







(1)215数组中的第k个最大元素–中等
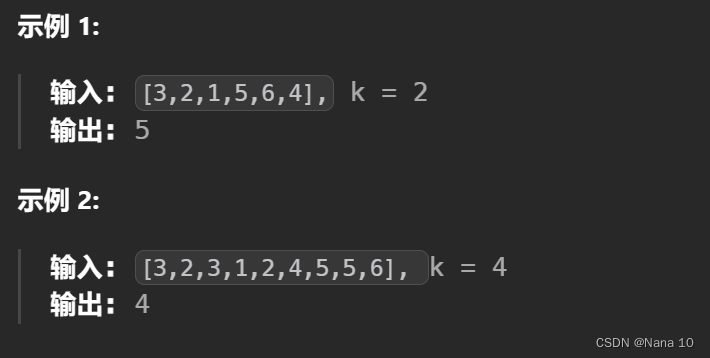
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
//维护一个长度为k的堆,堆顶元素即为第k大的数
// priority_queue<int> //默认降序队列,大顶堆
// priority_queue<int,vector<int>,less<int>> //降序队列,大顶堆
// priority_queue<int,vector<int>,greater<int>> //升序队列,小顶堆
priority_queue<int, vector<int>, greater<int>> Q;
for(int i = 0; i< nums.size(); i++){
//前k个直接进入堆
if(i<k) Q.push(nums[i]);
//k+1个开始,维护最大的k个在堆中
else if(nums[i] > Q.top()) {
Q.pop();
Q.push(nums[i]);
}
}return Q.top();
}
};

(2)295数据流的中位数–困难
中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
例如 arr = [2,3,4] 的中位数是 3 。
例如 arr = [2,3] 的中位数是 (2 + 3) / 2 = 2.5 。
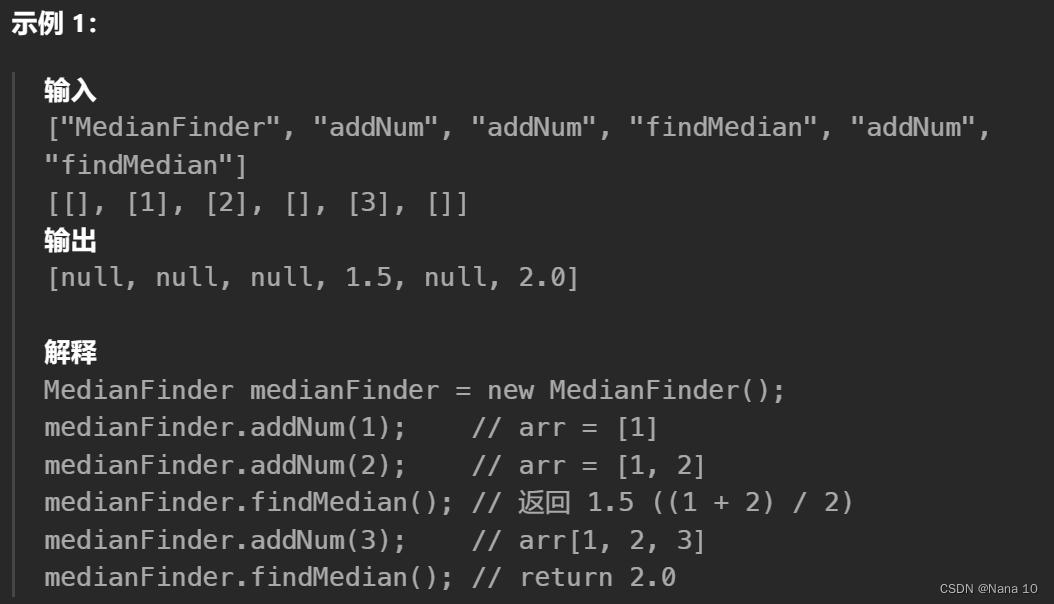
实现 MedianFinder 类:
MedianFinder() 初始化 MedianFinder 对象。
void addNum(int num) 将数据流中的整数 num 添加到数据结构中。
double findMedian() 返回到目前为止所有元素的中位数。与实际答案相差 10-5 以内的答案将被接受。
class MedianFinder {
private:
//维护两个堆
//最大堆,较小的一半元素,堆顶为较大元素中的最小值
priority_queue<int, vector<int>, less<int>> big_queue;
//最小堆,放较大的一半元素,堆顶为较小元素中的最大值
priority_queue<int, vector<int>, greater<int>> small_queue;
public:
MedianFinder() {
}
void addNum(int num) {
//如果两堆数量相等,选择相应的放即可
if(big_queue.size() == small_queue.size()){
if(big_queue.size() == 0) big_queue.push(num);
else if(num <= big_queue.top()) big_queue.push(num);
else small_queue.push(num);
}
//如果最大堆较多
else if(big_queue.size()> small_queue.size()){
//新元素属于较小的一半,需要插入最大堆
if(num < big_queue.top()){
//将最大堆堆顶移到最小堆中来
small_queue.push(big_queue.top());
big_queue.pop();
//最大堆push进新元素
big_queue.push(num);
}
//新元素属于较大的一半,需要插入最小堆
else small_queue.push(num);
}
//如果最小堆较多
else{
//新元素属于较大的一半,需要插入最小堆
if(num > small_queue.top()){
//将最小堆堆顶移到最大堆中来
big_queue.push(small_queue.top());
small_queue.pop();
//最小堆push进新元素
small_queue.push(num);
}
//新元素属于较小的一半,需要插入最大堆
else big_queue.push(num);
}
}
double findMedian() {
if(big_queue.size() == 0 && small_queue.size() == 0) return NULL;
else if (big_queue.size() == small_queue.size()) return (big_queue.top()+small_queue.top())/2.0;
else return (big_queue.size()>small_queue.size()?big_queue.top():small_queue.top());
}
};
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder* obj = new MedianFinder();
* obj->addNum(num);
* double param_2 = obj->findMedian();
*/

(3)1046最后一块石头的重量–简单
题目描述
有一堆石头,每块石头的重量都是正整数。
每一回合,从中选出两块 最重的 石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
如果 x == y,那么两块石头都会被完全粉碎;
如果 x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。
最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。

java版:
class Solution{
public int lastStoneWeight(int[] stones{
PriorityQueue<Integer>maxheap = new PriorityQueue<>((i1,i2)->i2-i1);
for(int i=0;i<stone.length;i++){
maxheap.offer(stones[i]);
}
while(maxheap.size()>=2){
int x=maxheap.poll();
int y=maxheap.poll();
if(x>y)
maxheap.offer(x-y);
}
return maxheap.size()==1?maxheap.peek():0;
}
}
priorityqueue优先队列实际上是一个堆,不加说明,实际上是一个小根堆,可以用上述方法改写为大根堆,也可以自己指定比较器进行比较: PriorityQueue<Integer> maxheap = new PriorityQueue<Integer>(stones.length,new Comparator<Integer>(){ public int compare(Integer i1,Integer i2){ return i2-i1; } });

c++版:
class Solution{
public:
int lastStoneWeight(vector<int>&stones){
priority_queue<int> maxheap;
for(int x=0;x<stones.size();x++)
maxheap.push(stones[x]);
while(maxheap.size>=2){
int a=maxheap.top();maxheap.pop();
int b=maxheap.top();maxheap.pop();
int v=a-b;
if(v>0)
maxheap.push(v);
}return maxheap.top();
}
不知道为啥,我在vc里运行出来的结果是0,在LeetCode里运行出来就是2了,欢迎各位大佬批评指正~



c++中的priority_queue与java中的priorityqueue不一样,c++默认是大根堆,使用时需要包含头文件#include
定义:priority_queue<Type, Container, Functional>
Type 就是数据类型,Container 就是容器类型(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。
vector是一个容器,它可以容纳多种类型的数据,使用时需要包含头文件#include
一、vector 的初始化:可以有五种方式,举例说明如下:
(1)vector a(10);
——定义了10个整形元素的向量(尖括号中为元素类型名,它可以是任何合法的数据类型),但没有给出初值,其值是不确定的。
(2)vector a(10,1);
——定义了10个整型元素的向量,且给出每个元素的初值为1
(3)vector a(b);
——用b向量来创建a向量,整体复制性赋值
(4)vector a(b.begin(),b.begin+3);
——定义了a值为b中第0个到第2个(共3个)元素
(5)int b[7]={1,2,3,4,5,9,8};
vector a(b,b+7);
——从数组中获得初值
二、vector对象的几个重要操作,举例说明如下:
**(1)a.assign(b.begin(), b.begin()+3);** //b为向量,将b的0~2个元素构成的向量赋给a
**(2)a.assign(4,2);** //是a只含4个元素,且每个元素为2
**(3)a.back();** //返回a的最后一个元素
**(4)a.front();** //返回a的第一个元素
**(5)a[i];** //返回a的第i个元素,当且仅当a[i]存在2013-12-07
**(6)a.clear();** //清空a中的元素
**(7)a.empty();** //判断a是否为空,空则返回ture,不空则返回false
**(8)a.pop_back();** //删除a向量的最后一个元素
**(9)a.erase(a.begin()+1,a.begin()+3);** //删除a中第1个(从第0个算起)到第2个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+ 3(不包括它)
**(10)a.push_back(5);** //在a的最后一个向量后插入一个元素,其值为5
**(11)a.insert(a.begin()+1,5);** //在a的第1个元素(从第0个算起)的位置插入数值5,如a为1,2,3,4,插入元素后为1,5,2,3,4
**(12)a.insert(a.begin()+1,3,5);** //在a的第1个元素(从第0个算起)的位置插入3个数,其值都为5
**(13)a.insert(a.begin()+1,b+3,b+6);** //b为数组,在a的第1个元素(从第0个算起)的位置插入b的第3个元素到第5个元素(不包括b+6),如b为1,2,3,4,5,9,8 ,插入元素后为1,4,5,9,2,3,4,5,9,8
**(14)a.size();** //返回a中元素的个数;
**(15)a.capacity();** //返回a在内存中总共可以容纳的元素个数
**(16)a.resize(10);** //将a的现有元素个数调至10个,多则删,少则补,其值随机
**(17)a.resize(10,2);** //将a的现有元素个数调至10个,多则删,少则补,其值为2
**(18)a.reserve(100);** //将a的容量(capacity)扩充至100,也就是说现在测试a.capacity();的时候返回值是100.这种操作只有在需要给a添加大量数据的时候才 显得有意义,因为这将避免内存多次容量扩充操作(当a的容量不足时电脑会自动扩容,当然这必然降低性能)
**(19)a.swap(b);** //b为向量,将a中的元素和b中的元素进行整体性交换
**(20)a==b;** //b为向量,向量的比较操作还有!=,>=,<=,>,<
复制代码
三、顺序访问vector的几种方式,举例说明如下:
(1)向向量a中添加元素
1 vector a;
2 for(int i=0;i<10;i++)
3 a.push_back(i);
2、也可以从数组中选择元素向向量中添加
int a[6]={1,2,3,4,5,6};
vector b;
for(int i=1;i<=4;i++)
b.push_back(a[i]);
3、也可以从现有向量中选择元素向向量中添加
int a[6]={1,2,3,4,5,6};
vector b;
vector c(a,a+4);
for(vector::iterator it=c.begin();it<c.end();it++)
b.push_back(*it);
4、也可以从文件中读取元素向向量中添加
ifstream in(“data.txt”);
vector a;
for(int i; in>>i)
a.push_back(i);
5、【误区】
vector a;
for(int i=0;i<10;i++)
a[i]=i;
//这种做法以及类似的做法都是错误的。刚开始我也犯过这种错误,后来发现,下标只能用于获取已存在的元素,而现在的a[i]还是空的对象
(2)从向量中读取元素
1、通过下标方式读取
int a[6]={1,2,3,4,5,6};
vector b(a,a+4);
for(int i=0;i<=b.size()-1;i++)
cout<<b[i]<<" ";
2、通过遍历器方式读取
int a[6]={1,2,3,4,5,6};
vector b(a,a+4);
for(vector::iterator it=b.begin();it!=b.end();it++)
cout<<*it<<" ";
来源:C++ vector的用法(整理)
链接:https://blog.youkuaiyun.com/wkq0825/article/details/82255984


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









