







一.创建项目
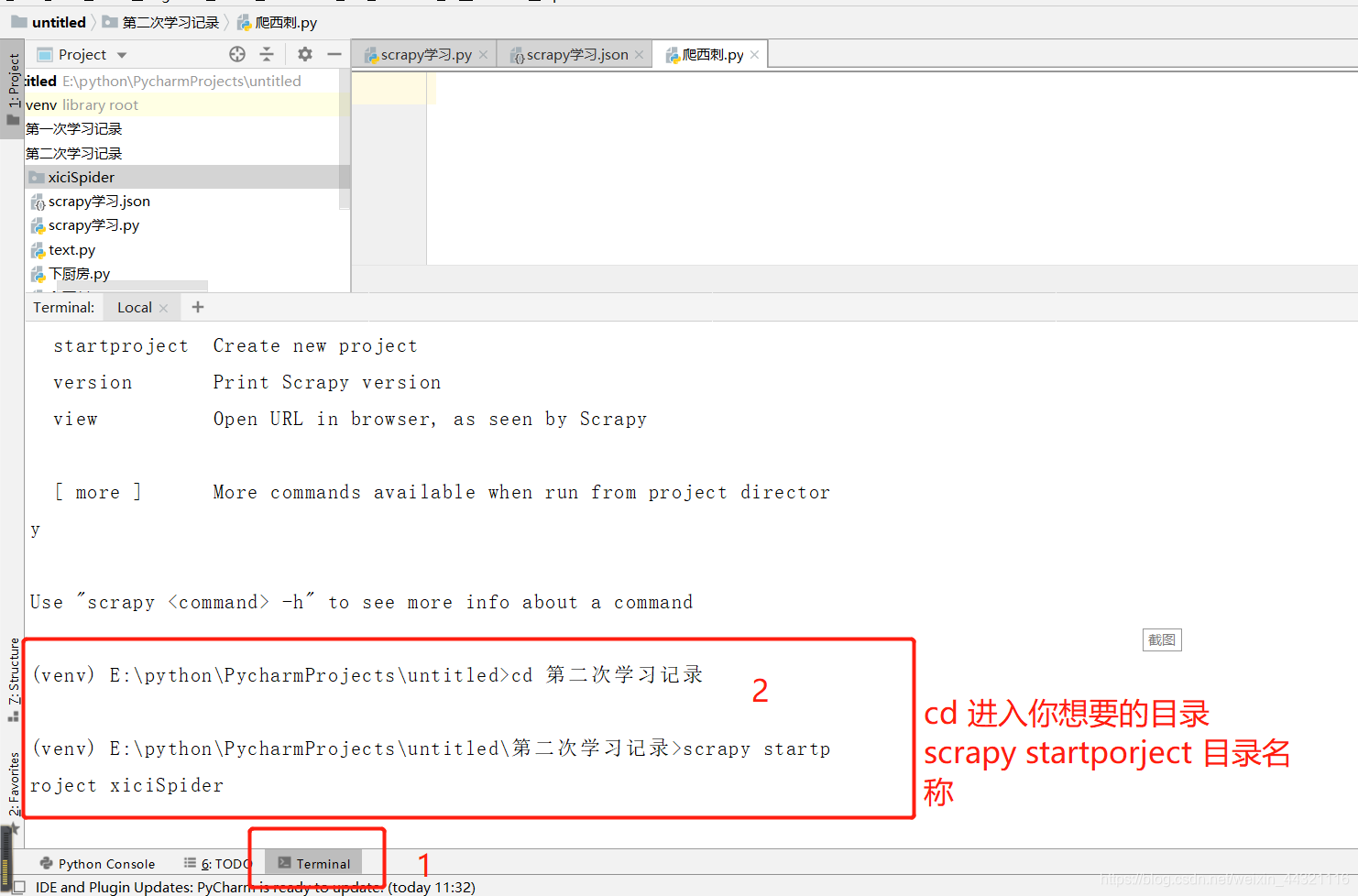
创建好的项目
二.创建爬虫
1.创建
一定要先进入刚才创建的爬虫项目文件中再创建爬虫


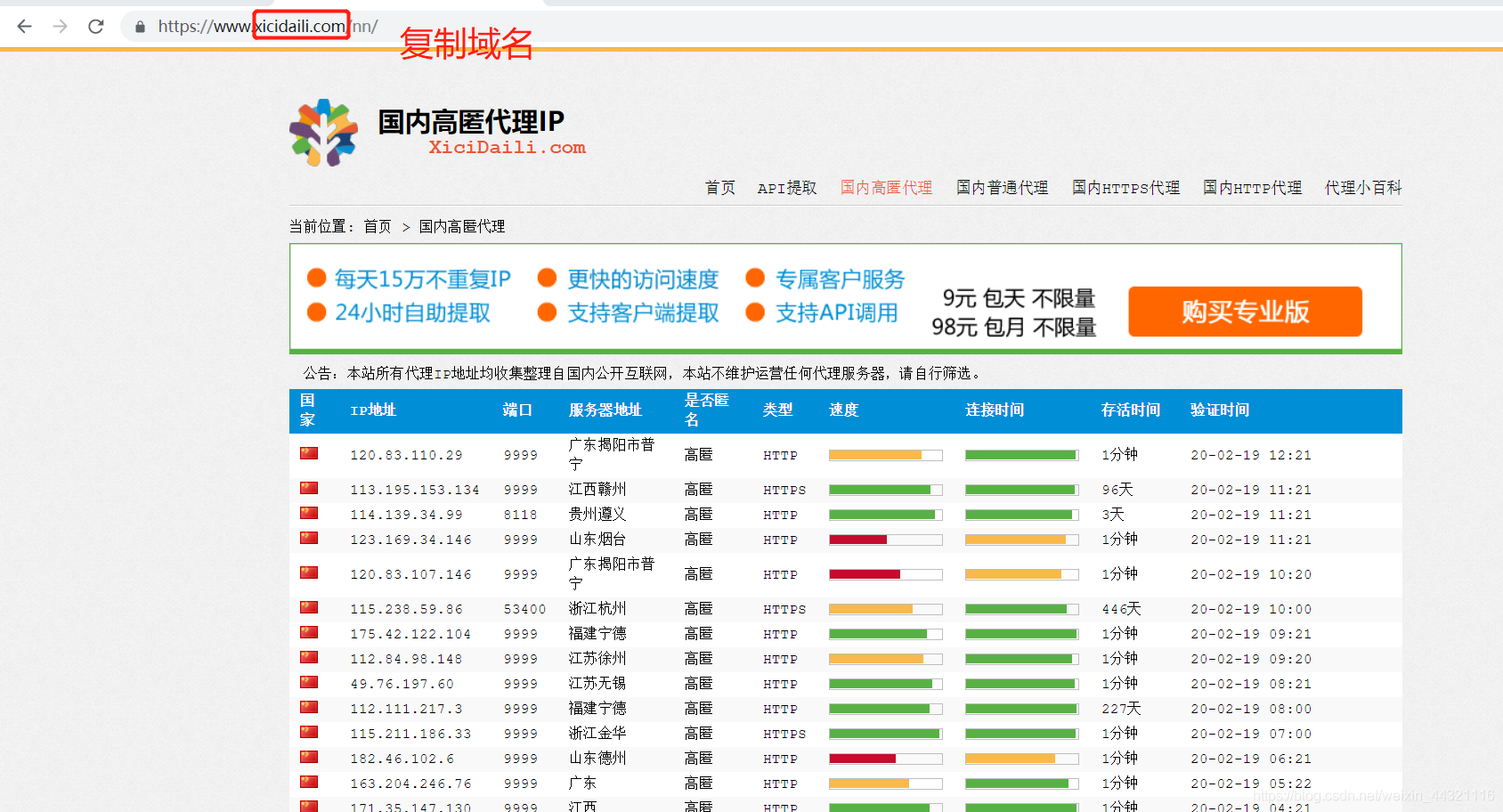
对比未创建爬虫,发现多了一个xici.py文件
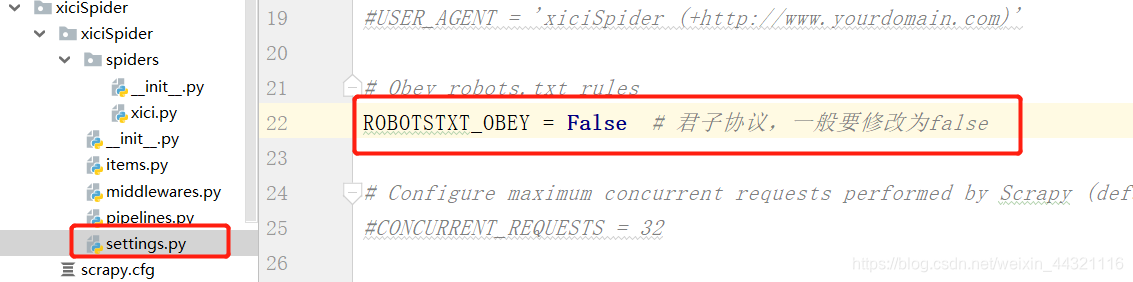
2.查看网站君子协议(robots):

3.解释爬虫文件
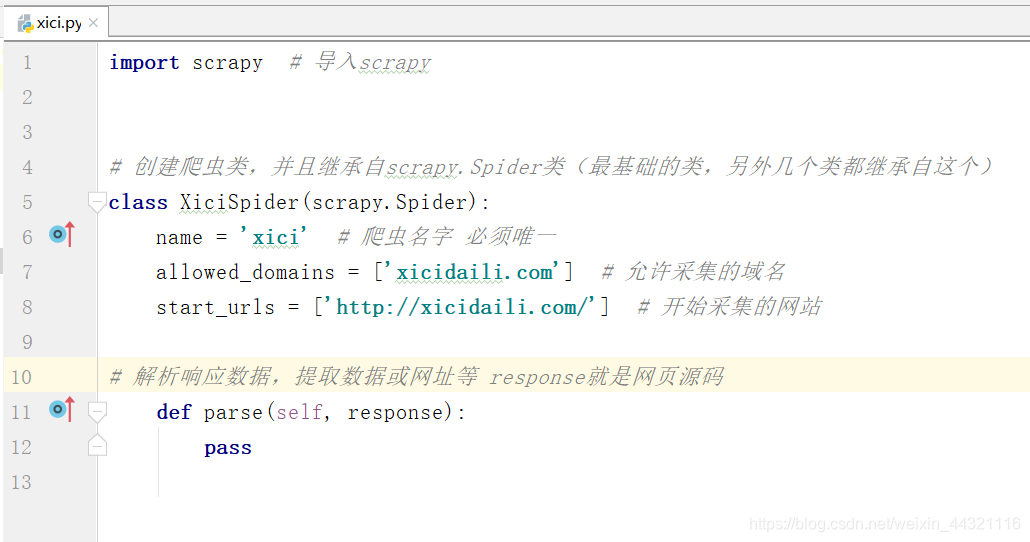
三.分析网站
1.提取数据的方法
可以参考我以前的博客
(1)正则表达式
(2)Xpath:从html中提取数据的语法
(3)CSS:从html中提取数据语法
(4)BeautifulSoup
2.用xpath提取ip和端口号
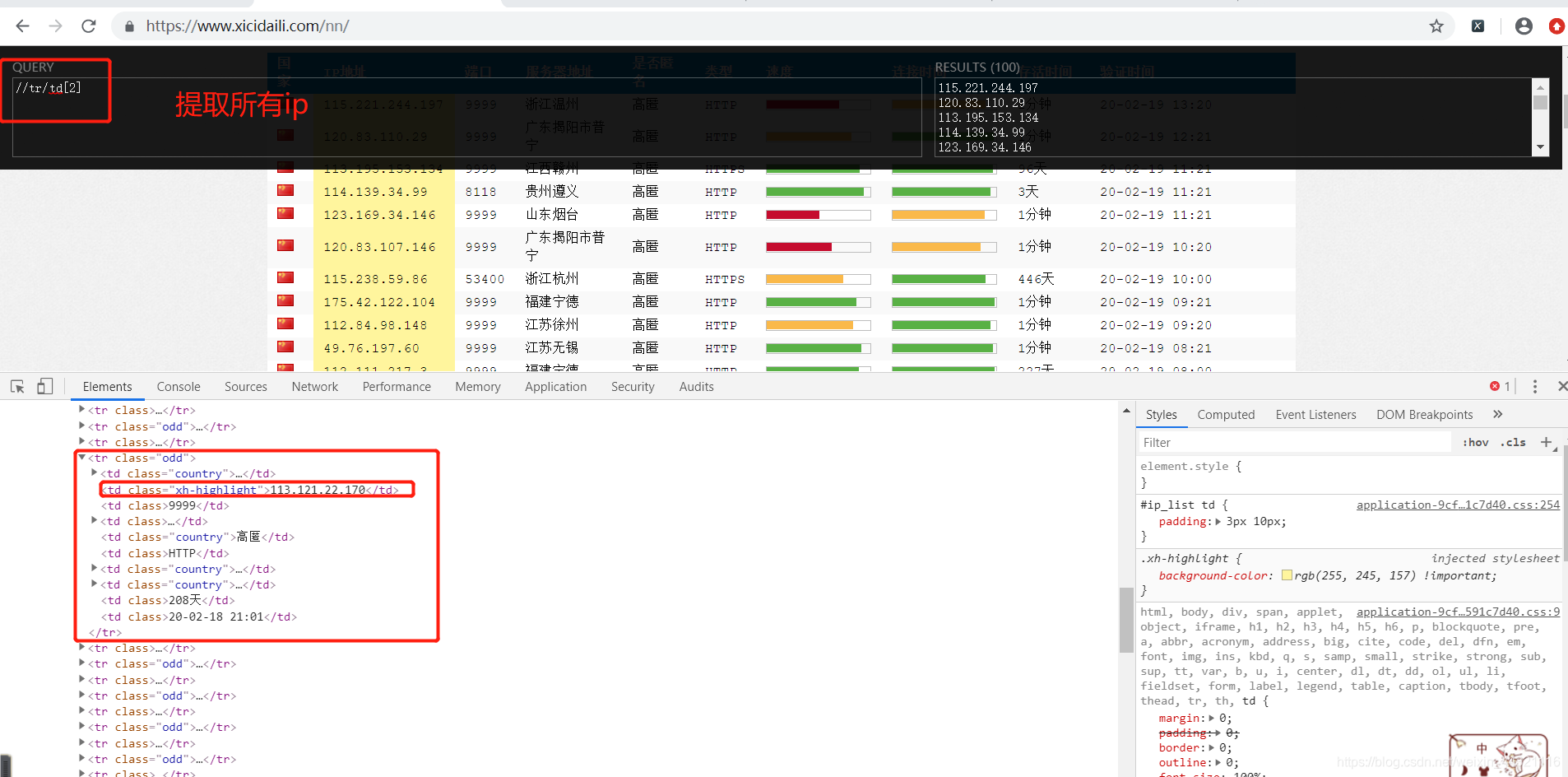
创建好的项目
一定要先进入刚才创建的爬虫项目文件中再创建爬虫
对比未创建爬虫,发现多了一个xici.py文件
可以参考我以前的博客
(1)正则表达式
(2)Xpath:从html中提取数据的语法
(3)CSS:从html中提取数据语法
(4)BeautifulSoup
 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























