







 本文介绍了Batch Normalization(Batch Norm)技术在神经网络中的应用,阐述其实现方式、原理和作用。通过归一化每层神经网络的输出,Batch Norm有助于提升学习效果,减少梯度消失问题。在训练过程中,它计算每个mini-batch的均值和方差进行归一化,并在反向传播中稳定网络更新。尽管Batch Norm有一定的正则化效果,但主要的正则化手段仍是L2正则化和dropout。在预测阶段,需使用训练时的滑动平均均值和方差,避免因单个样本导致的预测失效问题。
本文介绍了Batch Normalization(Batch Norm)技术在神经网络中的应用,阐述其实现方式、原理和作用。通过归一化每层神经网络的输出,Batch Norm有助于提升学习效果,减少梯度消失问题。在训练过程中,它计算每个mini-batch的均值和方差进行归一化,并在反向传播中稳定网络更新。尽管Batch Norm有一定的正则化效果,但主要的正则化手段仍是L2正则化和dropout。在预测阶段,需使用训练时的滑动平均均值和方差,避免因单个样本导致的预测失效问题。
在之前的学习中,我们知道对于训练集X进行归一化有利于我们把代价函数从扁平拉圆,便于我们训练。
那我们想一下,如果对每层神经网络的输出,我都搞一个归一化,是不是会提升我们的学习效果呢?
Batch Norm技术就出现了
实现方式
对于之前的每个神经元,我们计算z=wTa_pre, a=g(z)。在Batch Norm中,对于每一个神经元:
z=wTa_pre (没有b的原因是反正都要归一化,无论b取何值,都会体现在下面的平均值当中被减掉)
对于一组mini-batch上的所有数据,我们计算出Z的平均值:
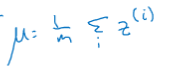
计算出Z的方差:
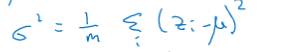
对其进行归一化,得到
Z_norm = (Z-μ)/sqrt(σ2+ε), 这里的ε是一个小常数(1e-8),为的是防止除0
为了避免始终保持均值为0,方差为1,失去活力,对每个Z_norm
Z~= Z_norm*α +β
这里的α和β起到调整每个神经元均值和方差的作用,而β也能起到之前删去的b的作用。注意对于不同的神经元α,β均不同,它们和w一样,是训练参数。
a=g(Z~)得到神经元的输出。
原理的直观理解
我们观察反向传播的过程,当我们计算到第L层时,我们实际上是跟据L-1层的A值,对第L层的W,b进行调整。而随着反向传播的进行,1到L-1层的W,b也会被修改,这回导致A[L-1]产生大量的变化,从而使得第L层的修改打了折扣。
而采用了Batch Norm后,A[L-1]的均值只会由该层的α β决定(因为Z已经均值为0,方差为1了),大大减轻了A[L-1]的变化范围。我们第L层的参数修改就有了针对性。
由于我们每次计算z的均值和方差,都是以一个mini-batch作为单位,因此对于不同的mini-batch,z的均值和方差往往会有扰动。类似于dropout的原理,这部分扰动有一定正则化的效果。但这个只是该方法的副作用。
用Batch Norm搞正则化只是图一乐,真正则化还得看L2、dropout
预测和测试时的坑
Batch-norm在进行前向传播计算Z的均值方差时,都是利用一个mini-batch进行计算。而我们在进行预测时,往往每次只丢一个数据,这会导致每层的z一定被设置成0,给啥输入都一样,失去预测能力。
即便我们每次丢好几个数据,数据分布的不同一样会对预测产生影响。
这说明在预测的时候,z的均值和方差不能进行计算了。所以我们采用滑动平均值的方式,记录训练时的均值方差的滑动平均值。预测的时候直接拿记录的值进行计算即可。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









