




摘要:通过分布式系统进行机器学习,大概就是联邦学习吧
1. 引言
通过分布式系统来增加并行和I/O带宽总量,第二节探讨机器学习的系统挑战以及如何采用高性能计算(HPC)的想法来加速和提高整个机器学习的可扩展性,第三节描述了分布式机器学习的参考架构;第四节介绍了最广泛使用的系统和库的生态,以及底层设计;第五节探讨了机器学习的主要挑战。
2. 机器学习-高性能计算挑战?
目前机器学习的实际应用包括对于Commodity Off-The-Shelf High Performance Computing(商品现成的高性能计算?);英特尔上的神经网络训练;再大型并行HPC系统上优化和有效扩展诸如提取天气模式之类的深度学习问题。
2.1纵向扩展
通常采用增加GPU的方式,或者使用专用的集成电路(ASIC),通过高度优化的设计实现专门的功能,例如谷歌的TPU,旨在加速tensorflow;也有设计了一种用于大规模神经网络的硬件加速器,再管道中引入了一个神经功能单元(NFU),将管道的输入相乘并将结果相加,并以交错的方式可选择的激活函数;或者利用深度压缩技术。这些都是采用提高单台机器的处理能力以进行大规模机器学习。
2.2横向扩展
对比于纵向,横向的优势是:1.设备成本较低;2.具有故障恢复能力;3.与单台机器相比,总I/O带宽增加了。当训练机器学习模型时,需要收集大量数据,对于每一个节点都有一个I/O是一个不错的选择,挑战在于不是所有的ML算法都适用于分布式计算模型,因此横向扩展一般用于能够高度实现并行的算法。
3. 分布式机器学习的架构
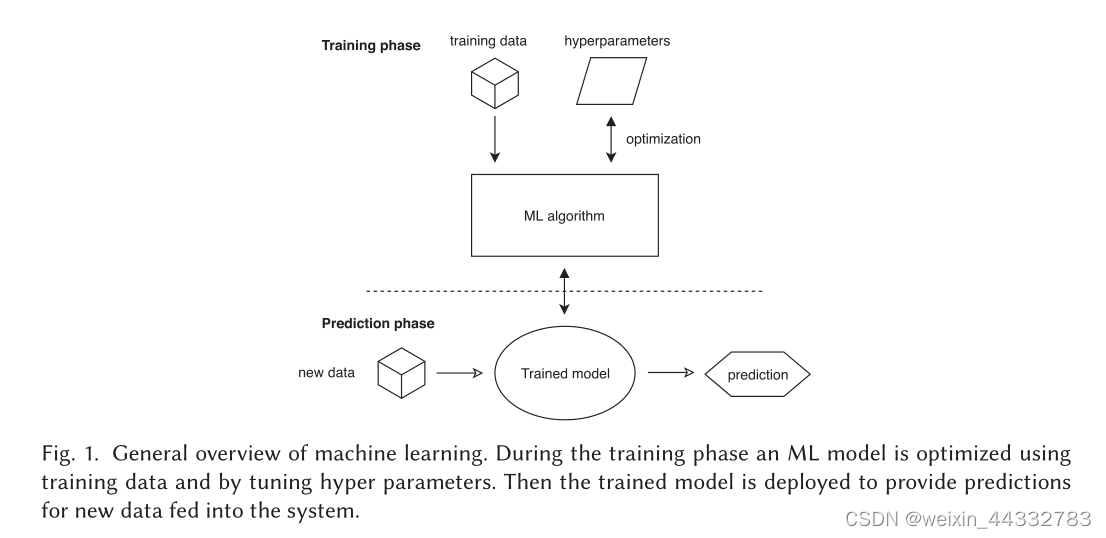
文章设计并提出了涵盖整个设计空间的通用架构,概述:在训练阶段,使用训练数据并调整超参数来优化ML模型,然后部署经过训练的模型,并为新数据提供预测。在训练阶段通常使用大量的算力,但是预测可以使用较少的计算能力。而且训练阶段和预测阶段并不排斥,二者可以并行,这里涉及到增量学习,结合了训练和预测,并通过使用自预测阶段的新数据不断训练模型。
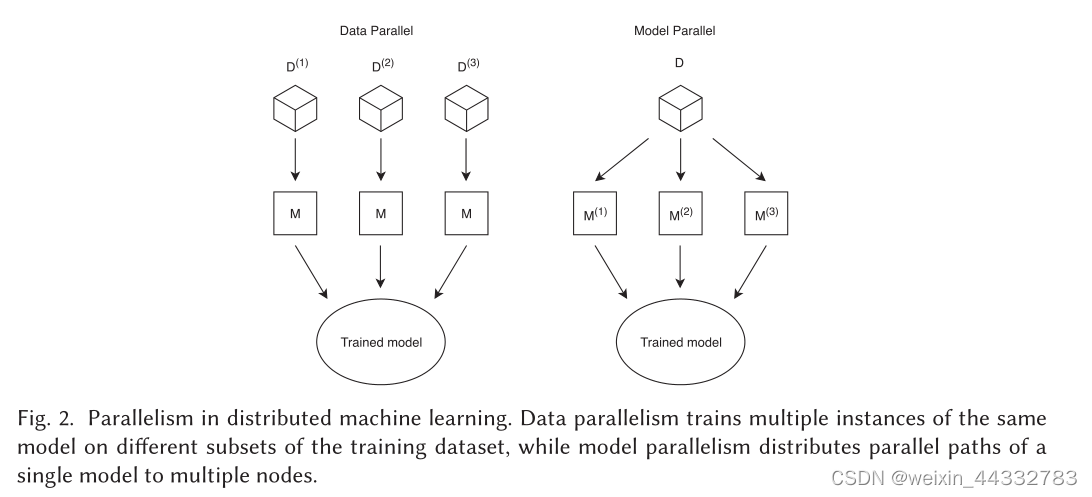
图中表示分布式机器学习的两种模式,分别是数据并行和模型并行,对于数据并行,所有工作节点都可以使用相同的模型,因此可以与每个ML算法一起使用,并在数据样本上具有独立同分布;而模型并行中,整个数据的副本由于在模型的不同部分运行的工作节点处理,因此,模型是所有模型部分的集合,不能适用于所有算法。
3.1 机器学习算法
算法根据反馈、目的和方法三方面因素对数据做出预测。
3.1.1反馈
监督学习:使用由输入对象和所需要的输出值组成的训练数据,监督学习算法需要找到一个将输入数据映射到所需输出的函数,然后将函数应用于新数据以预测输出。缺点是模型越复杂,需要越多的训练数据来获取准确的预测。
无监督学习:使用没有输出值的输入对象来组成训练数据,无监督学习的目的在于找到一个能准确表达数据结构的函数,并对未排序的输入数据进行分组。常用于提取数据关键特征的降维问题,并使用相似性度量生成反馈。
半监督学习:少量标记数据辅以大量未标记数据。
强化学习:
3.1.2目的
异常检测、分类、收集、降维、表征学习、回归
3.1.3方法
进化算法(遗传算法):在计算所有生成模型的适应度得分后,下一次迭代会根据模型的突变和交叉创建新的基因型,从而产生更准确的估计。例如:神经网络、决策树。
基于随机梯度下降(SGD)算法:最小化定义在模型输出上的损失函数。损失函数通常代表要最小化的实际误差,例如在回归问题,模型输出和期望输出之间的均方误差,SGD是各种ML模型最常用的训练方法。
支持向量机(SVM):将数据点映射到高维向量以进行分类和聚合。
&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









