







——————————————————————————
转载请注明出处:https://blog.youkuaiyun.com/weixin_44390691/article/details/105177911
——————————————————————————
一.《IMRAM:Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval》
这是一篇2020年新鲜出炉的CVPR文章,后面简称IMRAM,趁着还热乎赶紧来欣赏一下。
首先贴一下IMRAM在MSCOCO数据集上的表现:
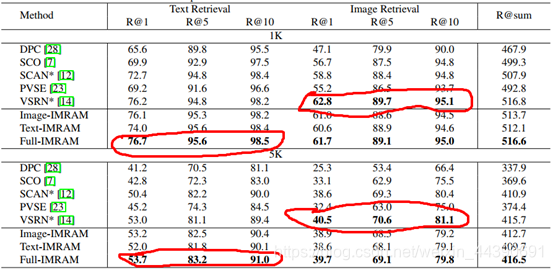
这是在COCO数据集上的结果,总体来看IMRAM和VSRN这两种方法表现最佳,其中在text retrieval上IMRAM更优,而image retrieval上VSRN更好。
我重点说一下我对IMRAM方法的理解。这个方法总体上分为三步:1)分别提取图像和文本的原始特征;2)用RAM模块探索二者之间细粒度上的对齐关系;3)相似性度量以及损失函数迭代优化。
1.得到跨模态特征表示
对于图像:用一个经过预训练的CNN网络来提取特征。给一张图像I,CNN识别出几个包含语义信息的区域r,并提取出每一个区域对应的特征
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









