







 文章介绍了HashMap与Map的区别,包括它们的底层实现(哈希表与红黑树)、查找和插入效率。通过编程示例展示了如何使用HashMap解决两数之和问题,以及如何利用Map的特性(如逆序遍历)转换整数为罗马数字。此外,还探讨了在处理糖果分配和回文串问题时如何利用数据结构优化算法,强调了unordered_map在性能上的优势。
文章介绍了HashMap与Map的区别,包括它们的底层实现(哈希表与红黑树)、查找和插入效率。通过编程示例展示了如何使用HashMap解决两数之和问题,以及如何利用Map的特性(如逆序遍历)转换整数为罗马数字。此外,还探讨了在处理糖果分配和回文串问题时如何利用数据结构优化算法,强调了unordered_map在性能上的优势。
预备知识:
map和hashmap的区别:
| hashmap(unordered_map) | map |
|---|---|
| 底层为哈希表 | 底层为红黑树 |
| 非按键排序 | 按键排序 |
| 查找效率为O(1) | 查找效率为O(logn) |
| 插入的时间是O(logn) | 插入的时间是O(logn) |
| key只能是int、double等基本类型以及string | 支持所有类型的键值对 |
共同点:
键都不能重复
用法类似
例题:
(1)1、两数之和–知道目标值,找下标–简单
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。

#include <vector>
#include <unordered_map>
using namespace std;
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> hash; // 哈希表用于记录数字对应的下标
for (int i = 0; i < nums.size(); ++i) {
//寻找hashmap中是否有与当前元素互补的元素
int n = nums[i];
int complement = target - n;
//如果有两个相同的元素之和为target,计算前再插入,无影响
if (hash.count(complement)) {
return {hash[complement], i}; // 找到答案,返回下标对
}
hash[n] = i; // 记录数字对应的下标
}
return {}; // 找不到答案,返回空数组
}
};
(2)12整数转罗马数字 --,需要从大到小遍历,所以用的map–中等
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给你一个整数,将其转为罗马数字。

其它知识点:
map从大到小遍历:
方法(1)重载 () 运算符
①重载 () 运算符,接收两个元素参数,返回一个 bool 类型的比较结果。
②在定义 std::map 或其他关联容器时,将该比较函数对象作为模板参数传入,以覆盖默认的元素比较方式。
#include <iostream>
#include <map>
// 定义一个比较函数对象,按照元素值大小从大到小排序
class GreaterValue {
public:
bool operator()(const std::pair<int, int>& p1, const std::pair<int, int>& p2) const {
return p1.second > p2.second;
}
};
int main() {
// 定义一个 map,键值类型为 int,值类型为 int
std::map<int, int, GreaterValue> myMap;
// 插入一些元素
myMap.insert({3, 10});
myMap.insert({1, 20});
myMap.insert({2, 30});
// 遍历 map,输出每个元素
for (const auto& elem : myMap) {
std::cout << elem.first << " => " << elem.second << '\n';
}
return 0;
}
方法(2)利用反迭代器
使用迭代器逆序遍历 map 可以利用反向迭代器 rbegin() 和 rend() 来实现。具体的方法是:对于普通迭代器,我们可以使用前缀自增运算符 ++ 来向前移动迭代器查找 map 元素,而对于反向迭代器,则需要使用前缀自减运算符 – 来向后移动迭代器查找 map 元素
实现中利用了方法(2)
class Solution {
public:
string intToRoman(int num) {
string result;
map<int, string> intToRomanStr = {
{1, "I"}, {4, "IV"}, {5, "V"}, {9, "IX"},
{10, "X"}, {40, "XL"}, {50, "L"}, {90, "XC"},
{100, "C"}, {400, "CD"}, {500, "D"}, {900, "CM"},
{1000, "M"}};
//逆序遍历map,用反向迭代器
auto it = intToRomanStr.rbegin();
//cout<< " it.first = "<< (*it).first << " it.second = "<< (*it).second;
while(num > 0){
//cout<< "num = " << num;
for(; it != intToRomanStr.rend() && (num < (*it).first);it++){};
//it指向num第一个大于的数字
//cout<< " it.first = "<< (*it).first << " it.second = "<< (*it).second;
int times = num/(*it).first;
while(times > 0) {
result+=(*it).second;
times--;
}
num = num%(*it).first;
//cout<< " remainder = "<< num << endl;
}
return result;
}
};
(3)575分糖果–简单
Alice 有 n 枚糖,其中第 i 枚糖的类型为 candyType[i] 。Alice 注意到她的体重正在增长,所以前去拜访了一位医生。
医生建议 Alice 要少摄入糖分,只吃掉她所有糖的 n / 2 即可(n 是一个偶数)。Alice 非常喜欢这些糖,她想要在遵循医生建议的情况下,尽可能吃到最多不同种类的糖。
给你一个长度为 n 的整数数组 candyType ,返回: Alice 在仅吃掉 n / 2 枚糖的情况下,可以吃到糖的 最多 种类数。

其它知识点
判断unordered_map是否存在某键:
判断vector是否存在某键
//判断unordered_map是否存在某键
unordered_map<int, int> tmp;
插入一些值
if(tmp.find(32) == tmp.end()) cout<<"不存在";
else cout<< "存在";
//判断vector是否存在某键
vector<int, int> tmp;
插入一些值
if(find(tmp.begin(), tmp.end(), 32) == tmp.end()) cout<<"不存在";
else cout<< "存在";
(1)使用unordered_map存储糖果种类
class Solution {
public:
int distributeCandies(vector<int>& candyType) {
unordered_map<int, int> eachTypeNumber;
int typeNum = 0;
int maxEatNum = candyType.size()/2;
//一遍遍历(边遍历边判断),计算糖果的种类及数量
for(auto it:candyType){
int type = it;
if(eachTypeNumber.find(type) == eachTypeNumber.end()){
eachTypeNumber[type] = 0;
typeNum++;
if(typeNum >= maxEatNum) return maxEatNum;
}
eachTypeNumber[type]++;
}
return typeNum;
}
};

(2)使用vector存储糖果种类
class Solution {
public:
int distributeCandies(vector<int>& candyType) {
//存贮种类->数量
vector<int> eachTypeNumber;
int typeNum = 0;
int maxEatNum = candyType.size()/2;
//一遍遍历(边遍历边判断),计算糖果的种类及数量
for(auto it:candyType){
int type = it;
//如果hash表中没有添加过该种类,种类数加一
if(find(eachTypeNumber.begin(), eachTypeNumber.end(), it) == eachTypeNumber.end()){
eachTypeNumber.push_back(it);
typeNum++;
//如果种类数大于等于可以吃的数量,则返回最大可以吃的数量
if(typeNum >= maxEatNum) return maxEatNum;
}
}
//如果全部遍历完种类数还小于可以吃的数量,就返回种类数
return typeNum;
}
};

unordered_map明显比vector快不少
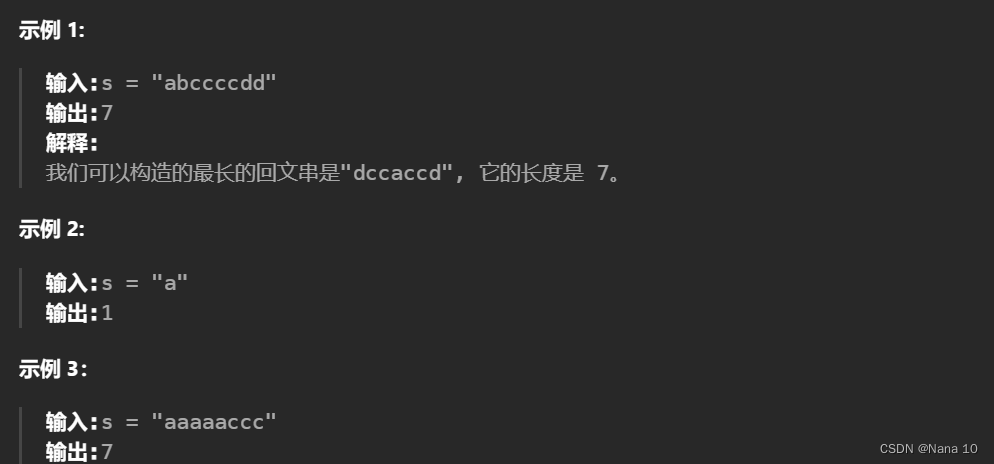
(4)409最长回文串–简单
给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的回文串 。
在构造过程中,请注意 区分大小写 。比如 “Aa” 不能当做一个回文字符串。
知识点
map数据结构的使用
map的遍历方法
hash函数
代码
class Solution {
public:
int longestPalindrome(string s) {
map<char, int> node_map;
//记录每个字符出现的个数
for(int i = 0; i< s.length(); i++){
if( node_map.find(s[i]) == node_map.end() )
node_map[s[i]] = 0;
node_map[s[i]]++;
}
//迭代器
map<char, int>::iterator it;
int sum = 0;
int mediumFlag = 0;
for(it = node_map.begin(); it != node_map.end(); it++){
//如果该字符出现次数为偶数,则可对称摆放
if(it->second % 2 == 0) sum += it->second;
//如果出现次数为奇数,且未有中间字符,则一个字符放中间,其余对称摆放
else if(mediumFlag == 0) {
sum += it->second;
mediumFlag = 1;
}
//如果出现次数为奇数且已有中间字符,则丢弃一个字符,其余对称摆放
else sum += it->second -1;
}return sum;
}
};
结果

(5)290单词规律–简单
给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。

知识点
hash_map
hash_map 的遍历
代码
class Solution {
public:
bool wordPattern(string pattern, string s) {
//字符到单词的映射要唯一
//单词到字符的映射也要唯一
map<char, string> match;
map<string, char> match_str_char;
char patternChar;
int j = 0;
for(int i = 0; i<pattern.length(); i++){
string temp_str = "";
//如果pattern还没遍历结束,s已经遍历结束,则未匹配成功
if(j>= s.length()) return false;
else{
//提取字符串
while(j< s.length() && s[j] != ' '){
temp_str+= s[j];
j++;
}
if(s[j] == ' ') j++;
}
//如果未在字符到单词的映射中找到该字符
if(match.find(pattern[i]) == match.end()){
//添加映射
match[pattern[i]] = temp_str;
//如果在单词到字符的映射中未找到该字符,添加映射
if(match_str_char.find(temp_str) == match_str_char.end()) match_str_char[temp_str] = pattern[i];
//否则,若单词已经对应了其它字符,返回假
else if(match_str_char[temp_str] !=pattern[i]) return false;
}
//否则,若字符已经对应了其它单词,返回假
else if(match[pattern[i]] != temp_str) return false;
}
//如果字符已经遍历完成,单词还未完成,则返回假
if(j < s.length()) return false;
return true;
}
};
提交结果

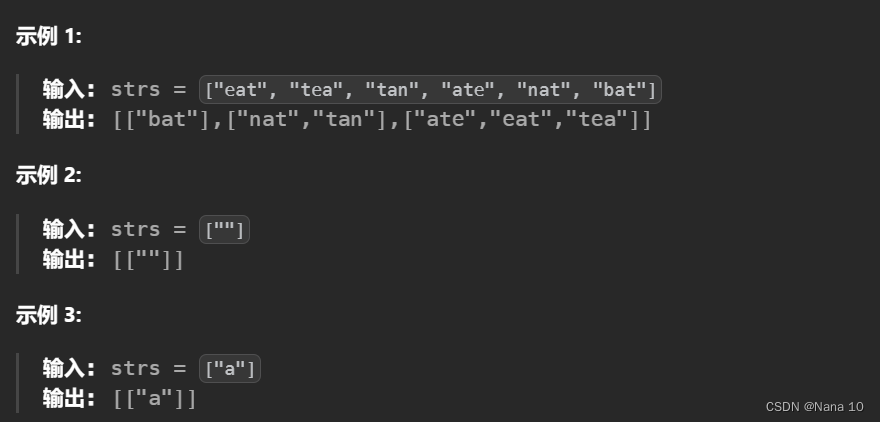
(6)49字母异位词分组–中等
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
知识点
hash_map
hash_map的遍历
sort函数的使用
字符串排序
代码
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> result;
if(strs.size() == 0) return result;
map<string, vector<string>> hash_map;
for(int i = 0; i< strs.size(); i++){
string temp_str = strs[i];
//字符串的排序,组成字符相同的字符串,排序后的结果都是一样的
sort(temp_str.begin(), temp_str.end());
//如果map中没有该字符串,则先添加键
if(hash_map.find(temp_str) == hash_map.end()) {
vector<string> temp;
hash_map[temp_str] = temp;
}
//将字符串push到对应键中
hash_map[temp_str].push_back(strs[i]);
}
map<string, vector<string>>::iterator it;
//hash_map的遍历,将映射完成的,同一组的值push到result中
for(it = hash_map.begin(); it!=hash_map.end(); it++){
result.push_back(it->second);
}
return result;
}
};
结果

(7)3无重复字符的最长子串–中等
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。

知识点
双指针维护窗口
hash_map
代码
class Solution {
public:
int lengthOfLongestSubstring(string s) {
//双指针维护窗口
int begin = 0;
int end = 0;
int result = 0;
int maxLength = 0;
map<char, int>char_map;
//当end未到达最后时,持续循环
while(end < s.length()){
//cout<<"char_map[s[end]]="<<s[end];
//每向后一个,最长长度加1
maxLength++;
//如果最后字符无重复,将hash表中该字符的映射置为1
if(char_map.find(s[end]) == char_map.end() || char_map[s[end]] == 0) {
//cout<<" "<<char_map[s[end]]<<"+1"<< endl;
char_map[s[end]] = 1;
}
//如果有重复,将begin向后移动,直至无重复为止
else if(char_map[s[end]] == 1){
//cout<<" "<<char_map[s[end]]<<"-1"<<endl;
while(char_map[s[end]] == 1){
char_map[s[begin]] --;
begin++;
maxLength--;
}char_map[s[end]] ++;
}
//如果更新后的最长串大于历史最长串,则更新result
if(maxLength > result) result = maxLength ;
end++;
}
return result;
}
};
结果


















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









