







 本文深入探讨了深度学习中的卷积神经网络,包括经典的LeNet-5、AlexNet和VGG-16网络结构,以及解决深度网络训练问题的残差网络ResNets。此外,还介绍了1 * 1卷积在网络中的作用和Inception network的设计理念,这些工具和技巧对于提升计算机视觉模型的性能至关重要。
本文深入探讨了深度学习中的卷积神经网络,包括经典的LeNet-5、AlexNet和VGG-16网络结构,以及解决深度网络训练问题的残差网络ResNets。此外,还介绍了1 * 1卷积在网络中的作用和Inception network的设计理念,这些工具和技巧对于提升计算机视觉模型的性能至关重要。
三个经典网络
LeNet-5

一个十分经典网络,处理任务是手写数字的识别。采用如下结构:
输入层:
32 * 32 * 1灰度图
卷积层(C1):
6个 5 * 5 过滤器,步长为1,得到28 * 28 * 6的输出
池化层(S1):(平均池化)
过滤器 2 * 2,步长为2, 输出14 * 14 * 6
卷积层(C2):
16个 5 * 5 过滤器,步长为1,得到10 * 10 * 16的输出
池化层(S2):(平均池化)
过滤器 2 * 2,步长为2, 输出5 * 5 * 16
全连接层(FC1):
120神经元
全连接层(FC2):
84神经元
输出层:
10节点(对应10数字)
由于年代久远,神经元个数较少,没有用到relu激活函数,输出层并没有采用softmax
AlexNet
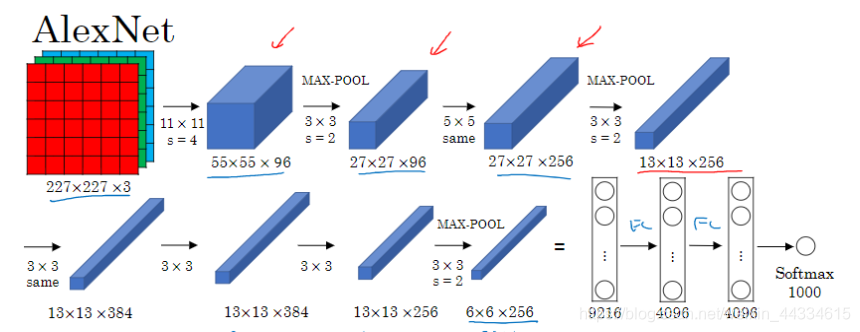
和LeNet-5类似,不再详细阐述结构。
神经元个数大大增多,采用了最大池化替代平均池化,同时采用relu激活函数,采用了softmax激活函数。
VGG-16
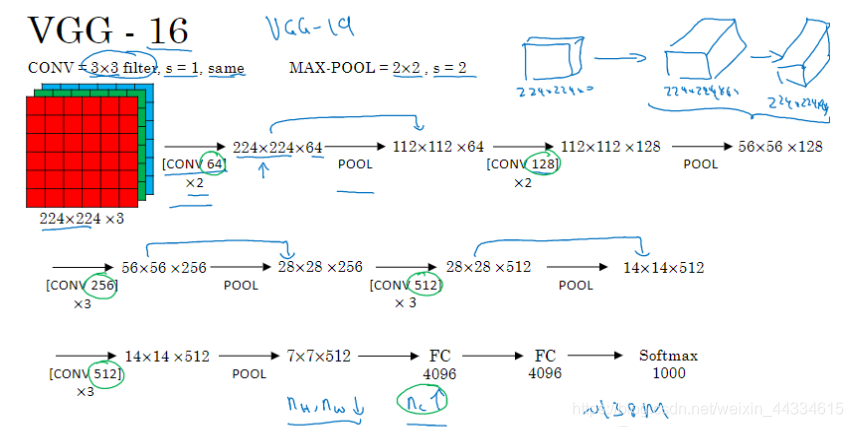
观察到每一层卷积层,都采用”same“模式的pattern,过滤器个数翻倍。每个池化层均为2 * 2步长2,使得图片尺寸减小一半。这样使得神经元个数依次减少。
模型规模巨大。
残差网络ResNets
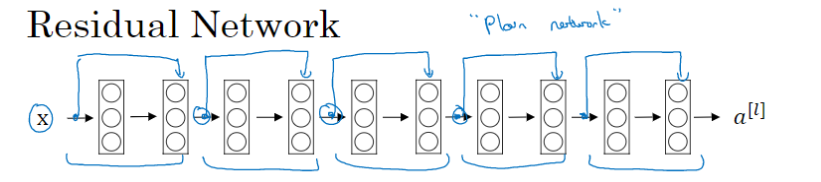
随着网络深度的增加,我们容易出现梯度爆炸和梯度衰减的现象。当层数逐渐加大时,明明应该获得更高的性能,我们的测试集准确率往往会缩小。为了解决这个问题出现了ResNets
基本单元:
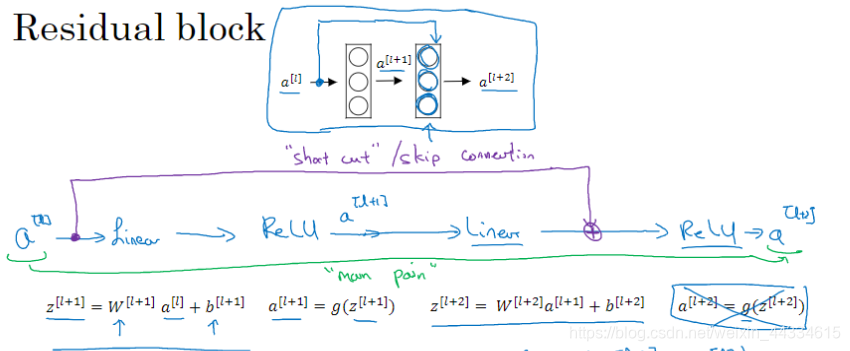
skip connection:
我们发现,a[l]层的输出A 直接送到了a[l+2]层的激活函数前与其Z值线性求和后,再经过激活函数输出。这里注意,当两层的大小不一致时,我们或采用0填充,或采用一个参数矩阵进行整形(这个选择对网络影响很小)。
这样做的好处是:虽然是两层神经网络,但是我们很容易能够学得a[l]到a[l+2]的恒等映射(之前是很不容易的),间接使得中间的层数不起作用。同时我们往往会学得比恒等映射更加nb的东西,因此网络性能会得以提升。
1 * 1卷积(网络中的网络)
乍一听1 * 1卷积有些怪异,那是因为我们只在n * n * 1的角度考虑问题。当上一层输入为n * n * nc 时,每一个1 * 1卷积都会将输入整合成n * n * 1的输出。相当于对每nc个输入的特点进行了整合。
如果说池化层可以单纯调节输出层的长和宽,那么1 * 1卷积可以单纯调节输出层深度。
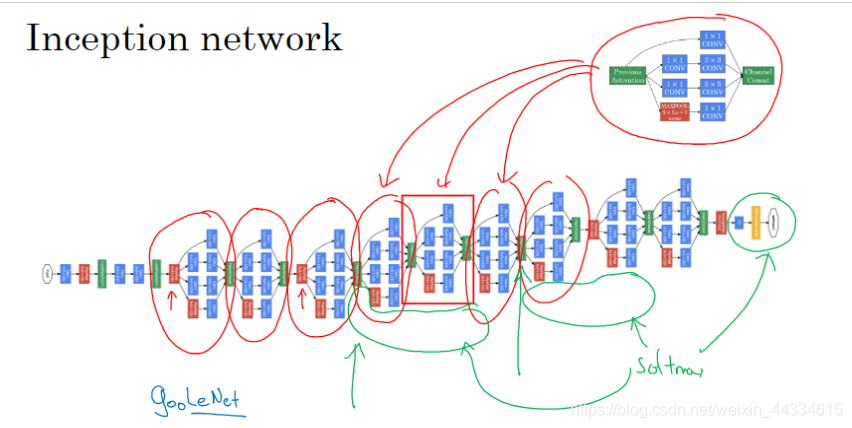
Inception network
我们在构建卷积神经网络时,往往要考虑很多超参数(卷积核大小,什么时候使用池化层等等)。Inception network可以让机器来为我们选择。
Inception network基本单元如下:
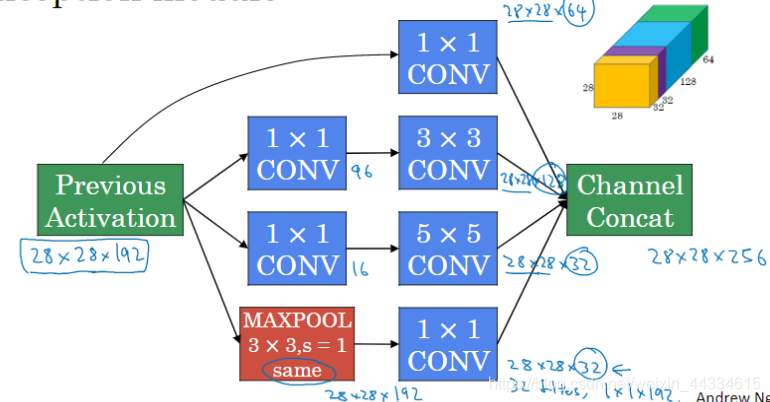
我们可以发现,我们利用不同的卷积核(甚至池化层)得到了4个长宽相同的输出,将它们纵向排列在一起,得到对应输出。
这里面的1 * 1卷积的作用有:减少连接数和计算量,整形深度(对池化层来说)
其他工具
之前提到的迁移学习(利用别人开源的已经训练好的参数)、数据扩充(图片裁剪、图片反转等)都可以帮助我们训练一个计算机视觉网络。

















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









