱执行完毕!");
//关闭资源close
preparedStatement.close();
return rows;
}
/**
* 减钱方法
* @param account
* @param money
* @param connection 业务传递的connection和加钱是同一个! 才可以在一个事务中!
* @return 影响行数
*/
public int subMoney(String account, int money,Connection connection) throws ClassNotFoundException, SQLException {
String sql = "update t_bank set money = money - ? where account = ? ;";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//占位符赋值
preparedStatement.setObject(1, money);
preparedStatement.setString(2, account);
//发送SQL语句
int rows = preparedStatement.executeUpdate();
//输出结果
System.out.println("减钱执行完毕!");
//关闭资源close
preparedStatement.close();
return rows;
}
}
- BankService类
package com.test.expand;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class BankService {
/**
* 转账业务方法
* @param addAccount 加钱账号
* @param subAccount 减钱账号
* @param money 金额
*/
public void transfer(String addAccount,String subAccount, int money) throws ClassNotFoundException, SQLException {
System.out.println("addAccount = " + addAccount + ", subAccount = " + subAccount + ", money = " + money);
//注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//获取连接
Connection connection = DriverManager.getConnection("jdbc:mysql://10.10.20.235/test", "root", "root");
int flag = 0;
//利用try代码块,调用dao
try {
//开启事务(关闭事务自动提交)
connection.setAutoCommit(false);
BankDao bankDao = new BankDao();
//调用加钱 和 减钱
bankDao.addMoney(addAccount,money,connection);
System.out.println("--------------");
bankDao.subMoney(subAccount,money,connection);
flag = 1;
//不报错,提交事务
connection.commit();
}catch (Exception e){
//报错回滚事务
connection.rollback();
throw e;
}finally {
connection.close();
}
if (flag == 1){
System.out.println("转账成功!");
}else{
System.out.println("转账失败!");
}
}
}
- 测试类
package com.test.expand;
import org.junit.Test;
public class BankTest {
@Test
public void testBank() throws Exception {
BankService bankService = new BankService();
bankService.transfer("ergouzi", "lvdandan",
500);
}
}
6. JDBC工具类封装
JDBC工具类封装通过将获取连接、释放资源等通用代码提取封装,解决了代码重复问题,提高了代码复用性;通过规范资源获取和释放逻辑,避免了资源泄漏,保障了系统稳定性;当数据库配置变更时只需在工具类一处修改,提升了代码可维护性;同时,通过参数检查过滤和隐藏敏感信息增强了系统安全性;还将业务与数据库操作代码分离,优化了代码结构,提高了代码可读性。
6.1 JDBC工具类封装V1.0
db.properties配置文件:
# druid连接池需要的配置参数,key固定命名
driverClassName=com.mysql.cj.jdbc.Driver
username=root
password=root
url=jdbc:mysql://……/test
- 工具类代码:
/**
* JDBC工具类(V1.0):
* 1、维护一个连接池对象。
* 2、对外提供在连接池中获取连接的方法
* 3、对外提供回收连接的方法
* 注意:工具类仅对外提供共性的功能代码,所以方法均为静态方法!
*/
public class JDBCTools {
//创建连接池引用,因为要提供给当前项目全局使用,所以创建为静态的。
private static DataSource dataSource;
//在项目启动时,即创建连接池对象,赋值给dataSource
static{
try {
Properties properties = new Properties();
InputStream inputStream = JDBCTools.getClass().getClassLoader().getSystemResourceAsStream("db.properties");
properties.load(inputStream);
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
//对外提供获取连接的静态方法!
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
//对外提供回收连接的静态方法
public static void release(Connection conn) throws SQLException {
conn.close();//还给连接池
}
}
注意问题:此种封装方式,无法保证单个请求连接的线程,多次操作数据库时连接是同一个,无法保证事务!
6.2 ThreadLocal
JDK 1.2的版本中就提供
java.lang.ThreadLocal,为解决多线程程序的并发问题提供了一种新的思路。使用这个工具类可以很简洁地编写出优美的多线程程序。通常用来在在多线程中管理共享数据库连接、Session等。
ThreadLocal用于保存某个线程共享变量,原因是在Java中,每一个线程对象中都有一个
ThreadLocalMap<ThreadLocal, Object>,其key就是一个ThreadLocal,而Object即为该线程的共享变量。而这个map是通过ThreadLocal的set和get方法操作的。对于同一个static ThreadLocal,不同线程只能从中get,set,remove自己的变量,而不会影响其他线程的变量。
1、ThreadLocal对象.get:获取ThreadLocal中当前线程共享变量的值。
2、ThreadLocal对象.set:设置ThreadLocal中当前线程共享变量的值。
3、ThreadLocal对象.remove:移除ThreadLocal中当前线程共享变量的值。
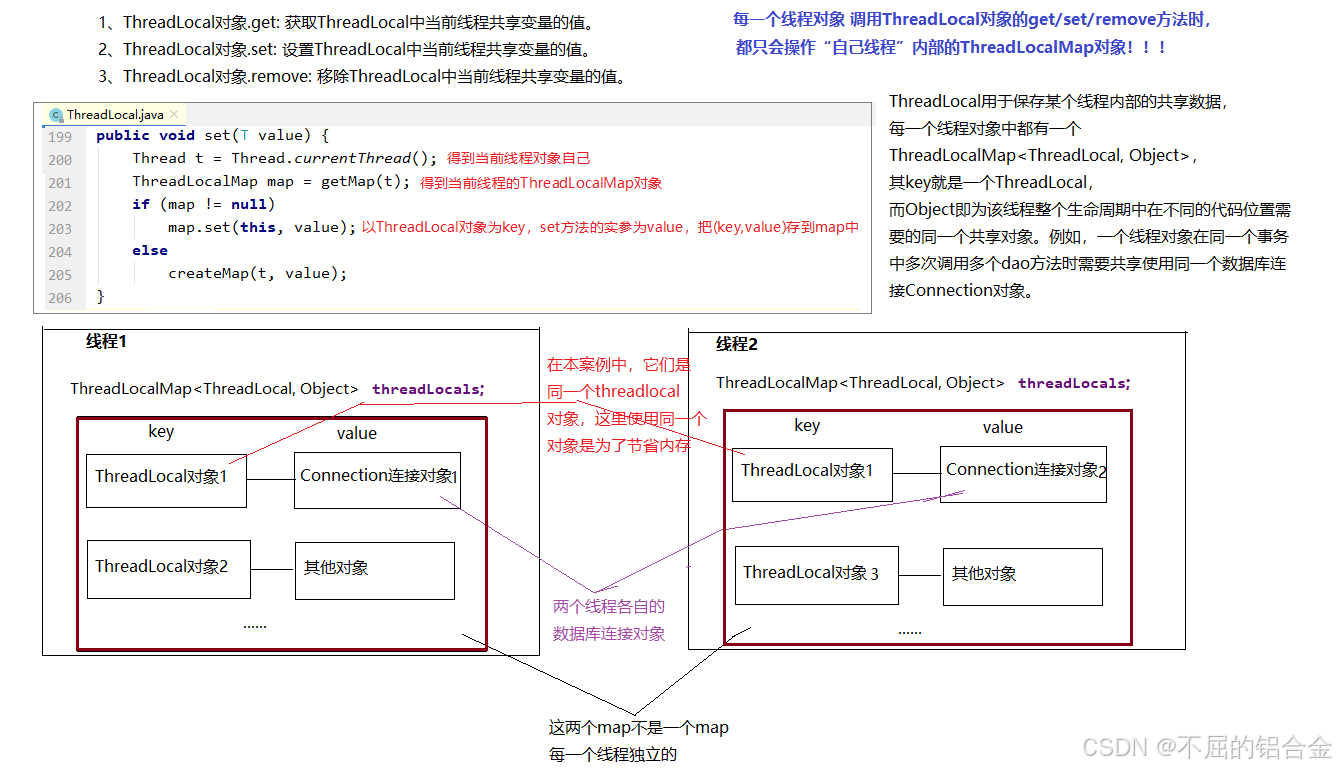
6.3 JDBC工具类封装V2.0
在V1.0的版本基础上,将连接对象放在每个线程的ThreadLocal中,保证从头到尾当前线程操作的是同一连接对象。
代码实现:
/**
* JDBC工具类(V2.0):
* 1、维护一个连接池对象、维护了一个线程绑定变量的ThreadLocal对象
* 2、对外提供在ThreadLocal中获取连接的方法
* 3、对外提供回收连接的方法,回收过程中,将要回收的连接从ThreadLocal中移除!
* 注意:工具类仅对外提供共性的功能代码,所以方法均为静态方法!
* 注意:使用ThreadLocal就是为了一个线程在多次数据库操作过程中,使用的是同一个连接!
*/
public class JDBCUtilV2 {
//创建连接池引用,因为要提供给当前项目的全局使用,所以创建为静态的。
private static DataSource dataSource;
private static ThreadLocal<Connection> threadLocal = new ThreadLocal<>();
//在项目启动时,即创建连接池对象,赋值给dataSource
static {
try {
Properties properties = new Properties();
InputStream inputStream = JDBCUtil.class.getClassLoader().getResourceAsStream("db.properties");
properties.load(inputStream);
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
//对外提供在连接池中获取连接的方法
public static Connection getConnection(){
try {
//在ThreadLocal中获取Connection、
Connection connection = threadLocal.get();
//threadLocal里没有存储Connection,也就是第一次获取
if (connection == null) {
//在连接池中获取一个连接,存储在threadLocal里。
connection = dataSource.getConnection();
threadLocal.set(connection);
}
return connection;
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
//对外提供回收连接的方法
public static void release(){
try {
Connection connection = threadLocal.get();
if(connection!=null){
//从threadLocal中移除当前已经存储的Connection对象
threadLocal.remove();
//如果开启了事务的手动提交,操作完毕后,归还给连接池之前,要将事务的自动提交改为true
connection.setAutoCommit(true);
//将Connection对象归还给连接池
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
7. Apache-DBUtils工具类库
7.1 DBUtils简介
commons-dbutils 是 Apache 组织提供的一个开源 JDBC工具类库,它是对JDBC的简单封装,学习成本极低,并且使用dbutils能极大简化jdbc编码的工作量,同时也不会影响程序的性能。
- API介绍:
org.apache.commons.dbutils.QueryRunnerorg.apache.commons.dbutils.ResultSetHandler- 工具类:
org.apache.commons.dbutils.DbUtils
- API包说明:
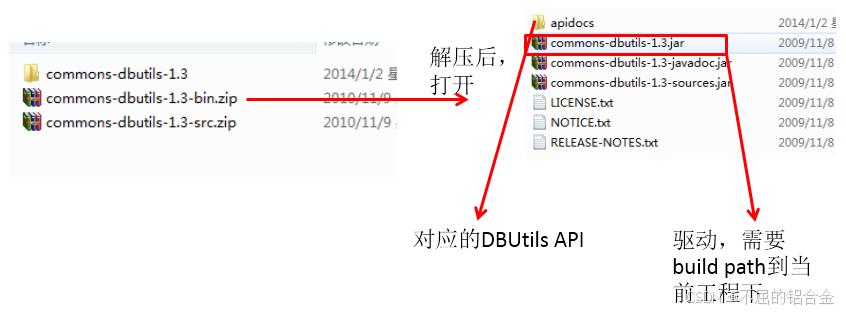

7.2 主要API的使用
7.2.1 DbUtils
DbUtils是 Apache Commons DbUtils 库中的一个工具类,它提供了一系列静态方法,用于处理 JDBC 操作中的一些常见任务,如关闭连接、加载 JDBC 驱动程序、处理异常等。
主要方法及介绍
- 加载 JDBC 驱动程序
// 加载指定的 JDBC 驱动程序。
public static void loadDriver(String driverClassName) throws ClassNotFoundException
- 关闭资源
DbUtils 提供了多个重载的 close 方法,用于关闭 Connection、Statement 和 ResultSet 等资源。
// 关闭单个资源
public static void close(Connection conn) throws SQLException
public static void close(Statement stmt) throws SQLException
public static void close(ResultSet rs) throws SQLException
// 关闭多个资源
public static void close(Connection conn, Statement stmt, ResultSet rs) throws SQLException
- 安静关闭资源
DbUtils 还提供了一系列以 closeQuietly 命名的方法,用于安静地关闭资源,即不抛出异常。
// 安静关闭单个资源
public static void closeQuietly(Connection conn)
public static void closeQuietly(Statement stmt)
public static void closeQuietly(ResultSet rs)
// 安静关闭多个资源
public static void closeQuietly(Connection conn, Statement stmt, ResultSet rs)
- 回滚事务
// 对指定的数据库连接进行回滚操作
public static void rollback(Connection conn) throws SQLException
// 对指定的数据库连接进行回滚操作,不抛出异常
public static void rollbackQuietly(Connection conn)
DbUtils 类提供的这些静态方法,能够帮助开发者更方便地处理 JDBC 操作中的常见任务,减少样板代码的编写,提高开发效率。同时,通过安静关闭和回滚方法,可以避免在资源关闭和事务回滚时抛出异常,使代码更加健壮。
7.2.2 QueryRunner类
该类简单化了SQL查询,它与ResultSetHandler组合在一起使用可以完成大部分的数据库操作,能够大大减少编码量。
提供了两个常用的构造器:
- 无参构造器
public QueryRunner()
创建一个 QueryRunner 对象,使用该构造器创建的对象在执行 SQL 语句时,需要在调用具体方法(如 query、update)时手动传入 Connection 对象。这种方式适合在需要对数据库连接进行精细控制的场景,例如在一个事务中需要多次使用同一个连接执行不同的 SQL 语句。
- 带数据源构造器
public QueryRunner(DataSource ds)
创建一个 QueryRunner 对象,并传入一个 DataSource 对象。使用该构造器创建的对象在执行 SQL 语句时,会自动从 DataSource 中获取数据库连接,执行完操作后会自动关闭连接(如果 DataSource 支持连接池管理)。这种方式适合在使用连接池管理数据库连接的场景,能够简化连接的获取和释放过程。
QueryRunner类的主要方法:
QueryRunner 类是 Apache Commons DbUtils 库中的核心类,为 JDBC 操作提供了简化方案,涵盖查询、更新、插入、批处理等常见操作。以下为你详细介绍其主要方法:
- 查询操作
query(Connection conn, String sql, ResultSetHandler<T> rsh, Object... params)
// 在指定的数据库连接conn上执行带参数的 SQL 查询语句,使用ResultSetHandler接口的实现类rsh处理查询结果,params是 SQL 语句中的参数。
query(String sql, ResultSetHandler<T> rsh, Object... params)`
// 使用构造QueryRunner时传入的数据源获取连接,执行带参数的SQL查询语句,用 ResultSetHandler处理结果,params是SQL语句中的参数。
- 更新操作
update(Connection conn, String sql, Object... params)
// 在指定的数据库连接conn上执行带参数的SQL更新语句(如 UPDATE),params是SQL语句中的参数,返回受影响的行数。
update(String sql, Object... params)
// 使用构造QueryRunner时传入的数据源获取连接,执行带参数的SQL更新语句,params是SQL语句中的参数,返回受影响的行数。
- 插入操作
插入操作本质上也是一种更新操作,所以使用的方法和更新操作相同,
update(Connection conn, String sql, Object... params)
update(String sql, Object... params)
- 批处理操作
batch(Connection conn, String sql, Object[][] params)
// 在指定的数据库连接conn上执行批量SQL更新语句(如批量插入、更新),params是一个二维数组,每一行代表一组参数。
batch(String sql, Object[][] params)
// 使用构造QueryRunner时传入的数据源获取连接,执行批量SQL更新语句,params是一个二维数组,每一行代表一组参数。
- 测试
// 测试添加
@Test
public void testInsert() throws Exception {
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "insert into customers(name,email,birth)values(?,?,?)";
int count = runner.update(conn, sql, "何成飞", "he@qq.com", "1992-09-08");
System.out.println("添加了" + count + "条记录");
JDBCUtils.closeResource(conn, null);
}
// 测试删除
@Test
public void testDelete() throws Exception {
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "delete from customers where id < ?";
int count = runner.update(conn, sql,3);
System.out.println("删除了" + count + "条记录");
JDBCUtils.closeResource(conn, null);
}
7.2.3 ResultSetHandler接口及实现类
ResultSetHandler 是 Apache Commons DbUtils 库中的一个核心接口,其主要作用是将 ResultSet(结果集)转换为特定类型的 Java 对象。
该接口提供了一个单独的方法:Object handle (java.sql.ResultSet .rs)。
接口的主要实现类:
ArrayHandler:把结果集中的第一行数据转成对象数组。ArrayListHandler:把结果集中的每一行数据都转成一个数组,再存放到List中。BeanHandler:将结果集中的第一行数据封装到一个对应的JavaBean实例中。BeanListHandler:将结果集中的每一行数据都封装到一个对应的JavaBean实例中,存放到List里。ColumnListHandler:将结果集中某一列的数据存放到List中。KeyedHandler(name):将结果集中的每一行数据都封装到一个Map里,再把这些map再存到一个map里,其key为指定的key。MapHandler:将结果集中的第一行数据封装到一个Map里,key是列名,value就是对应的值。MapListHandler:将结果集中的每一行数据都封装到一个Map里,然后再存放到ListScalarHandler:查询单个值对象
/*
* 测试查询:查询一条记录
*
* 使用ResultSetHandler的实现类:BeanHandler
*/
@Test
public void testQueryInstance() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "select id,name,email,birth from customers where id = ?";
//
BeanHandler<Customer> handler = new BeanHandler<>(Customer.class);
Customer customer = runner.query(conn, sql, handler, 23);
System.out.println(customer);
JDBCUtils.closeResource(conn, null);
}
/*
* 测试查询:查询多条记录构成的集合
*
* 使用ResultSetHandler的实现类:BeanListHandler
*/
@Test
public void testQueryList() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "select id,name,email,birth from customers where id < ?";
//
BeanListHandler<Customer> handler = new BeanListHandler<>(Customer.class);
List<Customer> list = runner.query(conn, sql, handler, 23);
list.forEach(System.out::println);
JDBCUtils.closeResource(conn, null);
}
/*
* 自定义ResultSetHandler的实现类
*/
@Test
public void testQueryInstance1() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
String sql = "select id,name,email,birth from customers where id = ?";
ResultSetHandler<Customer> handler = new ResultSetHandler<Customer>() {
@Override
public Customer handle(ResultSet rs) throws SQLException {
System.out.println("handle");
// return new Customer(1,"Tom","tom@126.com",new Date(123323432L));
if(rs.next()){
int id = rs.getInt("id");
String name = rs.getString("name");
String email = rs.getString("email");
Date birth = rs.getDate("birth");
return new Customer(id, name, email, birth);
}
return null;
}
};
Customer customer = runner.query(conn, sql, handler, 23);
System.out.println(customer);
JDBCUtils.closeResource(conn, null);
}
/*
* 如何查询类似于最大的,最小的,平均的,总和,个数相关的数据,
* 使用ScalarHandler
*
*/
@Test
public void testQueryValue() throws Exception{
QueryRunner runner = new QueryRunner();
Connection conn = JDBCUtils.getConnection3();
//测试一:
// String sql = "select count(*) from customers where id < ?";
// ScalarHandler handler = new ScalarHandler();
// long count = (long) runner.query(conn, sql, handler, 20);
// System.out.println(count);
//测试二:
String sql = "select max(birth) from customers";
ScalarHandler handler = new ScalarHandler();
Date birth = (Date) runner.query(conn, sql, handler);
System.out.println(birth);
JDBCUtils.closeResource(conn, null);
}
通过本文的介绍,了解了 JDBC 的多种高级应用场景,从 BLOB 类型字段的操作到实体类与 ORM 的结合,从自增长主键回显到批量数据插入,再到数据库事务的实现,这些技术在实际开发中都具有重要的应用价值。希望大家在掌握这些知识后,能够更加灵活、高效地使用 JDBC 进行数据库操作,解决实际开发中遇到的各种问题。

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









