







ROC曲线:
纵轴为 recall = TP/(TP+FN), 即正例中有 多少被检测出来了。
横坐标为 假正例率,即误检率= FP/(TN + FP)
其实和pr曲线类似,都可以判断模型的准确性,即误检率低的时候,模型能不能尽可能多的挑出正例
无论误检率多低, recall始终为1,为理想情况
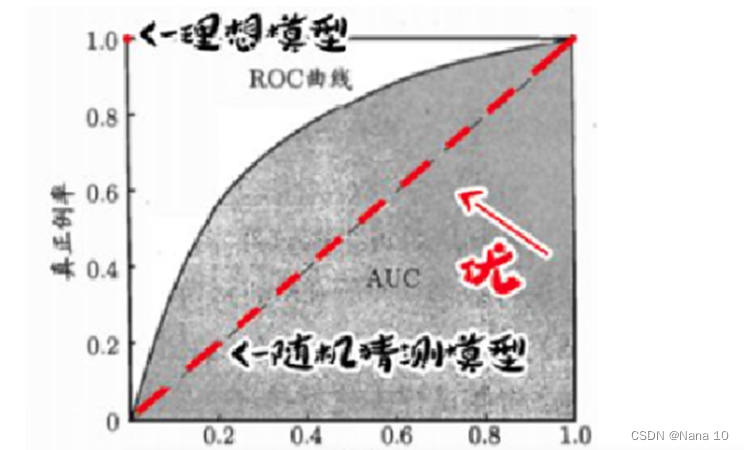
曲线越接近(0, 1)越好
AUC:
Area under curve,
AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值(置信度)将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
曲线下的面积,越接近1越好
计算方法:
卡两个指标:置信度阈值和iou,有下列几种情况:
①低于 置信度 或 iou 阈值 的视为负例。
②高于置信度阈值, 且 高于iou阈值的视为正例,
模拟假正率升高的过程:
将卡iou后的输出结果按照置信度从高到低排序,置信度由高到低截取
def plot(tf_confidence, num_groundtruthbox):
"""
从上到下截取tf_confidence,计算并画图
:param tf_confidence : np.array,
列1:按照iou计算后的true or false, 取值1,0;
列2:置信度,
按照置信度从高到低排序
:param num_groundtruthbox : int, 标注框的总数
"""
fp_list=[]
recall_list=[]
precision_list=[]
auc=0
"""
tf_confidence是按照置信度从高到低排序的,不断向后截取,相当于在降低置信度阈值,提高recall和 假正例率
"""
for num in range(len(tf_confidence)):
arr=tf_confidence[:(num+1),0]#截取
tp=np.sum(arr)
fp=np.sum(arr==0)
recall=tp/num_groundtruthbox
precision=tp/(tp+fp)
auc=auc+recall
fp_list.append(fp)
recall_list.append(recall)
precision_list.append(precision)
auc=auc/len(fp_list)
plt.figure()
plt.title('ROC')
plt.xlabel("FalsePositives")
plt.ylabel("TruePositiverate")
plt.ylim(0,1)
plt.plot(fp_list, recall_list)
plt.legend()
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









