




在分布式集群中,对机器的添加删除,或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能。如果采用常用的服务器IP = hash(object)%服务器数量(N为可以处理请求的主机个数)算法,那么在有机器添加或者删除后,很多原有的数据就无法找到了,这样严重的违反了单调性原则。
设计的目标是:在服务器数量变动的情况下(1)尽量提高缓存的命中率(2)缓存数量尽量平均分配。
为了解决服务器数量变化带来的大量对象存储位置失效,可以采用一致性Hash算法。
一致性Hash算法
一致性哈希解决的本质问题是:相同的key通过相同的哈希函数,能正确路由到相同的目标。像我们平时用的数据库分表策略,分库策略,负载均衡,数据分片等都可以用一致性哈希来解决。
一致性Hash算法过程
(1)首先求出服务器(节点)的哈希值,并将其配置到环上,此环有2^32个节点。
(2)采用同样的方法求出存储数据的键的哈希值,并映射到相同的环上。 即将服务器节点和数据键都映射到具有2^32个节点的环形的环上
(3)然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2^32仍然找不到服务器,就会保存到第一台服务器上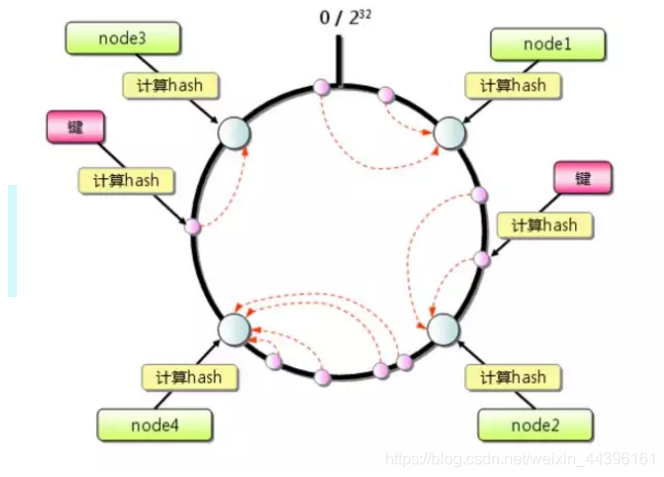
当环上的服务器节点出现新增或者删除时:收到影响的key(即这部分key分配给了其他节点处理,即缓存失效)只是很少一部分:
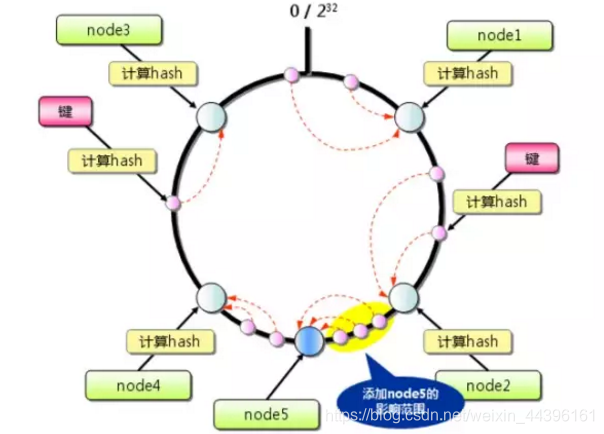
虚拟节点
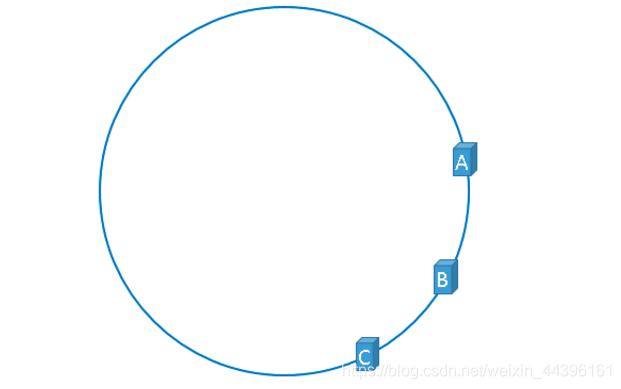
当服务器节点在环上的分布不均匀时,这样会造成某些服务器会负责大量的key,而一些服务器节点负责很小部分的key,就出现了哈希环倾斜。如下图就发生了哈希环倾斜。
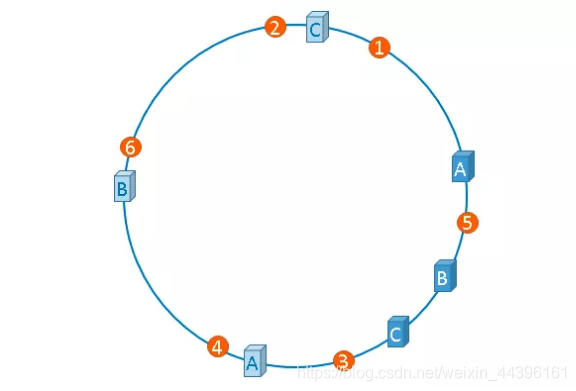
一次为了尽可能满足平衡性,引入了虚拟节点。虚拟节点是实际节点在 hash 空间的复制品,一实际个节点(机器)对应了若干个“虚拟节点”,“虚拟节点”在 hash 空间中以hash值排列。虚拟节点的Hash计算可以采用对应节点的IP地址+数字后缀的方式,比如一个实际节点A的IP为192.168.1.100,引入虚拟节点前,计算该节点的Hash值:Hash(192.168.1.100),引入虚拟节点后,计算虚拟节点A-1和A-2的值为:
Hash(“192.168.1.100#1”)
Hash(“192.168.1.100#2”)。
引入虚拟节点后:
链接: 参考.
链接: 参考.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









