







 本文介绍了在Python中使用requests库时遇到的获取content-length和content-type的问题,特别是针对存在鉴权的私有文件。通过设置requests.head的Accept-Encoding参数和使用Range头在GET请求中获取Content-Range,解决了获取文件真实大小的难题。
本文介绍了在Python中使用requests库时遇到的获取content-length和content-type的问题,特别是针对存在鉴权的私有文件。通过设置requests.head的Accept-Encoding参数和使用Range头在GET请求中获取Content-Range,解决了获取文件真实大小的难题。
背景
把同一份文件分别存放到了两个oss(可以理解为两个存储商),通过两个oss 返回的下载 url 获取 两个文件的content-length 和 content-type信息,对比是否一致
遇到的问题:
1、当通过response header 获取content-length 的时候,千牛的url 没有返回 content-length
2、涉及到鉴权的私有文件url 获取不到真正的content-length
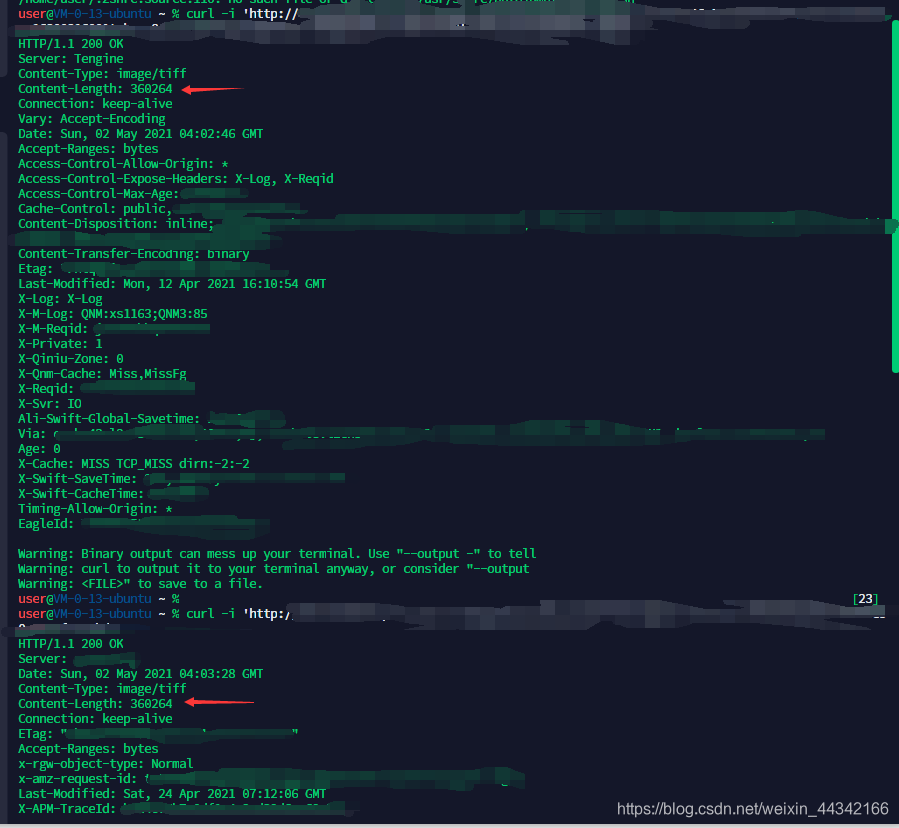
通过curl -i url 是可以返回同一个文件 存在两个url 的content-length 的,那怎么通过python解决以上两个问题呢(方法不一定最好,欢迎拍砖!)
一、解决获取不到content-length问题
方法:通过python 的requests.head(url,headers)指定header 里的Accept-Encoding参数,来获取文件流真实的content-length
原因:请求参数 headers里不指定文件流的Accept-Encoding,当服务器有对文件做了压缩后返回时,content-length就有可能获取不到
参考了博文:https://blog.youkuaiyun.com/chouhuan1877/article/details/100808814 有说明获取不到content-length的原因
实验对比:
def head_getcontent(file,srcDownloadUrl,distDownloadUrl):
session = requests.session()
headers = {
"Accept-Encoding": "identity"
}
# 通过requests.head()填入不同的参数处理千牛的文件url
src_only_url = requests.head(url=srcDownloadUrl)
src_url_headers = requests.head(url=srcDownloadUrl, headers=headers)
src_url_headers_stream = requests.head(url=srcDownloadUrl, stream=True, headers=headers)
print("src_only_url headers= {}".format(src_only_url.headers))
print("src_url_headers headers= {}".format(src_url_headers.headers))
print("src_url_headers_stream headers= {}" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









