







https://www.usenix.org/conference/atc20/presentation/zhao
场景:对Docker registry进行重复数据删除
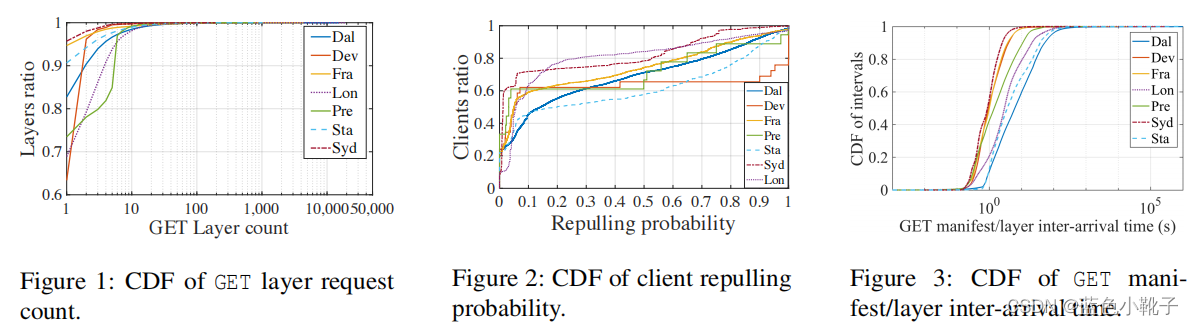
观察发现:1.容器镜像拥有大量冗余,而现有的重复数据删除技术不适用于Docker registry,会导致极高的layer恢复时间开销。
2.大多数layer只会被同一用户获取一次;许多用户只pull一个layer一次;用户对于layer一般要么只pull一次,要么总是repull,所以可以根据一个用户的pull历史来预测他要pull哪些layer。
3.Docker客户机从registry中提取镜像时,首先检索镜像manifest,其中包括对镜像layer的引用。GET manifest 和GET layer 请求之间往往存在秒级的间隔。在此间隔内预测用户需要哪些layer并对layer进行预构造能显著地降低layer恢复的时间开销。
DupHunter的架构如图所示: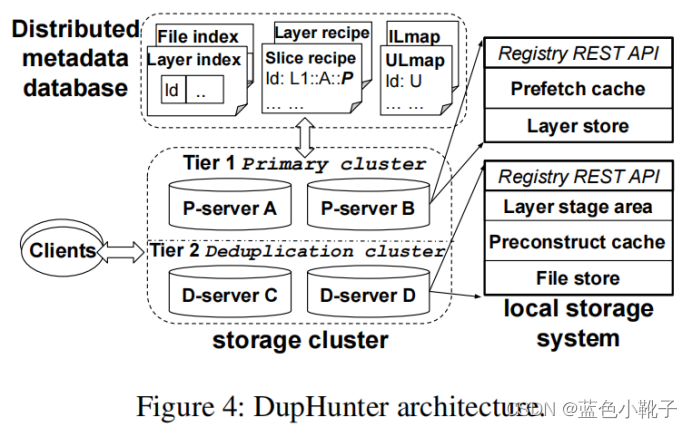
DupHunter主要由两部分组成:一个分布式元数据数据库和一个存储服务器集群。
在上传或下载layer时,Docker客户端可以使用registry API与任何DupHunter服务器进行通信。集群中的每个服务器都包含一个API服务和一个后端存储系统。 后端存储系统存储layer并执行重复数据删除,最后将重复数据删除元数据保存在数据库中。
服务器集群中又分为由P-server组成的原始集群服务器(Primary cluster)和由D-sever组成的重删集群服务器(Deduplication cluster)。P-sever负责存储无需进行重复数据删除的完整layer压缩文件副本和manifest副本;D-sever负责对layer压缩文件进行重复数据删除并存储和复制unique文件。
每个D-server的本地存储分为三个部分:layer stage区域、预构建缓存和文件存储。layer stage区域会临时存储新添加的layer完整副本。在对副本进行重复数据删除后,生成的unique文件存储在内容可寻址的文件存储中,并复制到对等服务器以提供冗余。存储了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









