







 本文介绍了一种使用dida365.com进行个人时间管理的方法,通过记录和分析时间事件,了解时间分配,提升个人效率。从数据读取、清洗到解析,最后进行数据分析,包括时间总览、精力分配、专注力及连续时间的精力分配。
本文介绍了一种使用dida365.com进行个人时间管理的方法,通过记录和分析时间事件,了解时间分配,提升个人效率。从数据读取、清洗到解析,最后进行数据分析,包括时间总览、精力分配、专注力及连续时间的精力分配。
时间事件日志
个人时间统计工具。要点:
- 使用 dida365.com 来作为 GTD 工具
- 使用特殊格式记录事件类别和花费的时间,如: “[探索发现] 体验 iMac 开发环境 [3h]”
- 导出数据
- 分析数据
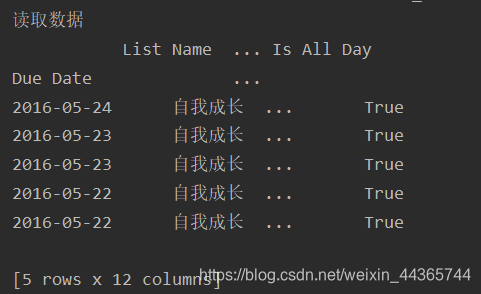
读取数据
分析并读取数据
import subprocess
import pandas as pd
## 时间事件日志
### 读取数据
from matplotlib.font_manager import FontManager
print('读取数据')
def get_support_chinese_font():
fm = FontManager()
mat_fonts = set(f.name for f in fm.ttflist)
output = subprocess.check_output('fc-list :lang=zh -f "%{family}\n"', shell=True)
print
'*' * 10, '系统可用的中文字体', '*' * 10
print
output
zh_fonts = set(f.split(',', 1)[0] for f in output.split('\n'))
available = mat_fonts & zh_fonts
print
'*' * 10, '可用的中文字体', '*' * 10
for f in available:
print
f
return available
from matplotlib.pylab import mpl
mpl.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
def _date_parser(dstr):
return pd.Timestamp(dstr).date()
data = pd.read_csv('data/dida365.csv', header=3, index_col='Due Date', parse_dates=True, date_parser=_date_parser)
print(data.head())
数据清洗
- 只关心己完成或己达成的事件,即
status != 0的事件 - 只需要
List Name和Title字段
### 数据清洗
print(' 数据清洗')
df = data[data['Status'] != 0].loc[:, ['List Name', 'Title']]
print(df.head())

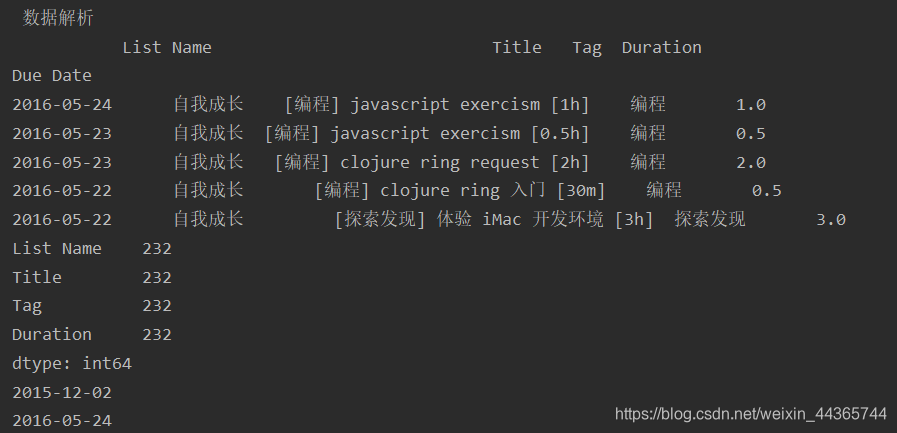
数据解析
解析事件类别和和花费的时间
### 数据解析
import re
print(' 数据解析')
def parse_tag(value):
m = re.match(r'^(\[(.*?)\])?.*$', value)
if m and m.group(2):
return m.group(2)
else:
return '其他'
def parse_duration(value):
m = re.match(r'^.+?\[(.*?)([hm]?)\]$', value)
if m:
dur = 0
try:
dur = float(m.group(1))
except e:
print('parse duration error: \n%s' % e)
if m.group(2) == 'm':
dur = dur / 60.0
return dur
else:
return 0
titles = df['Title']
df['Tag'] = titles.map(parse_tag)
df['Duration'] = titles.map(parse_duration)
print(df.head())
print(df.count())
start_date = df.index.min().date()
print(start_date)
end_date = df.index.max().date()
print(end_date)
数据分析
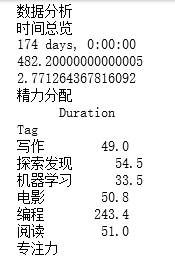
时间总览
平均每天投资在自己身上的时间是多少?-> *全部时间 / 总天数 *
精力分配
专注力
长时间学习某项技能的能力
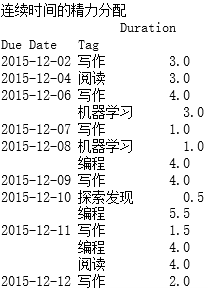
连续时间的精力分配
以时间为横轴,查看精力分配。
### 数据分析
#### 时间总览
print('数据分析')
print('时间总览')
print(end_date - start_date)
print(df['Duration'].sum())
print(df['Duration'].sum() / (end_date - start_date).days)
#### 精力分配
print('精力分配')
tag_list = df.groupby(['Tag']).sum()
print(tag_list)
tag_list['Duration'].plot(kind='pie', figsize=(8, 8), fontsize=16, autopct='%1.2f%%')
#### 专注力
print('专注力')
programming = df[df['Tag'] == '编程']
print(programming.head())
sumsum=programming.resample('m').sum().to_period(freq='m').plot(kind='bar', figsize=(8, 8), fontsize=16)
print(sumsum)
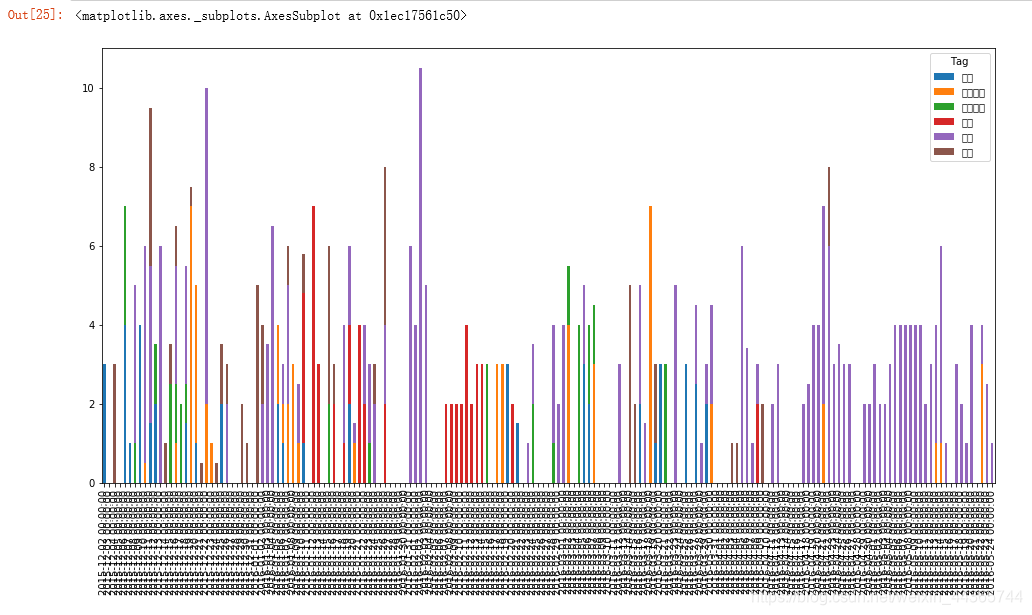
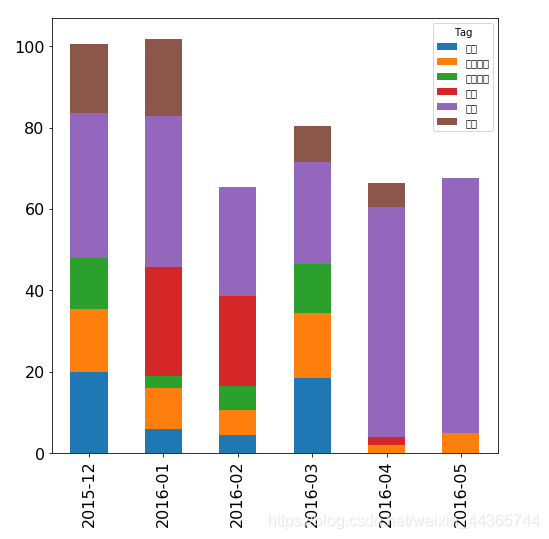
#### 连续时间的精力分配
print('连续时间的精力分配')
# 为什么不直接使用 df.pivot()? 因为有重复的行索引,如 2016-05-23
date_tags = df.reset_index().groupby(['Due Date', 'Tag']).sum()
print(date_tags)
# 以 tag 作为列索引
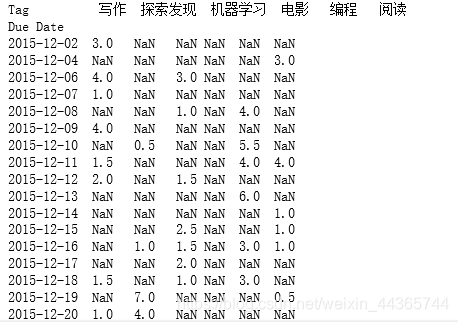
dates = date_tags.reset_index().pivot(index='Due Date', columns='Tag', values='Duration')
print(dates)
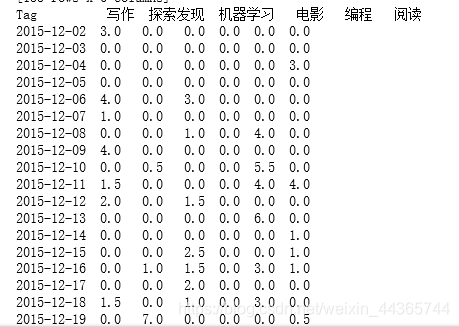
# 补足连续时间,可以看到哪些天没有在学习
full_dates = dates.reindex(pd.date_range(start_date, end_date)).fillna(0)
print(full_dates)
# 画出柱状图
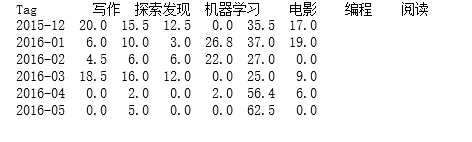
full_dates.plot(kind='bar', stacked=True, figsize=(16, 8))
sumsum=full_dates.resample('m').sum().to_period('m')
#umsum.plot(kind='bar', stacked=True, figsize=(8, 8))='bar', figsize=(8, 8), fontsize=16)
print(sumsum)


















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









