








目录
2、group_concat( )按分组显示每一组的详细情况
比较高级的MySQL语句
1、limit 去重并显示第三名的成绩
select distinct score "第三名成绩"
from emp where score > 85
order by score DESC
limit 2,1;执行结果如下:
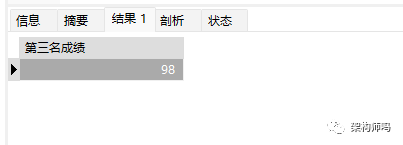
这里用到了limit函数,详解如下。
limit 1,2:第一个数字代表跳过的记录数,后面的数字代表显示的记录数。
limit 3:后面只有一个数字,表示一共显示多少条记录数;
2、group_concat( )按分组显示每一组的详细情况
select status "交易状态",
group_concat(store_number) "门店编号"
from orders
group by status;上面的语句执行结果如下:
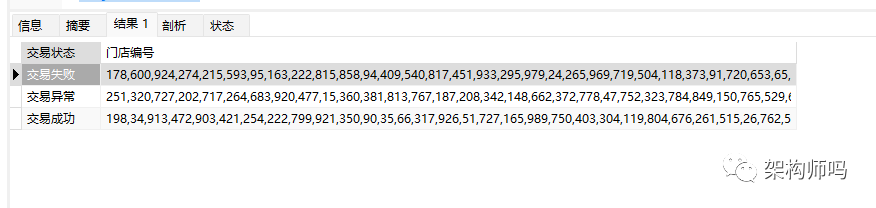
group_concat():按分组显示每个组内的具体的字段值;例如上图,按照交易状态分组后,每个状态具体显示有哪些门店(门店编号)。
3、group by 对查询结果分组
select status "交易状态",
count(store_number) "门店数量"
from orders
group by status;语法:group by <字段名>
group by 用于对一个或多个字段查询的结果进行分组,上面的语句执行结果如下:
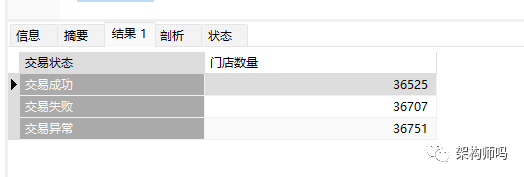
上图的查询意思是,对交易状态进行查询,并按门店数量进行统计数量,也就是每个交易状态下有多少门店。
4、with rollup 对分组的字段进行合计
select status "交易状态",
count(store_number) "门店数量"
from orders
group by status
with rollup ;with rollup关键字就好比我们EXCEL做表的时候,对一列的数据进行最后的合计的操作,上面的语句执行结果如下:
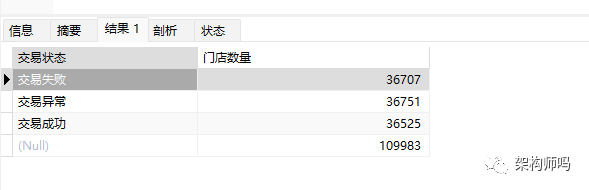
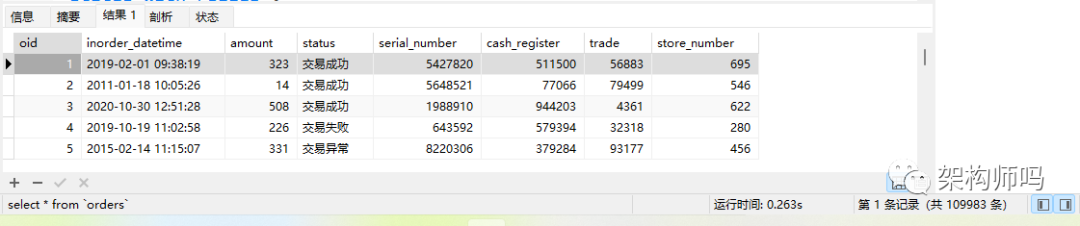
这里统计出交易失败、交易成功、交易异常的三种状态的门店合计有109983个,就是起到一个合计的效果。
用 select * from orders 查询验证后结果符合预期:
5、窗口函数
窗口函数,顾名思义就像在一面墙开了一扇窗口一样,这扇窗户既是这面墙的一部分,也能独立进行操作。
在MySql中,窗口函数也和窗户一样,对部分数据进行操作,而不影响员原本的数据。也就是在聚合数据的同时保留原来的数据。
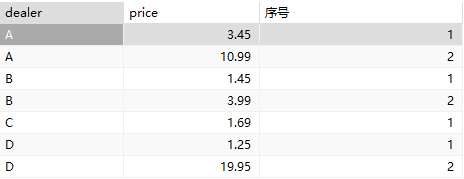
比如下面的数据表按照A、B、C、D分组后有4个窗口:
窗口函数语法:
窗口函数 over(partition by <字段> order by <字段> )over:关键字,用来指定函数执行的窗口范围。如果后面括号中什么都不写,则意味着窗口包含满足WHERE条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下4种语法来设置窗口;
partition by <字段> :用来指定窗口按照哪些字段(一个或多个)进行分组;
order by <字段>:该子句用来指定窗口中的记录按照哪些字段进行排序,当其后存在多个字段时,则优先按照最左边字段进行排序。
另外,当over之后的语句太长,可以使用window关键字来给当前窗口起别名。
窗口函数有:
row_number()、rank()、dense_rank()、percent_rank()、lag(字段1,n)、first_val(字段)、last_val(字段),聚合函数。
5.1 建表
create table date (
year year default null comment '年份',
month int unsigned default null comment '月份',
day int unsigned default null comment '天数',
did int default null comment 'id'
) engine=innodb default charset=utf8mb4 collate=utf8mb4_0900_ai_ci comment '日期表';建表成功,插入数据的表:
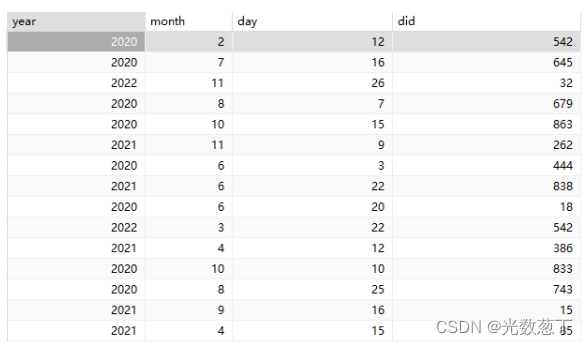
为了使效果明显,我这里数据共有15条,也够我们这次测试需求了。
5.2 序号函数
5.2.1 row_number()
这个函数可以实现每个组内进行排序,也可以说是每个组内的序号。
select year,
month,
day,
row_number() over ( partition by year order by day )
from date;执行后,效果如下:
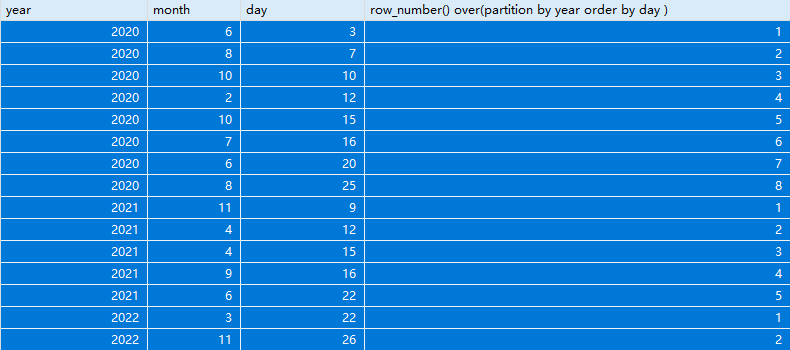
可以看到按照2020年、2021年、2022年分组后,每个组内都按天数进行了排名,同时原始的数据还在。
5.2.2 rank()
同样是序号函数,与row_number() 函数不同的是,rank()函数会相同的数值进行重复排序,
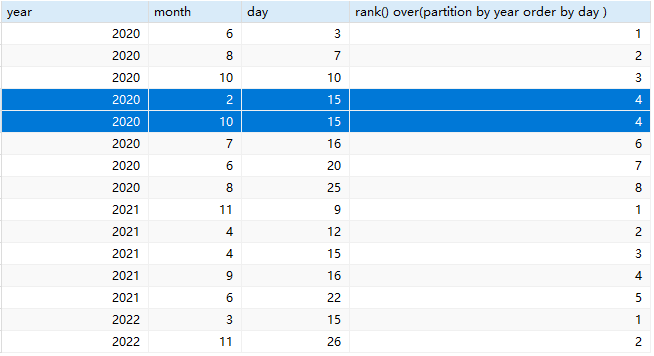
select year,month, day,
rank()
over(partition by year order by day )
from date;运行后效果如下:
2020年2月和10月都是15,因此使用rank()函数后,排名就是4,是相同的。
5.2.3 dense_rank()
也是序号函数,它会产生连续的记录序号。
select year,month, day,dense_rank()
over(partition by year order by day )
from date;运行后效果如下:
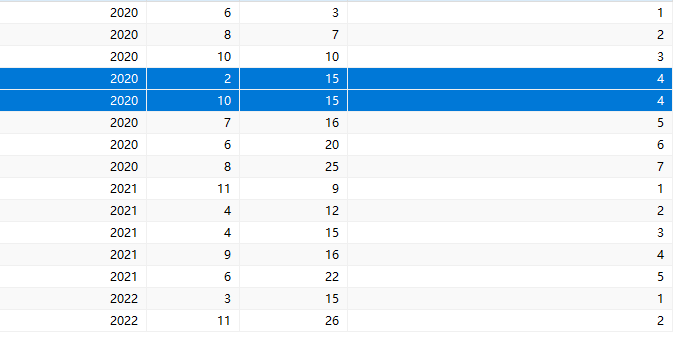
rank()会产生序号相同的记录,同时产生的序号会不连续直接从4跳到6,而dense_rank()产生序号相同的记录,但是序号不会断开,虽然是两个4但下一个记录还是从5开始的。
5.2.4 persent_rank()
返回某列或某列组合后每行的百分比排序,其实就是当前的记录数和组内记录总数的占比。
select year,month, day,dense_rank()
over(partition by year order by day )
from date;运行后效果如下:
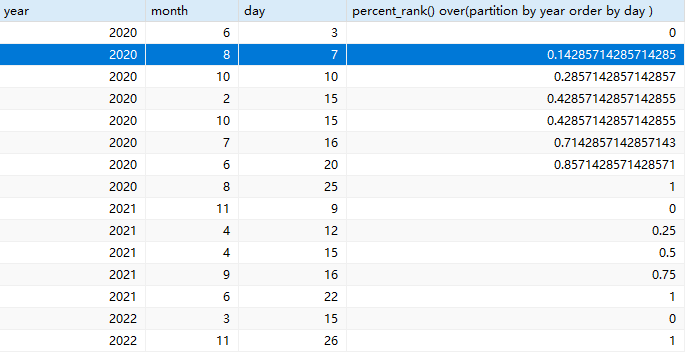
那么怎么得到这个结果的呢?
别看出来的数据一大堆,看似复杂,其实很简单。就是把day按rank()函数排序后进行一个:rank()-1/组内记录总数-1。比如上图的第二行的结果:
rank()后排序是2,2020年总记录数为8,可计算出:2-1/8-1=0.14285714285714285 就是这么简单。
5.2.5 lag()、lead()
lag 和lead是前后函数, 有三个参数lag(<字段>,n,n),第一个参数是列名,第二个参数是偏移的offset,第三个参数是超出记录窗口时的默认值,不写的话默认为null。举例如下:
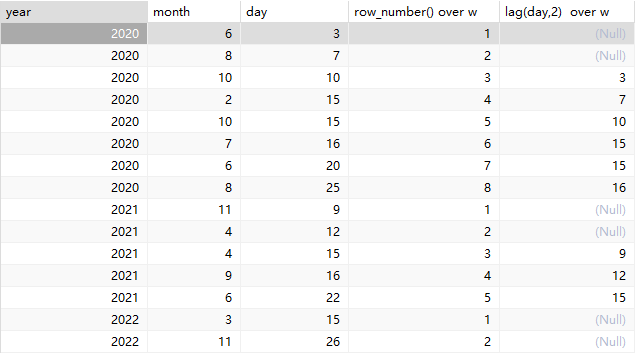
select year,month, day,
row_number() over w,
lag(day,2) over w
from date
window w
as(partition by year order by day) ;运行后效果如下:
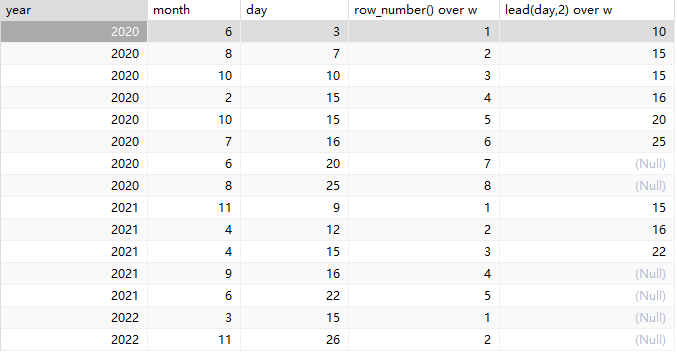
lead()函数用法
select year,month, day,
row_number() over w,
lead(day,2) over w
from date
window w
as(partition by year order by day) ;运行后效果如下:
5.2.6 聚合函数
常用的聚合函数也可以作为窗口函数使用,比如sum()、avg()、max()、min()、count(),如下:
select year,month,
sum(month) over w as sum,
avg(month) over w as avg,
max(month) over w as max,
min(month) over w as min,
count(month) over w as count
from date window w
as(partition by year order by month) ;运行后效果如下:
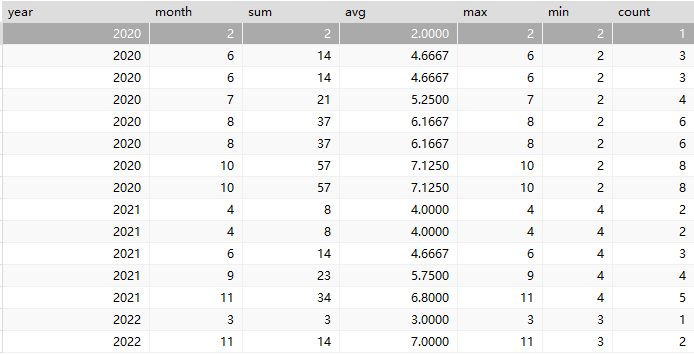
上面是根据月份计算出的聚合函数的值。

















 4160
4160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









