







前言
- mysql:关系型数据库,支持事务,单节点存储数据量有限
- hbase:数据库、可存储海量数据、不太支持sql、存k-v取value比较快、不适合分析做报表
- hive:数仓工具,底层转成mr程序处理和分析数据、良好的SQL语法、便于分析做报表、但是慢
- clickhouse:存储海量数据、快速查询、多维度多运算模型
clickhouse简介
- 开源的用于OLAP的列式数据库管理系统(DBMS),主要用于在线分析处理查询,能够使用SQL查询实时生成分析数据报告
- 全称:click stream,data warehouse
- 允许运行时创建表和数据库,加载数据和运行查询,无需重新配置和重新启动服务器,支持线性扩展,简单方便高可靠容错
- 在大数据领域没有走Hadoop生态,采用Local attached storage作为存储,整个IO没有Hadoop的局限。它的系统在生产环境中可以应用较大的规模,它的线性扩展能力和可靠性保证能够原生支持shard + replication解决方案,提供SQL直接接口,有比较丰富的原生client(嘛意思?)
1.优点
- 灵活的MPP架构,支持线性扩展,方便高可靠
- 多服务器分布时处理数据,完备的DBMS系统
- 底层数据列式存储,支持压缩,优化数据存储,优化索引数据
- 容错跑分快,可处理数据级别达到10亿级别
- 功能多,支持数据统计分析各种场景,支持类SQL查询,异地复制部署
总之:海量数据存储,分布时运算,快速闪电性能,几乎实时的数据分析,友好的SQL语法,出色的函数支持
2.缺点
- 不支持事务,不支持真正的删除/更新
- 不支持高并发、qps官方建议100,服务器足够好时可通过配置文件增加连接数
- 不支持二级索引
- 不擅长多表join(咋弄?创建个大宽表)
- 元数据管理需要人为干预
- 尽量做1000以上批量写入,避免逐行insert或小批量insert,update,delete操作
3.应用场景
- 绝大多数请求都是读访问的,要求实时返回结果
- 数据需要以大批次进行更新,不是单行更新,根本没有更新
- 数据只添加到数据库,没有必要修改
- 读取数据时,从数据库中提取大量的行,少量的列
- 宽表
- 查询频率低
- 对于简单查询允许50ms的延迟
- 列的值较小
- 处理单个查询时需要高吞吐量
- 不需要事务
- 数据一致性要求低
- 每次查询只会查询一个大表,其余都是小表
- 查询结果显著小于数据源,即数据有过滤和聚合
4.核心概念
1.数据分片:
- 数据分片是将数据进行横向切分,这是一种在面对海量数据场景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现,clickhouse支持分片,分片依赖于集群,每个集群由1到多个分片组成,每个分片对应于一个服务器节点,所以分片的数量上限取决于节点数量。
- clickhouse不具备高度自动化分片功能,clickhouse提供了本地表和分布式表的概念,一张本地表等同于一份数据分片,分布式表不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片从而实现分布式查询。
2.列式存储
- 同一列的数据存一块,这样取多行某列数据时就会比行式存储快
3.向量化
- clickhouse不仅将数据按列存储,也按照列进行计算,传统OLTP数据库通常按行计算,事务处理中以点查为主,SQL计算量小按行计算也无所谓,但是分析场景单个SQL涉及的计算量很大,将每行作为一个基本单元进行处理带来严重的性能损耗
- 对每行数据都要调用相应的函数,函数调用开销占比高
- 存储层按列存储数据,内存中也按列组织,计算层按行处理,无法充分利用CPU cache的预读能力
- 按行处理,无法利用高效的SIMD指令
- clickhouse实现了向量执行引擎,对内存中的列式数据,一个batch调用一次SIMD指令(非一行执行一次),不仅减少了函数调用次数,降低了cache miss,而且可以发挥SIMD指令的并行能力,缩短计算耗时。
- SIMD全称单指令多数据流,能够复制多个操作数,并把他们打包在大型寄存器的一组指令集,以同步的方式在同一时间内执行同一条指令。
4.表
- 上层数据的视图展示概念,包括表的基本结构和数据
- 说人话就是你理解的意思
5.分区
- clickhouse支持PARTITION BY子句,建表时可以指定按照任意合法表达式进行数据分区操作,比如toYYYYMM()按照月进行分区、对enum类型的列直接每种取值作为一个分区等,数据以分区的形式统一管理和维护一批数据
6.副本
- 数据存储副本,实现高可用,在CK中通过复制集,保障可靠性,增加CK查询的并发能力
- 基于Zookeeper的表复制方式
- 基于Cluster的复制方式
- 推荐数据写入方式本地表写入,禁止分布式表写入,所以复制表时只考虑基于Zookeeper的表复制方式
7.引擎
- 不同引擎决定了表数据的存储特点和对表的操作行为
- 决定表存储在哪里以及以何种方式存储
- 支持哪些查询以及如何支持
- 并发数据访问
- 索引的使用
- 是否可以执行多线程请求
- 数据复制参数
- 表引擎决定数据在文件系统中的存储方式,常用的也是官方推荐的存储引擎时MergeTree系列,如果需要副本那就用ReplicatedMergeTree系列,相当于MergeTree的副本版本,读取集群数据需要使用分布式表引擎Distribution
clickhouse安装
- 官网
- service clickhouse-service start
- 默认配置文件位置为/etc/clickhouse-server/config.xml
- 工作目录在/var/lib/clickhouse下
- 默认端口号9000
- show databases;展示系统默认的两个数据库default和system
端口信息
- netstate -nltp
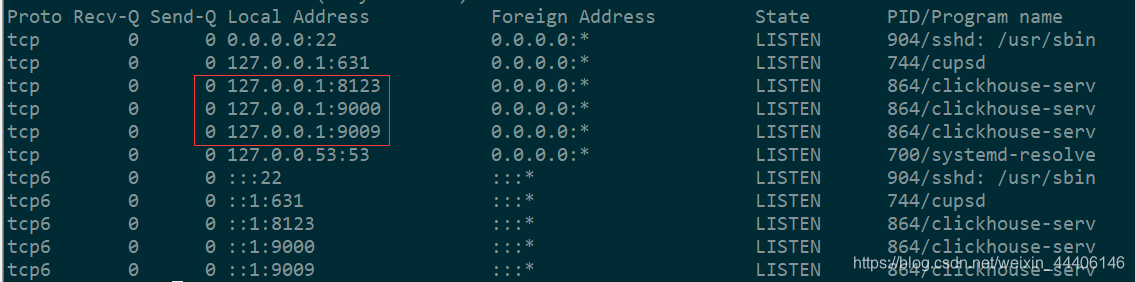
- 找到默认配置文件 /etc/clickhouse-server/config.xml
 - jdbc连就写8123
- jdbc连就写8123
客户端参数
- 创建数据库:CREATE DATABASE IF NOT EXISTS test1
- 使用数据库test1:USE test1
- 查看当前使用的数据库:SELECT currentDatabase()
- 不能向mysql一样写多行命令以;结尾,除非指定-m

clickhouse开放其他机器访问权限
- 指定host后发现连不上

- 默认配置文件信息显示只让localhost连

- 那就设置让所有的都能连呗

- 注意把服务重启下才能生效 service clickhouse-server restart
clickhouse目录结构
- 配置文件目录 /etc/clickhouse-server

- 工作目录 /var/lib/clickhouse
 - 日志目录 /var/log/clickhouse-server
- 日志目录 /var/log/clickhouse-server

clickhouse数据类型
- 建表语句
- clickhouse建表时候专属于CK的关键字有大小写区分
1.数值类型
- 固定长度的整型,包括有符号整型或无符号整型:UInt8,UInt16,UInt32,UInt64,Int8,Int16,Int32,Int64
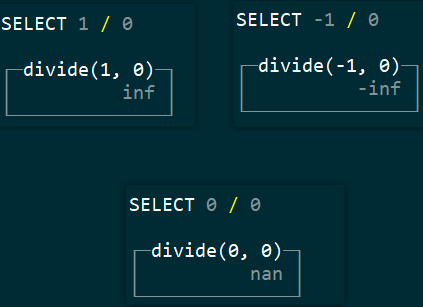
- 会丢生精度的浮点数:Float32,Float64,NaN,Inf
2.字符串类型
- String
- FixedString
- UUID三类
- CK语法具备数据+运算的特征
3.时间类型
- Date:不包括具体的时间信息,只精确到天,支持字符串形式写入
- DateTime:[1970-01-01 00:00:00, 2105-12-31 23:59:59]
- DateTime64:允许存储一个瞬间,可以表示为日历日期和一天中的时间,Tick size (precision): 10-precision seconds
- 还是看官网的英文文档比较全
- Enum8,用 ‘String’= Int8 对描述。
- Enum16,用 ‘String’= Int16 对描述。
- Enum 保存 ‘string’= integer 的对应关系。在 ClickHouse 中,尽管用户使用的是字符串常量,但所有含有 Enum 数据类型的操作都是按照包含整数的值来执行。这在性能方面比使用 String 数据类型更有效。
5.数组类型
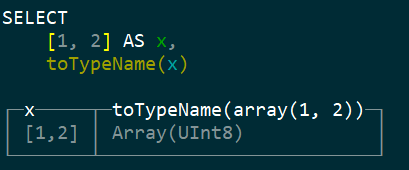
- CK支持数组这种复合数据类型
- array(T),SELECT array(1, 2) AS x, toTypeName(x)
- [],SELECT [1, 2] AS x, toTypeName(x)
6.Tuple类型
- 每个数据都有单独的类型

7.嵌套数据结构
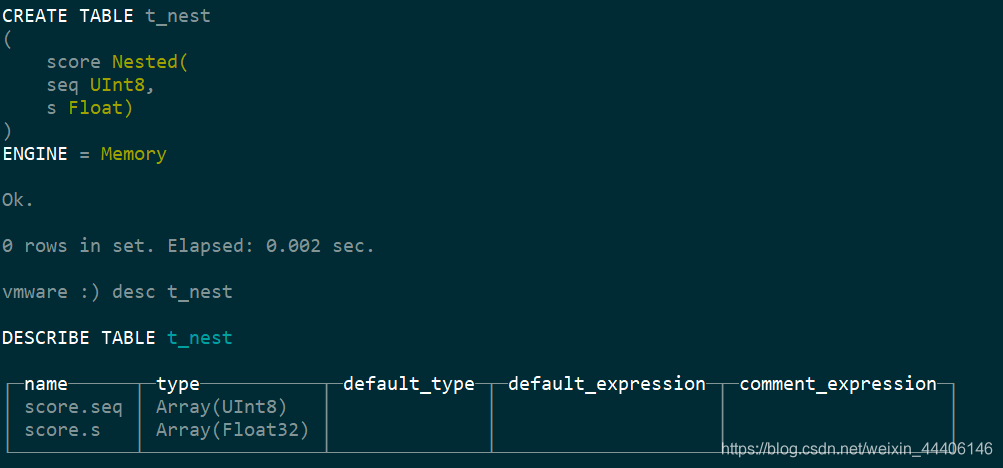
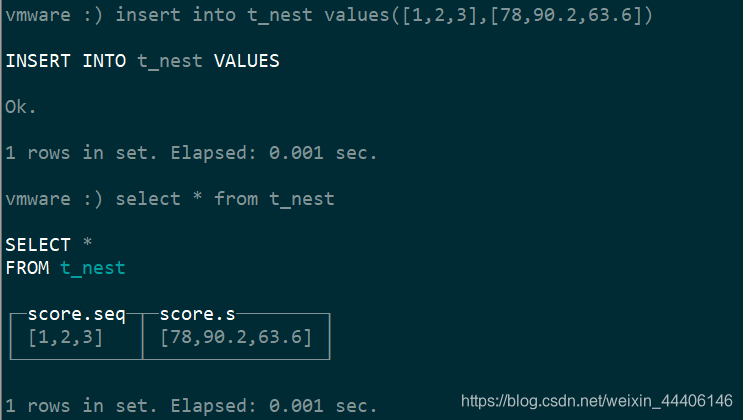
9.GEO
- ClickHouse 支持用于表示地理对象的数据类型——位置、土地等。
- Point
- Ring
- Polygon
- MultiPolygon
10.Domain类型
11.Nullable
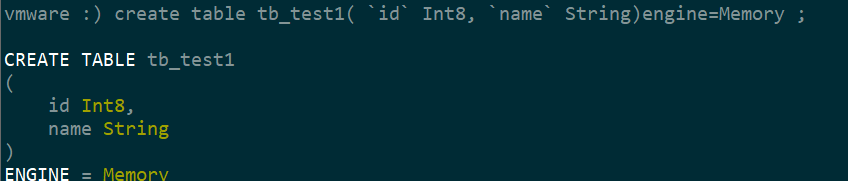
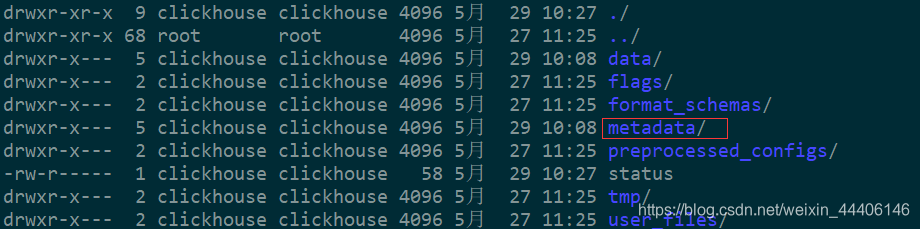
元数据手动维护
- 上边操作的所有都是使用了Memory引擎,那么重启服务后应该看不到表及表中数据
- 但是能看到表名,但是表中没有数据
- 原因是都在metadata中存着表的构建语句呢
DDL基础
- 目前只有MergeTree、Merge和Distribution三类表引擎支持ALTER查询,在进行alter操作时候注意表引擎是否支持
//只有MergeTree支持表结构的修改
//MergeTree引擎一定要指定主键和排序字段,order by 代表两个含义一是指定主键一是代表排序
create table test(
id Int8,
name String
)engine=MergerTree()
order by id;
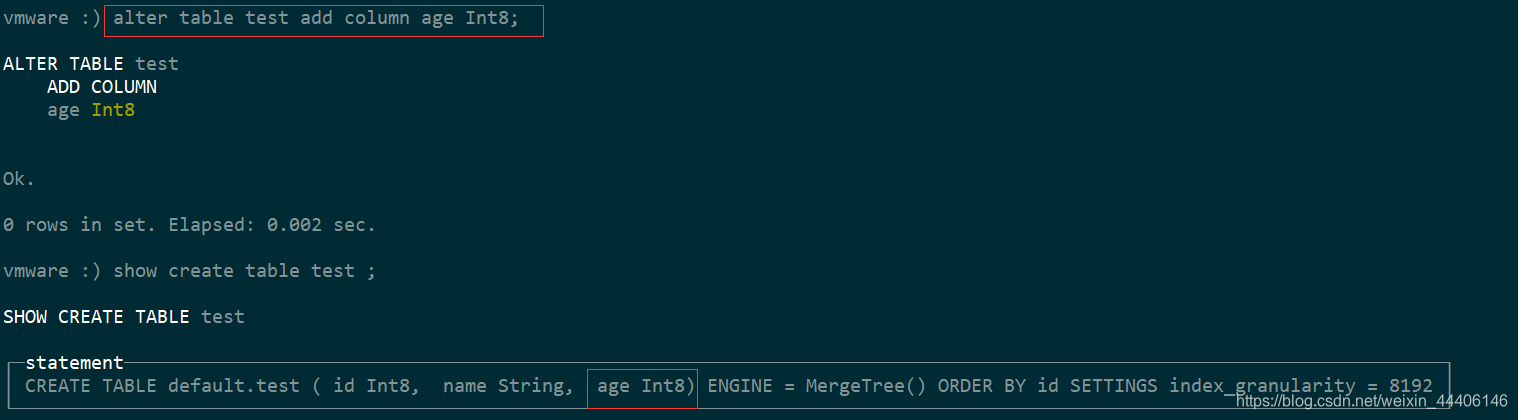
//增加新的字段
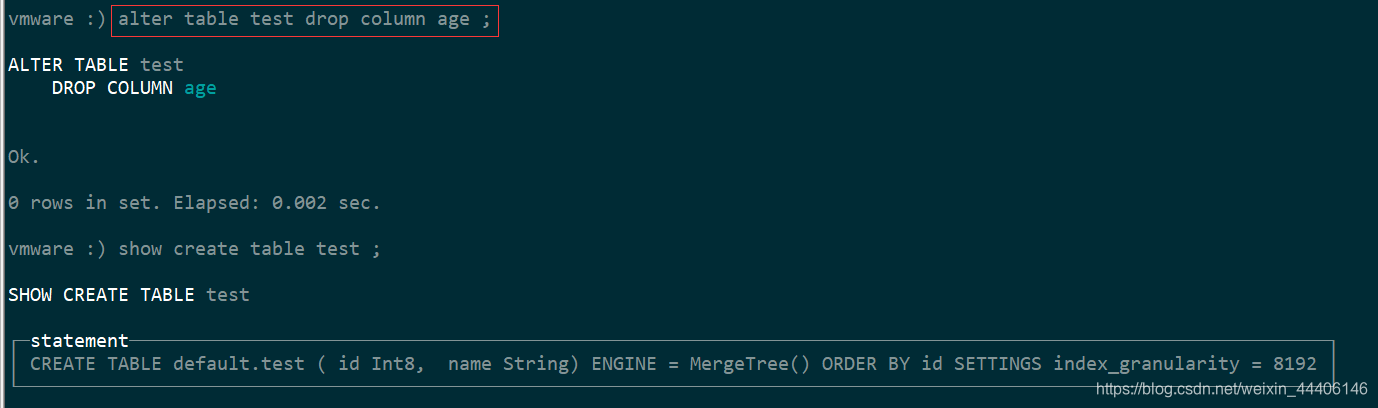
alter table test add column age Int8;
//删除字段
alter table test drop column age Int8;
//修改字段数据类型
alter table test modify column age Int16;
//修改添加字段注释
alter table test comment column age '用户年龄';
//desc test
┌─name─┬─type───┬─default_type─┬─default_expression─┬─comment_expression─┐
│ id │ Int8 │ │ │ │
│ name │ String │ │ │ │
│ age │ Int16 │ │ │ 用户年龄 │
└──────┴────────┴──────────────┴────────────────────┴────────────────────┘

2.移动表
- 想一下linux的mv命令,可以当移动目录使,也可以改名字
//修改表名
rename table test to retest
//修改多张表名
rename table retest to reretest,ee to test
//移动表到另一个数据库
rename table reretest to test1.t1
3.设置表的属性
//设置表的默认值
role String default 'VIP'
数据导入方式
1.insert的方式
//建一个表,log引擎是为了观察磁盘存储情况
create table tb_insert(id Int8,name String,age UInt8)engine=Log();
//插入两条数据
insert into tb_insert values(1,'a',18),(2,'b',29);
//到/var/lib/clickhouse/data下找对应库、表中的文件
//每次插入数据age.bin、id.bin、name.bin大小都会变化
//sizes.json记录了每个文件的大小
//另一种插入方式
insert into tb_insert select * from tb_insert2;
//另一种插入方式,user.txt记录了能看懂的tb_insert字段数据,以,分割如1,hh,18
cat user.txt | clickhouse-client -q 'insert into tb_insert format CSV'
clickhouse-client -q 'insert into tb_insert format CSV' < cat user.txt
//还可以指定数据行的分隔符
clickhouse-client --format_csv_delimeter=',' -q 'insert balabala'

- clickhouse内部的所有数据操作都是面向Block块的,insert查询最终会将数据转换为Block数据块,INSERT语句在单个数据块的写入过程是原子性的,默认情况下,每个数据块最多可以写入1048576行数据(max_insert_block_size控制),插入操作具有原子性,要么全部成功要么全部失败
2.更新删除数据
- Clickhouse提供了DELETE和UPDATE的能力,这类操作被称为Mutation查询,可以看作ALTER语句的变种,Mutation能最终实现删除和更新,但不能以传统的delete和update考虑
- Mutation操作很重,更适合批量操作
- 不支持事务,直接返回结果,异步操作,可以通过system.mutations查询进度
- 数据修改和删除操作使用MergeTree家族引擎
//条件删除数据
alter table tb_insert delete where id=1;
//条件更新
alter table tb_insert update id=8 where id=1;
分区表操作
- 目前只有MergeTree支持数据分区
- 区内合并、去重、排序
//建立一个表,按照城市分区
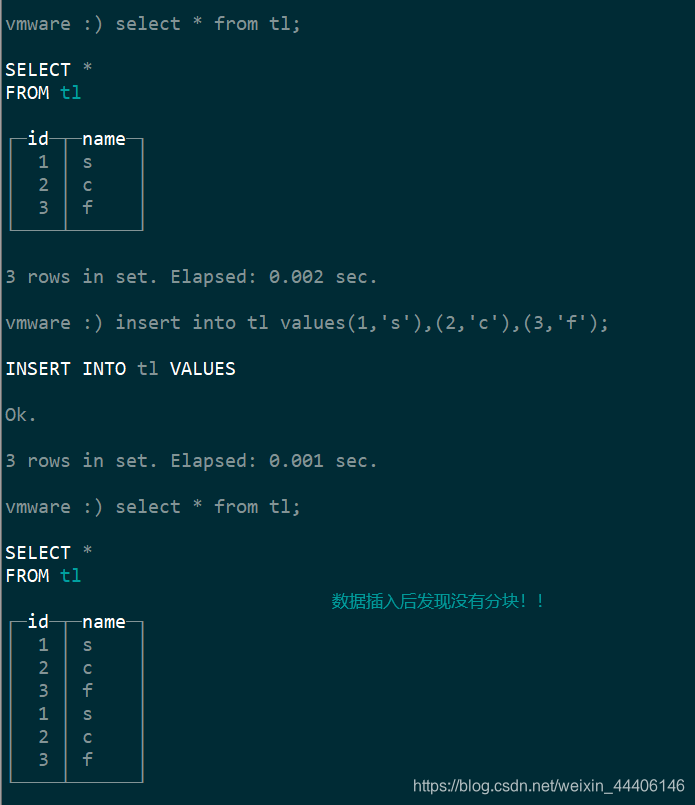
CREATE TABLE t1
(
id Int8,
city String
)
ENGINE = MergeTree()
PARTITION BY city
ORDER BY id
//插入一些数据
insert into t1 values(1,'a'),(2,'b'),(3,'a'),(4,'b'),(5,'c');
//查看数据
SELECT *
FROM t1
┌─id─┬─city─┐
│ 2 │ b │
│ 4 │ b │
└────┴──────┘
┌─id─┬─city─┐
│ 1 │ a │
│ 3 │ a │
└────┴──────┘
┌─id─┬─city─┐
│ 5 │ c │
└────┴──────┘
//再插入一条
insert into t1 values(6,'c');
//再次查看数据
SELECT *
FROM t1
┌─id─┬─city─┐
│ 2 │ b │
│ 4 │ b │
└────┴──────┘
┌─id─┬─city─┐
│ 1 │ a │
│ 3 │ a │
└────┴──────┘
┌─id─┬─city─┐
│ 5 │ c │
└────┴──────┘
┌─id─┬─city─┐
│ 6 │ c │
└────┴──────┘
//查看分区情况,name是指存储到磁盘中文件名称
SELECT
table,
name,
partition
FROM system.parts
WHERE table = 't1'
┌─table─┬─name───────────────────────────────────┬─partition─┐
│ t1 │ 0b8b7d0f4c971a62a5cc8daaa7f20082_3_3_0 │ c │
│ t1 │ 0b8b7d0f4c971a62a5cc8daaa7f20082_4_4_0 │ c │
│ t1 │ 51fbadfb0deeea70ceafbd3c7c8aef25_1_1_0 │ a │
│ t1 │ d1566a03c2469a412f2b88e3951f2701_2_2_0 │ b │
└───────┴────────────────────────────────────────┴───────────┘
//删除分区
alter table t1 drop partition 'a';
//再查
SELECT
table,
name,
partition
FROM system.parts
WHERE table = 't1'
┌─table─┬─name───────────────────────────────────┬─partition─┐
│ t1 │ 0b8b7d0f4c971a62a5cc8daaa7f20082_3_3_0 │ c │
│ t1 │ 0b8b7d0f4c971a62a5cc8daaa7f20082_4_4_0 │ c │
│ t1 │ d1566a03c2469a412f2b88e3951f2701_2_2_0 │ b │
└───────┴────────────────────────────────────────┴───────────┘
3 rows in set. Elapsed: 0.002 sec.
vmware :) select * from t1;
SELECT *
FROM t1
┌─id─┬─city─┐
│ 2 │ b │
│ 4 │ b │
└────┴──────┘
┌─id─┬─city─┐
│ 6 │ c │
└────┴──────┘
┌─id─┬─city─┐
│ 5 │ c │
└────┴──────┘
//合并分区
optimize table t1;
OPTIMIZE TABLE t1
Ok.
0 rows in set. Elapsed: 0.001 sec.
vmware :) select * from t1;
SELECT *
FROM t1
┌─id─┬─city─┐
│ 5 │ c │
│ 6 │ c │
└────┴──────┘
┌─id─┬─city─┐
│ 2 │ b │
│ 4 │ b │
└────┴──────┘
//复制表
create table t2 as t1;
vmware :) create table t2 as t1;
CREATE TABLE t2 AS t1
Ok.
0 rows in set. Elapsed: 0.002 sec.
vmware :) show create table t2;
SHOW CREATE TABLE t2
┌─statement─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.t2 ( id Int8, city String) ENGINE = MergeTree() PARTITION BY city ORDER BY id SETTINGS index_granularity = 8192 │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
//复制分区,支持将A表的分区数据复制到B表,用于数据快速写入
//使用前提是两个表使用相同的分区键,并且表结构相同
alter table t2 replace partition 'c' from t1 ;
vmware :) select * from t2;
SELECT *
FROM t2
┌─id─┬─city─┐
│ 5 │ c │
│ 6 │ c │
└────┴──────┘
//卸载分区
//表分区可以通过detach卸载,分区被卸载后,物理数据并不会被删除,而是被转移到detached目录下
vmware :) alter table t1 detach partition 'c';
ALTER TABLE t1
DETACH PARTITION 'c'
Ok.
0 rows in set. Elapsed: 0.001 sec.
vmware :) select * from t1;
SELECT *
FROM t1
┌─id─┬─city─┐
│ 2 │ b │
│ 4 │ b │
└────┴──────┘
2 rows in set. Elapsed: 0.002 sec.
//装载分区
alter table t1 attach partition 'c';
vmware :) alter table t1 attach partition 'c';
ALTER TABLE t1
ATTACH PARTITION 'c'
Ok.
0 rows in set. Elapsed: 0.001 sec.
vmware :) select * from t1;
SELECT *
FROM t1
┌─id─┬─city─┐
│ 2 │ b │
│ 4 │ b │
└────┴──────┘
┌─id─┬─city─┐
│ 5 │ c │
│ 6 │ c │
└────┴──────┘
4 rows in set. Elapsed: 0.002 sec.
//重置分区数据
alter table t2 clear column city in partition 'c';
视图
1.普通视图
ClickHouse拥有普通和物化两种视图,其中物化视图拥有独立的存储,普通视图只是一层简单的查询代理
//创建视图view
create view [if not exists] [db_name.]view_name as select ...
//删除视图
drop view xxx;
普通视图不会存储任何数据,它只是单纯的SELECT查询映射,简化查询、明晰语义的作用,对查询性能不会有任何增强。
2.物化视图
-
物化视图支持引擎,数据保存形式由它的表引擎决定,创建物化视图的完整语法如下所示
-
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ... -
物化视图创建好后,如果源表被写入新数据,物化视图也会同步更新。
-
POPULATE修饰符决定了物化视图的初始化策略,如果使用了此修饰符,那么物化视图在创建之后没有数据,只会同步之后源表中插入的数据,物化视图不支持同步删除,如果源表中的数据被删除了那么视图中的数据被保留。
//创建一个物化视图
vmware :) create materialized view myview engine=Memory as select id,city from tview;
CREATE MATERIALIZED VIEW myview
ENGINE = Memory AS
SELECT
id,
city
FROM tview
//删除源表中的数据,物化视图中的数据不会变化
alter table name drop partition 'xx';
alter table name delete where col='xx';
alter table name update col='x' where col='xx'...;
引擎
- 数据库引擎
- 表引擎
- 不同引擎具有不同的数据表特性,定义了数据如何存储以及如何加载
- 拥有合并树、外部存储、内存、文件、接口等6大类20多种存储引擎,合并树(MergeTree)最大适合大多数生产场景,因为MergeTree支持主键索引,数据分区,数据副本和数据采样,支持alter操作
- 主键索引、数据分区、数据副本是MergeTree家族的基本能力,其他同族引擎各有所长,ReplacingMerge具有删除重复数据的特性,SummingMergeTree能按照排序键自动聚合数据,如果合并树系列引擎加上Replicated前缀又可以得到一组支持数据副本的表引擎
表引擎决定了:
- 数据存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持
- 并发数据访问
- 索引的使用
- 是否可以执行多线程请求
- 是否可以存储数据副本
1.Log系列引擎
- Log家族具有最小功能,轻量级引擎,当需要快速写入许多小表(100万行)在以后整体读取它们时,该类型引擎时最有效的。
- StripLog
- Log
- TinyLog
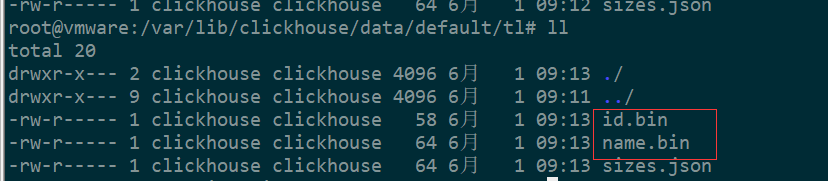
TinyLog
- 最简单的表引擎,将数据存储在磁盘上,每列都存储在单独的压缩文件中,写入时数据附加在文件末尾,没有并发控制
- 没有索引,没有标记块,追加写,数据以列字段文件储存,不允许同时读写
- 以列存储的意思是,每个列保存为一个文件
Log
- 相比于tinylog来说,《标记》的小文件与列文件存在一起,这些标记写在每个数据块上,并且包含偏移量,这些偏移量之时从哪里开始读取文件以便跳过指定的行数,这使得可以在多个线程中读取表数据。
- 对于并发数据访问,可以同时执行读取操作,写入操作阻塞读取和其他写入操作
- 不支持索引,如果写入表失败则表会被破坏(tinylog也一样)此时只能删除数据和元数据信息重启服务了

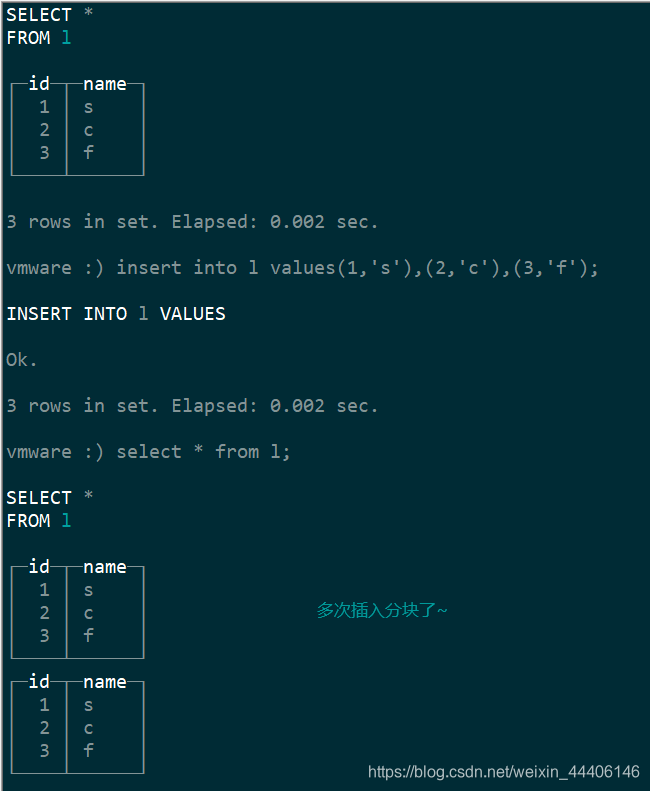
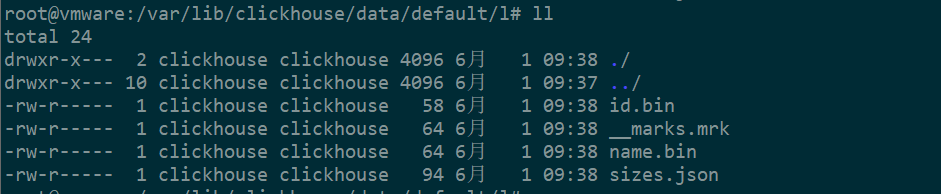
StripLog引擎
- data.bin存储所有数据
- index.mrk对所有数据建立索引
- size.json数据大小
- 并发读写
2.Merge引擎系列
- MergeTree引擎是clickhouse数据存储功能的核心,它们提供了用于弹性和高性能数据检索的大多数功能,列存储、自定义分区,稀疏的主索引,辅助数据跳过索引等
- 基本MergeTree表引擎可以被认为是单节点Clickhouse实例的默认表引擎,通用且实用
- 除了基础表引擎外常用的还有ReplacingMergeTree,SummingMergeTree,AggregatingMergeTree,CollapsingMergeTree和VersionCollapsingMergeTree。每一种合并树的变种在继承基础MergeTree能力之后又增加了独有的特性,名称中的合并二字奠定了所有类型MergeTree的基因,它们所有的特殊逻辑都是在触发合并的过程中激发的
主要特点:
- 存储按照主键排序的数据,以此可以建立一个小的稀疏索引,更快的查找数据
- 如果指定了分区键可以使用分区,clickhouse支持某些分区操作比相同的数据相同结果的常规操作更有效,clickhouse会自动切断查询中指定的分区键的分区数据,这也提高了查询性能
- 数据复制如replicatedmerge
- 如有必要可以在表中设置数据采样方法
MergeTree引擎
- MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘(当然分区不同,不同文件),数据片段不可以修改,为了避免片段过多,clickhouse会启动后台线程,定期合并片段,属于相同分区的数据片段会合成一个新的片段,这种数据片段合并的特点正是合并树的由来
- 建表语句
- 一定要有排序字段
- 设置的主键没有唯一要求,可以重复
//建个表
vmware :) create table mt(id Int8,name String,bir Date,city String,gender String)
engine=MergeTree primary key id order by(id,bir);
CREATE TABLE mt
(
id Int8,
name String,
bir Date,
city String,
gender String
)
ENGINE = MergeTree
PRIMARY KEY id
ORDER BY (id, bir)
Ok.
ReplacingMergeTree
- 这个引擎在MergeTree基础上,添加了处理重复数据的功能,引擎和MergeTree的不同之处在于它会删除具有相同(区内)排序一样的的重复数据,数据的去重只会发生在合并期间,合并在未知的时间后台运行无法预知,可能有些数据仍未被处理
- 此引擎可以清除重复数据,但是不保证没有重复数据出现
- optimize确实可以用,但是涉及大量读写操作,慎用!(optimize table xx final)
- 参考
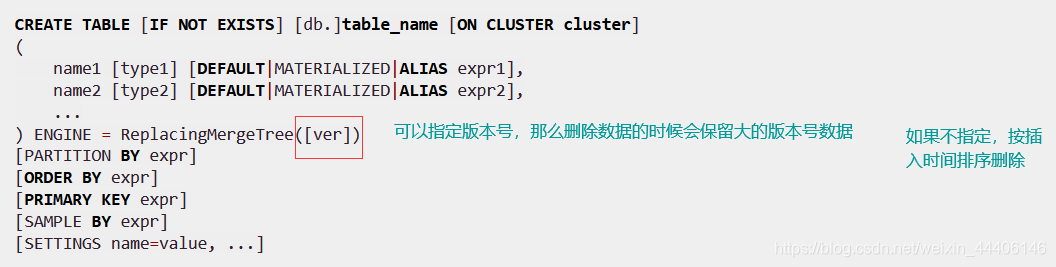
- 使用order by 指定的排序键作为判断重复的唯一标准
- 只有在合并分区的时候才会触发删除重复数据的逻辑
- 数据分区为单位删除重复数据,同一分区内的数据才会被删除
- 去重时由于已经按照order by排序了所以很好找到重复的数据
- 去重时如果指定了版本号,则取版本号最大的那个,如果没有指定保留最新插入的那个
CollapsingMergeTree
- CollapsingMergeTree以增代删的思路,支持行级数据的修改和删除操作。通过定义一个sign标记位字段,记录数据行的状态,如果sign标记为1,则表示这行数据有效,如果sign标记为-1,表示这行数据需要被删除
- 当collapsingMergeTree分区合并时,同一数据分区内sign标记为1和-1的一组数据会被抵消删除,这种抵消解释了引擎名称。
- 但是当出现sign的取值分别为 -1、1的数据行时这两行数据不会被删除,只有1,-1才能被删除
- 排序相同,sign相同的4行数据会合并成一行
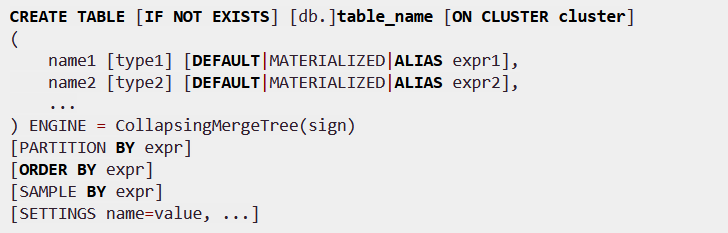
VersionedCollapsingMergeTree
- 为了解决CollapsingMergeTree乱序插入无法折叠数据的问题
- 新增version列,主键相同,version相同,sign相反就会折叠删除
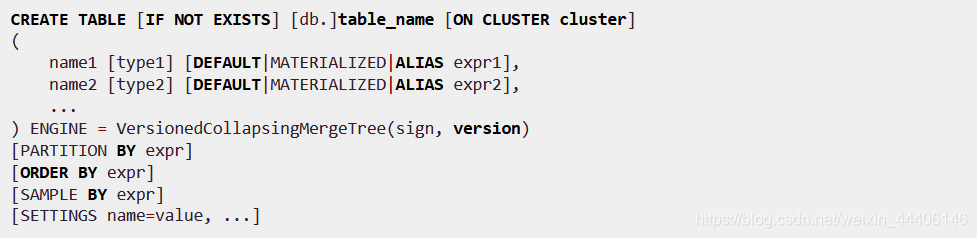
SummingMergeTree
- 假设有这样一种查询需求:终端用户只需要查询数据的汇总结果,不关心详细数据,且汇总条件预先明确(Group by的条件明确,不会随意改变)
- 使用mergeTree查询数据,通过group by聚合查询,利用sum聚合函数汇总结果但是存在两个问题,一是额外的存储开销,用户并不查询任何明细数据,只关系汇总结果不应该一直保存所有数据。二是聚合函数的计算开销
- SummingMergeTree可以解决这个问题,它能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总合并成一行,这样即减少数据行又降低汇总查询的开销。
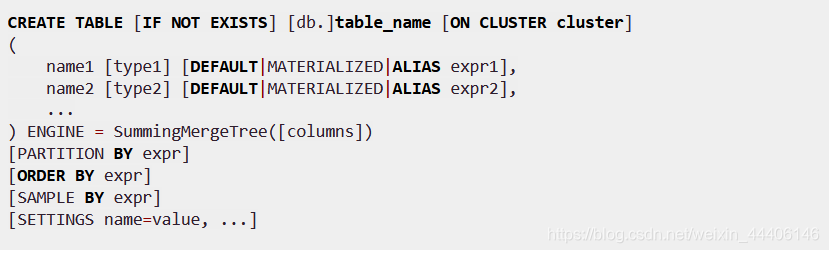
- 如果没有指定要合并的字段,会默认把能合并的几行中对应的列都相加
- order by 指定的字段可以用于识别是否可以合并
- 只有合并分区的时候才会触发汇总逻辑
- 同分区的才能合并
- 汇总数据时,同一分区内相同聚合key的多行数据被被合并到一行,汇总字段按照sum取值,而其他字段默认取第一行
- 支持嵌套结构,列字段名称必须以Map后缀结尾,嵌套类型中,默认以第一个字段作为聚合key,除第一个字段外任何名称以key,id或者type为后缀结尾的字段,都将和第一个字段一起组成复合key。
AggregatingMergeTree
- 能够在合并分区的时候按照预先定义的条件聚合数据,根据预先定义的聚合函数计算数据并通过二进制的格式存入表内
- 即减少了数据行,又减少了后续计算开销
- 是SummingMergeTree的升级版
- 语法优点特殊
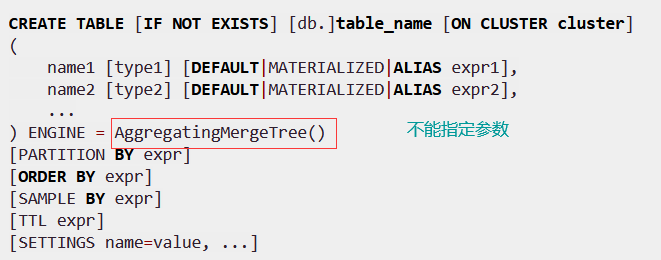
- 分区合并时,每个数据分区内按照order by聚合,使用何种聚合函数,以及针对哪些字段计算,则是通过AggregateFunction数据类型实现的,在insert和select时,有独特的写法和要求,写入时需要使用-State语法,查询时需要使用-Merge语法
- AggregateFunction(arg1,arg2),参数一指定聚合函数,参数二指定数据类型,比如sumcol AggregateFunction(sum,Int64)
- 先创建原始表—插入数据—创建预先聚合表—通过insert的方式导入数据,数据会按照指定的聚合函数聚合预先数据
//建立明细表
create table dt(
id UInt8,
ctime Date,
money UInt64
)engine=MergeTree()
partition by toDate(ctime)
order by id;
//插入数据
insert into dt values(1,'2021-08-06',100);
insert into dt values(1,'2021-08-06',100);
insert into dt values(2,'2021-08-07',200);
insert into dt values(2,'2021-08-07',200);
//预先建立聚合表
create table aft(
id UInt8,
ctime Date,
money AggregateFunction(sum,UInt64)
)engine=AggregatingMergeTree()
partition by toDate(ctime)
order by id;
//给聚合表插入数据
insert into aft select id,ctime,sumState(money) from dt group by id,ctime;
//查询数据也有特殊要求
select id,ctime,sumMerge(money) as money from aft group by id,ctime;
//直接查select * from aft 会显示不了money的值
//不能直接使用普通的insert语句向聚合表中插入数据
//这样搞有个不好的地方,假如明细表新增数据,聚合表不会同步数据
//使用物化视图可以解决这个问题
外部存储引擎
- ClickHouse 提供了多种与外部系统集成的方法,包括表引擎。 与所有其他表引擎一样,配置是使用 CREATE TABLE或者 ALTER TABLE查询。 然后从用户的角度来看,配置的集成看起来像一个普通的表,但对它的查询被代理到外部系统。 这种透明查询是这种方法相对于其他集成方法(如外部字典或表函数)的主要优势之一,后者需要在每次使用时使用自定义查询方法。

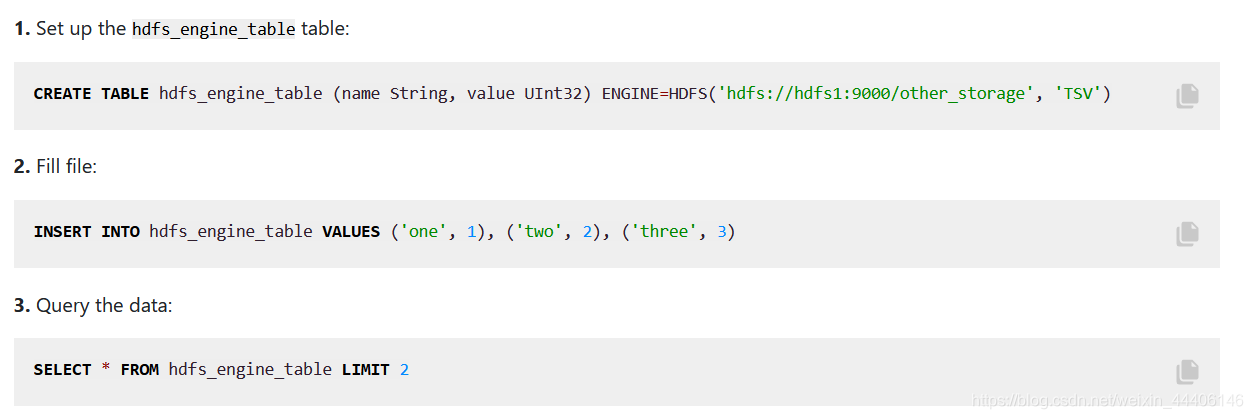
1.HDFS引擎
-
Clickhouse可以直接从HDFS指定的目录下加载数据,自己不存储数据,仅仅读取数据
-
我们期望的是数据有其他方式写入HDFS系统中,使用CK的HDFS引擎加载处理分析数据而已
-
指定引擎时的格式为ENGINE = HDFS(URI, format)
-
路径可以设置通配符,可以看官网
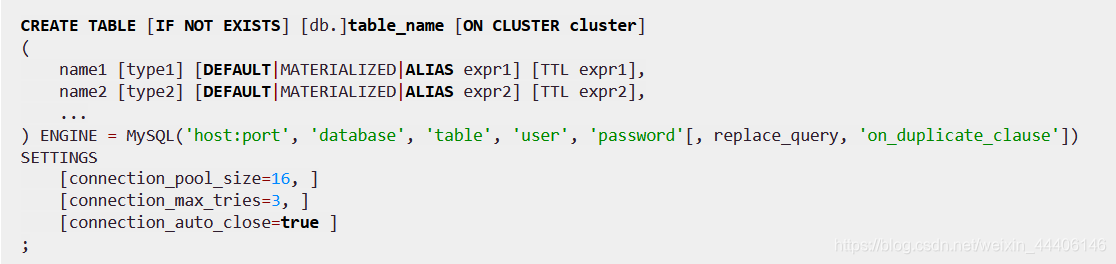
2.MySQL表引擎
3.MySQL数据库引擎
- 可以select和insert
- 常用于数据的合并

4.File引擎 - File引擎能够直接读取本地文件的数据,通常被作为一种扩充手段来使用
- 读取其他系统生成的数据文件,如果外部系统直接修改了文件,变相达到了数据更新的目的
- 使用engine=File(format)指定引擎
- 类似:表函数file
内存引擎
- 面向内存查询,数据会从内存中直接被访问
- 也有内存引擎可以将数据写入磁盘,这防止了数据丢失
- 数据表被加载时,它们会将数据全部加载至内存,以供查询使用,这样查询性能好,但是如果数据量过大,内存就崩了
1.Memory
- 内存引擎以未压缩的形式将数据存储在 RAM 中。 数据以与读取时接收到的完全相同的形式存储。
- Concurrent data access is synchronized. Locks are short: read and write operations do not block each other.
Indexes are not supported. Reading is parallelized. - 应用场景主要时测试,学习,clickhouse内部作为集群间分发数据的存储载体使用,利用分布式IN查询场合中,利用Memory临时表保存IN子句的查询结果,通过网络将它传输到远端节点
2.Set
-
Set表引擎拥有物理存储,数据首先写入内存,然后被同步到磁盘文件中,服务重启时数据不会丢失,数据表加载时数据会重新全量加载至内存
-
Set表引擎具有去重的能力,数据写入时重复的元素会自动忽略
-
可以使用insert语句插入,但是不能直接使用select进行查询,Set表引擎只能间接作为IN查询的右侧条件被查询使用

-
数据的文件保存有两个一个时num.bin,其中num是一个自增的id,每一批数据写入时都会生成一个新的bin文件,num自增

-
tmp是一个临时文件,数据文件首先会写入这个目录,当一批数据写入完毕后,数据文件会被移出这个目录
-
查询时select * from xx where (id,name) in tset;
3.Buffer
- Buffer表引擎完全使用内存装载数据,不支持文件的持久化存储
- 充当缓冲角色,考虑将数据写入MergeTree表中,写入并发数很高,分区合并速度慢,此时可以引入Buffer表做缓冲
- 缓冲要写入 RAM 的数据,定期将其刷新到另一个表。 在读操作期间,数据同时从缓冲区和其他表中读取。

- database:目标表的数据库‘
- table:目标表的名称
- num_layers:可以理解为线程数,Buffer表会按照num_layers数量开启线程,以并行的方式将数据刷新到目标表,官方建议为16
Buffer表并不是实时刷新数据,满足一定阈值才会刷新
- min_time和max_time:时间条件的最小值和最大值,单位为s,从第一次向表内写入数据的时候开始计算
- min_rows和max_rows:数据行条件的最小和最大值
- min_bytes和max_bytes:数据体量条件的最小值和最大值单位字节
Buffer表刷新的判断有三个,满足任意一个就会刷新数据
- 所有最小阈值都被满足
- 至少有一个最大阈值都满足
- 如果写入的一批数据数据行大于max_rows,或者体量大于max_bytes数据直接被写入目标表
上述三组条件的每个num_layers都是单独计算的,假设该值为16,那么Buffer表最多开启16个线程来响应数据写入,以轮询的方式接收请求,每个线程内独立进行上述判断,如果max_bytes=100MB(假设),那么Buffer表能够同时处理的最大数据量约为1.6GB。
查询语法
1.with
- clickhouse支持CTE(Common table expression 公共表达式)增强查询语句表达
with pow(2,2) as res select pow(res,2); // 4的平方
with 1 as num select num+1; //1+1
// with CUBE,就是相当于写了2的三次方个sql语句
select sum(visit)
from tw
group by p,c,a
with CUBE;
//with ROLLUP
//啥也没有的,group by p的,pc的,pca的
//with Totals
//除了group by pca的 多了一个汇总的
2.from
- 表中查询
- 子查询中查询
- 表函数查询 select * from numbers(3);
3.array join
- ARRAY JOIN子句允许在数据库表的内部,与数据或者嵌套类型的字段进行JOIN操作,从而将一行数组展开为多行
// 建立一个表
vmware :) create table ta(name String,vs Array(Int8))engine=Memory;
CREATE TABLE ta
(
name String,
vs Array(Int8)
)
ENGINE = Memory
Ok.
0 rows in set. Elapsed: 0.002 sec.
//插入数据
vmware :) insert into ta values('a',[1,2,3]),('b',[4,5]),('c',[6]);
INSERT INTO ta VALUES
Ok.
3 rows in set. Elapsed: 0.001 sec.
// 查询一下
vmware :) select *,s from ta array join vs as s;
SELECT
*,
s
FROM ta
ARRAY JOIN vs AS s
┌─name─┬─vs──────┬─s─┐
│ a │ [1,2,3] │ 1 │
│ a │ [1,2,3] │ 2 │
│ a │ [1,2,3] │ 3 │
│ b │ [4,5] │ 4 │
│ b │ [4,5] │ 5 │
│ c │ [6] │ 6 │
└──────┴─────────┴───┘
6 rows in set. Elapsed: 0.002 sec.
4.连接查询
- clickhouse支持连接查询
- left/right/full/outer/inner/cross join
- 设置连接精度all/any/asof
连接精度
- 连接精度决定了join查询在连接数据时所使用的策略,目前支持all,any,asof三种类型,如果不主动声明默认就是all,可以通过join_default_strictness配置参数修改默认的连接精度类型
- 对数据是否连接匹配的判断是通过join key进行的,目前支持等式(equal join),交叉连接(cross join)不需要使用join key,因为会产生笛卡尔积?
- all就是正常的关联,any是只关联一条就可以了,asof支持一些不等值的连接
函数
- clickhouse提供两类函数,普通函数和聚合函数,普通函数有Function接口定义,拥有数十种函数实现,例如FunctionFormatDateTime,FunctionSubstring等,除了一些常见的函数(四则运算、函数转换)外,也有实用函数,比如网页特征提取函数,IP地址脱敏
- 普通函数没有状态,函数效果作用于每行数据之上,函数具体计算的时候采用向量化的方式直接作用于一整列数据。
- 聚合函数由IAggregateFunction接口定义,相比无状态的普通函数而言,聚合函数有状态,count聚合函数为例,其AggregateFunctionCount的状态使用整UInt64记录,聚合函数的状态支持序列化和反序列化,能够在分布式节点之间传输,以实现增量计算
- 有点多啊,看官网把。。

















 2557
2557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









