




 本文介绍了LRU-K和2Q两种缓存算法。LRU-K通过维护访问历史列表,当数据访问次数达到K次时将其放入缓存,避免了LRU的缓存污染问题,LRU-2通常是最优选择。而2Q算法采用FIFO和LRU双队列,首次访问数据存入FIFO,二次访问后移至LRU,提升了缓存效率。
本文介绍了LRU-K和2Q两种缓存算法。LRU-K通过维护访问历史列表,当数据访问次数达到K次时将其放入缓存,避免了LRU的缓存污染问题,LRU-2通常是最优选择。而2Q算法采用FIFO和LRU双队列,首次访问数据存入FIFO,二次访问后移至LRU,提升了缓存效率。
一、LRU-K算法
1、算法思想
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
2、工作原理
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下
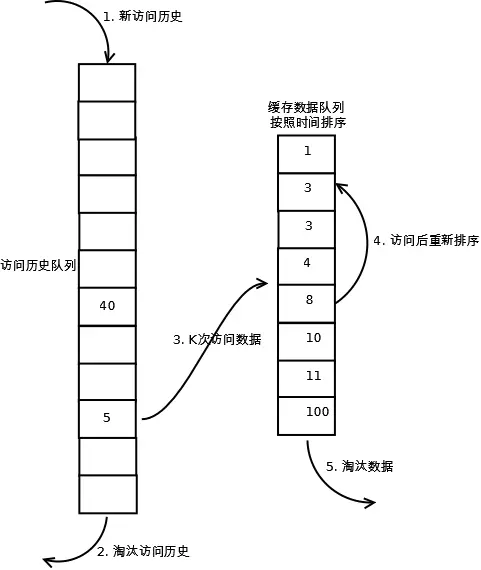
472792-20161120232440279-600049881.png
(1). 数据第一次被访问,加入到访问历史列表;
(2). 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
(3). 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
(4). 缓存数据队列中被再次访问后,重新排序;
(5). 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









