






首先这是一个有点脱裤子放屁的事情,不可以搭建真实生产环境!这里用的是轻型应用服务器,不可建立对等连接,流量走的都是外网,主从之间的联系比较慢,要是想体验100%的性能请购买云主机建立对等连接或云联网,但是云主机变贵了,以后再说。其实腾讯云已经有一些弹性扩展、弹性网卡、CDN加速、Kafka消息队列、nosql数据库、微服务等等可以实现高可用、高性能的一些工具,我这里仅仅是做实验,看看能不能用更低的成本去部署环境,纯属学习娱乐。
另外,新手谨慎将云服务器的全部端口开放给外网去访问,特别特别特别容易成为肉鸡,我的hadoop密码太弱,吃个饭的功夫被植入了2款挖矿木马,凭我的技术力暂时没法解决,只能重置了,建议大家利用好快照功能,及时保存节点。
PS:强烈建议将hadoop的常见端口号更改一下,不要使用50070 50090 9000……常见的端口,在外网都很不安全,这跟我们平时使用的网络环境有很大差别。在企业还好说,有防火墙或是禁止外网访问作为保护手段,云服务器是不可能禁止外网访问的。恐怖的是有针对云服务器的‘云铲’木马,很难杀掉。
注意:搭建流程在40-50分钟,非新手向,需要会用linux的cd cat ls pwd vi等命令
成本极低,不需要用虚拟机,可以体验到集群的真正魅力。
注意注意:文中的部分命令,需要自己修改,比如文件名,需要根据您所下载的版本进行修改,有些命令我写的是3.1.1版本的,实际上我安装的是3.2.2版本的hadoop。请注意区分。
----------------------------------------------正文分割线----------------------------------------------------------------
之前利用虚拟机或是单台云服务器搭建过伪分布式集群,作为一个垃圾佬,这次想深入学习和体会一下集群真正的魅力,所以tb买了另外一个2c4g8M轻量应用服务器(80G硬盘,58/年),试试可不可以通过外网(没法用内网因为轻量级应用服务器便宜,阉割了对等连接、云联网等功能!!!)来配置一下Hadoop集群。反正我对网速没什么需求,只是实践环境搭建,不采用虚拟机是因为虚拟机并不能给我像生产环境一样真实的感觉。比如会遭到针对hadoop集群的网络攻击和木马植入……
一、准备工作:
1、登录腾讯云后台,安装centos8.2镜像,重置系统,重置密码,让系统保持一个纯净的状态。
2、根据腾讯云的教程,我安装了Putty(官方下载地址)这个远程SSH软件,安装SSH的目的是登陆服务器更方便!不用在网页上敲代码。
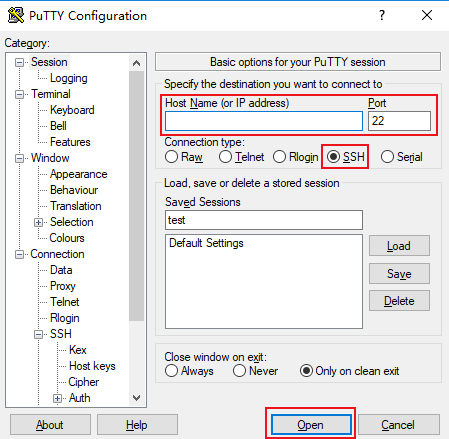
- 参数举例说明如下:
- Host Name(or IP address):轻量应用服务器的公网 IP(登录 轻量应用服务器控制台,可在服务器列表页中获取公网 IP)。
- Port:轻量应用服务器的连接端口,必须设置为22。
- Connect type:选择 “SSH”。
- Saved Sessions:填写会话名称,例如 test。
配置 “Host Name” 后,再配置 “Saved Sessions” 并保存,则后续使用时您可直接双击 “Saved Sessions” 下保存的会话名称即可登录服务器。- 单击【Open】,进入 “PuTTY” 的运行界面,提示 “login as:”。
- 在 “login as” 后输入用户名,如
root,按 Enter。- 在 “Password” 后输入密码,按 Enter。
输入的密码默认不显示,如下图所示:
- 登录完成后,命令提示符左侧将显示当前登录轻量应用服务器的信息。

3、安装了WinSCP(官方下载地址),这个软件在于方便你本地和云服务器之间传输文件。
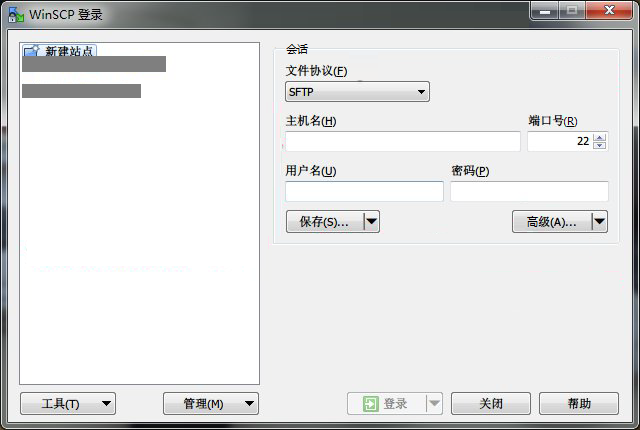
登录 WinSCP
- 打开 WinSCP,弹出“WinSCP 登录”对话框。如下图所示:
- 设置登录参数:
- 协议:选填 SFTP 或者 SCP 均可。
- 主机名:轻量应用服务器的公网 IP。登录 轻量应用服务器控制台 即可查看对应轻量应用服务器的公网 IP。
- 端口:默认为22。
- 用户名:轻量应用服务器的系统用户名。
- 密码:轻量应用服务器的用户名对应的密码。
- 单击【登录】,进入 “WinSCP” 文件传输界面。如下图所示:
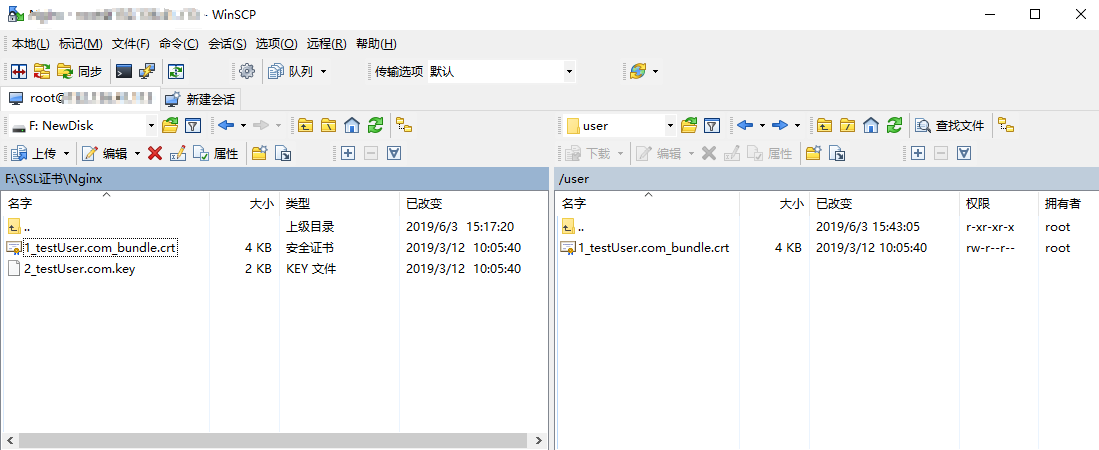
上传文件
- 在 “WinSCP” 文件传输界面的右侧窗格中,选择文件在服务器中待存放的目录,如“/user”。
- 在 “WinSCP” 文件传输界面的左侧窗格中,选择本地计算机存放文件的目录,如“F:\SSL证书\Nginx”,选中待传输的文件。
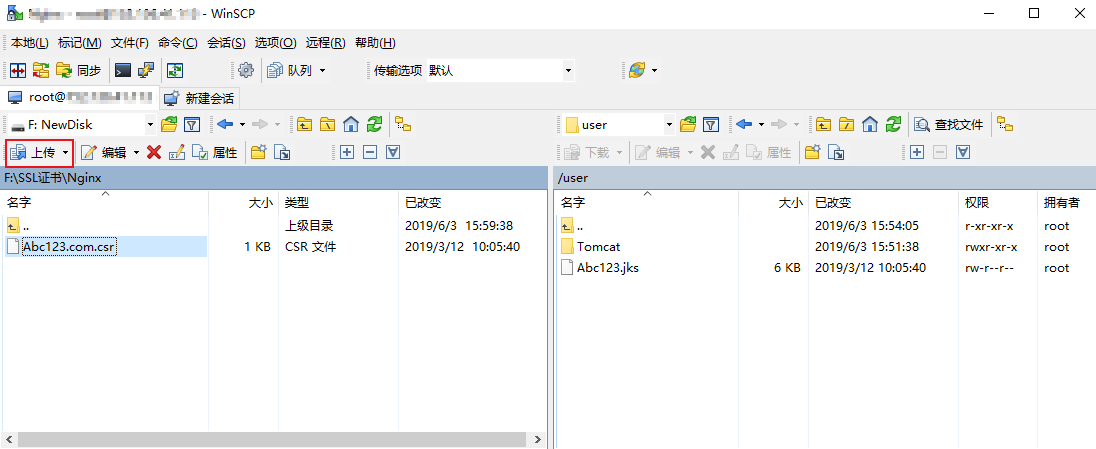
- 在 “WinSCP” 文件传输界面的左侧菜单栏中,单击【上传】。如下图所示:
- 在弹出的“上传”对话框中,确认需要上传的文件及远程目录,单击【确定】,即可从本地计算机将文件上传到轻量应用服务器中。
下载文件
- 在 “WinSCP” 文件传输界面的左侧窗格中,选择待下载至本地计算机的存放目录,如“F:\SSL证书\Nginx”。
- 在 “WinSCP” 文件传输界面是右侧窗格中,选择服务器存放文件的目录,如“/user”,选中待传输的文件。
- 在 “WinSCP” 文件传输界面的右侧菜单栏中,单击【下载】。如下图所示:
- 在弹出的“下载”对话框中,确认需要下载的文件及远程目录,单击【确定】,即可从轻量应用服务器将文件下载到本地计算机中。
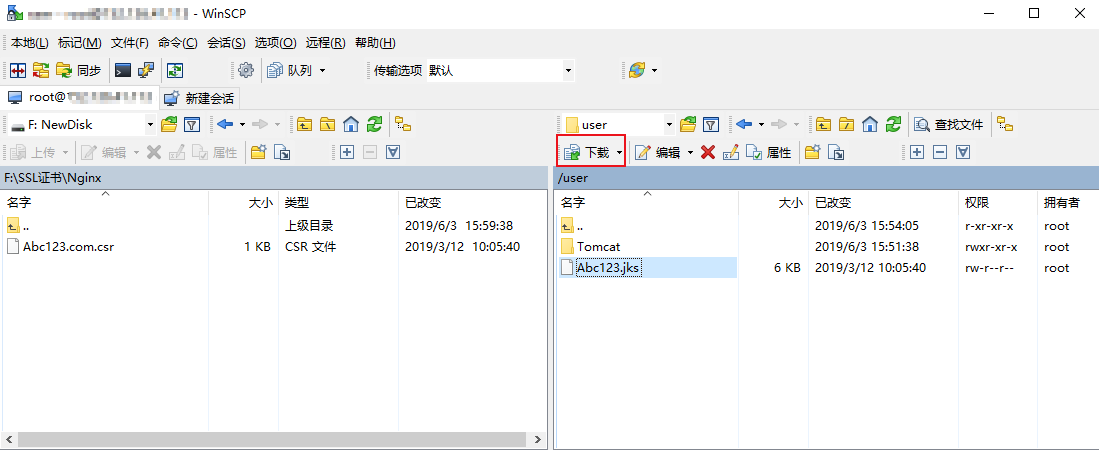
ps:另外一台云服务器同理。
二、环境搭建
准备工作OK了,开始搭建环境。
创建hadoop用户
如果你安装 CentOS 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先点击左上角的 “应用程序” -> “系统工具” -> “终端”,首先在终端中输入
su,按回车,输入 root 密码以 root 用户登录,接着执行命令创建新用户 hadoop:su # 上述提到的以 root 用户登录 useradd -m hadoop -s /bin/bash # 创建新用户hadoop如下图所示,这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为shell。
CentOS创建hadoop用户
接着使用如下命令修改密码,按提示输入两次密码,可简单的设为 “hadoop”(密码随意指定,若提示“无效的密码,过于简单”则再次输入确认就行):
passwd hadoop可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题,执行:
visudo如下图,找到
root ALL=(ALL) ALL这行(应该在第98行,可以先按一下键盘上的ESC键,然后输入:98(按一下冒号,接着输入98,再按回车键),可以直接跳到第98行 ),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL(当中的间隔为tab),如下图所示:
为hadoop增加sudo权限
添加上一行内容后,先按一下键盘上的
ESC键,然后输入:wq(输入冒号还有wq,这是vi/vim编辑器的保存方法),再按回车键保存退出就可以了。最后注销当前用户(点击屏幕右上角的用户名,选择退出->注销),在登陆界面使用刚创建的 hadoop 用户进行登陆。(如果已经是 hadoop 用户,且在终端中使用
su登录了 root 用户,那么需要执行exit退出 root 用户状态)


安装JAVA环境
安装hadoop3.X需要JDK8以上支持
wget https://download.oracle.com/otn/java/jdk/8u301-b09/d3c52aa6bfa54d3ca74e617f18309292/jdk-8u301-linux-x64.tar.gz地址经常换,这个是需要你去官网重新下载的。
cd /usr/lib sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件 cd ~ #进入hadoop用户的主目录 cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下 sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下上面使用了解压缩命令tar,如果对Linux命令不熟悉,可以参考常用的Linux命令用法。
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
- cd /usr/lib/jvm
- ls
可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_301目录。
下面继续执行如下命令,设置环境变量:
- cd ~
- vim ~/.bashrc
Shell 命令
上面命令使用vim编辑器(查看vim编辑器使用方法)打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_301 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
- source ~/.bashrc
这时,可以使用如下命令查看是否安装成功:
- java -version
如果能够在屏幕上返回如下信息,则说明安装成功:
hadoop@ubuntu:~$ java -version java version "1.8.0_301" Java(TM) SE Runtime Environment (build 1.8.0_162-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)至此,就成功安装了Java环境。下面就可以进入Hadoop的安装。
安装 Hadoop3.1.3
Hadoop安装文件,可以到https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz镜像站:https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz镜像站:https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
下载hadoop-3.1.3.tar.gz。
也可以直接点击这里从百度云盘下载软件(提取码:lnwl),进入百度网盘后,进入“软件”目录,找到hadoop-3.1.3.tar.gz文件,下载到本地。
我们选择将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version 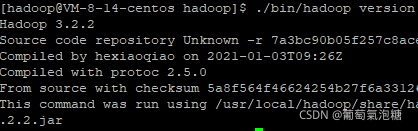
安装成功。安装另外一台服务器。
配置PATH变量
可以将 Hadoop 安装目录加入 PATH 变量中,这样就可以在任意目录中直接使用 hadoo、hdfs 等命令了,如果还没有配置的,需要在 Master 节点上进行配置。首先执行 vim ~/.bashrc,加入一行:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
如下图所示:

保存后执行 source ~/.bashrc 使配置生效(很重要)。
配置集群/分布式环境
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1, 文件 slaves(3.2.2版本叫workers),将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
本教程让 Master 节点既作为 NameNode 使用,又作为Datenode,所以再添加一行内容:Slave1。
文件中为:
localhost
Slave1
2, 文件 core-site.xml 改为下面的配置:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>3, 文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有2个 Slave 节点,所以 dfs.replication 的值还是设为 2:
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>Master:50090</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>4, 文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>Master:19888</value> </property> </configuration>5, 文件 yarn-site.xml:
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master 节点上执行:
cd /usr/local sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件 sudo rm -r ./hadoop/logs/* # 删除日志文件 tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制 cd ~ scp ./hadoop.master.tar.gz Slave1:/home/hadoop在 Slave1 节点上执行:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在) sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local sudo chown -R hadoop /usr/local/hadoop同样,如果有其他 Slave 节点,也要执行将 hadoop.master.tar.gz 传输到 Slave 节点、在 Slave 节点解压文件的操作。
首次启动需要先在 Master 节点执行 NameNode 的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后不需要个人经验:如果未来出现奇怪的问题,需要初始化,请删除各个节点(主、从)hadoop下tmp内的所有文件,以及logs中的所有文件。我刚才所说的tmp和logs文件夹分别是在hdfs-site.xml、core-site.xml 两个文件中设定的,不建议您看两篇教程,容易弄混。
免密登录ssh设置
这一步很重要,关系到启动成功与否
在hadoop用户下,终端输入
ssh-keygen -t rsa一路回车,有yes输yes
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys在master主机上,传输公钥到slave1机(这一步从机需要执行下边的语句)
ssh-copy-id -i slave1Slave1机器上操作上述步骤后,输入
ssh-copy-id -i master配置结束后,在Master主机上Hadoop用户下,SSH Slave1试试是否可以免密码登录,同样在Slave1也对Mater试试SSH密钥登录。确认可以不用输入密码了才可以进行下一步。
网络配置(新人注意 这一步比较重要)
为了便于区分,可以修改各个节点的主机名(在终端标题、命令行中可以看到主机名,以便区分)。在 Ubuntu/CentOS 7 中,我们在 Master 节点上执行如下命令修改主机名(即改为 Master,注意是区分大小写的):
sudo vim /etc/hostname此时可以看见只有一行主机名,清空掉,改成Master就好了
然后执行如下命令修改自己所用节点的IP映射:
sudo vim /etc/hosts例如本教程使用两个节点的名称与对应的 IP 关系如下:
192.168.1.121 Master #此处的IP地址应该填您自己电脑的IP,用ifconfig查询本地ip
192.168.1.122 Slave1 #此处的IP地址应该填另外一台从节点的IP,或用腾讯云查询,这里我用的是公网连接。(成本所限)
192.168.1.121 Master #此处的IP地址应该填您自己电脑的IP,用ifconfig查询本地ip
192.168.1.122 Slave1 #此处的IP地址应该填另外一台从节点的IP,或用腾讯云查询,这里我用的是公网连接。(成本所限)CentOS 中的 /etc/hosts 配置则如下图所示:
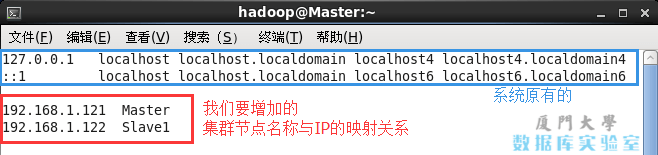
CentOS中的hosts设置
修改完成后需要重启一下,重启后在终端中才会看到机器名的变化。接下来的教程中请注意区分 Master 节点与 Slave 节点的操作。
需要在所有节点上完成网络配置。如上面讲的是 Master 节点的配置,而在其他的 Slave 节点上,也要对 /etc/hostname(修改为 Slave1、Slave2 等) 和 /etc/hosts(跟 Master 的配置一样)这两个文件进行修改!
这一步千万要配置对,不然的话后边奇奇怪怪的问题根本解决不了!亲身经历!!!!!
hosts 很 重 要!!!!!
格式化Namenode
在Master上
cd ~
hadoop namenode -format对hdfs进行格式化操作。
接着可以启动 hadoop 了,启动需要在 Master 节点上进行:
start-all.sh 通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到6个进程:
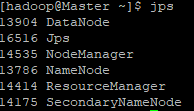
Slave1:

6个进程 3个进程都开启了,才算成功,这时候我们可以访问一下Master的Namenode网站:打开任意浏览器,输入49.10.30.40:9870 #这里49.10.30.40是我Master的外网IP,如果用内网访问请输入Master的内网地址。
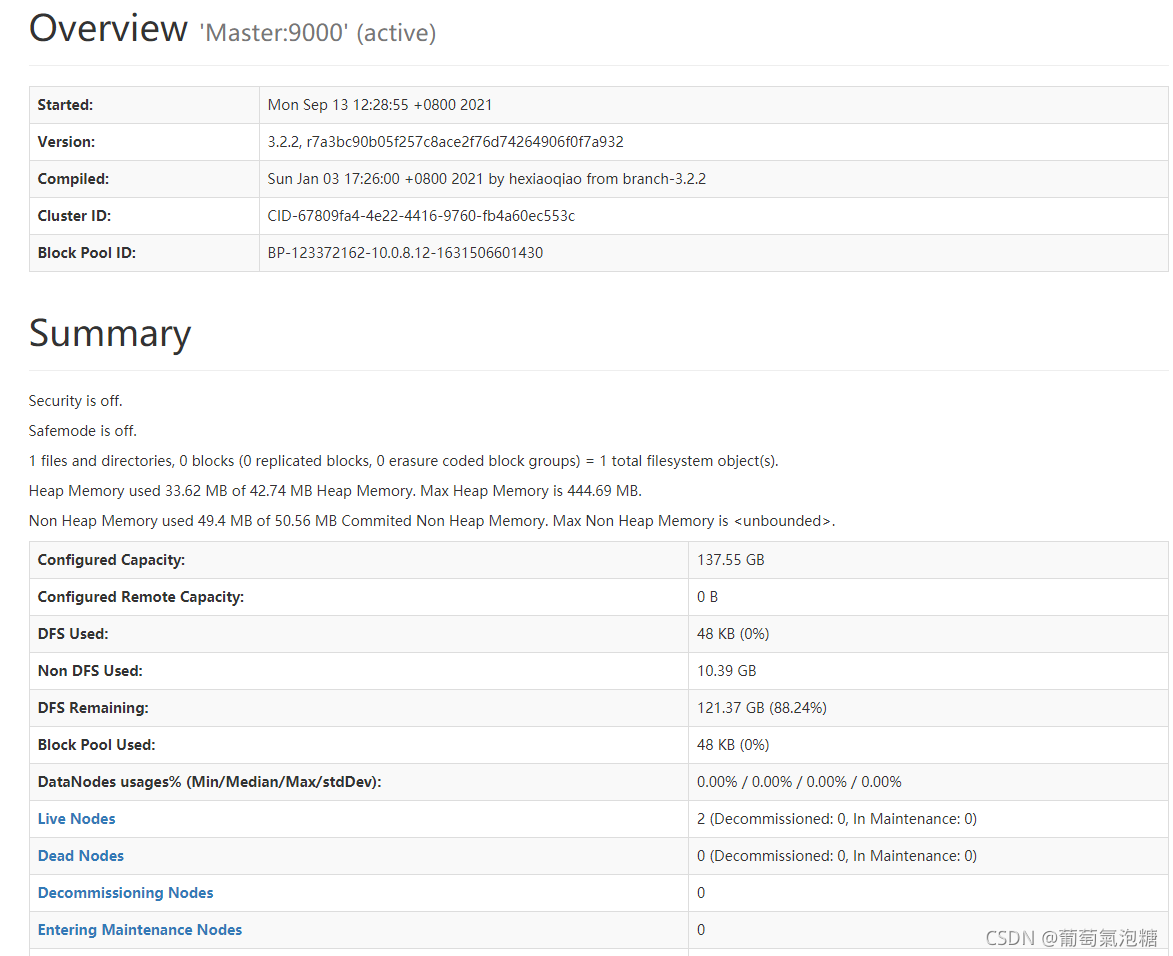
在这里我们可以看到,hadoop的版本是3.2.2
总容量是137.55G(两台轻量级应用服务器60G+80G),DFS使用了48KB(空的,用来存放块池?),非DFS使用了10.39GB(系统占用等),DFS剩余容量121.37GB,正在活动的节点数为2。这里我的master既作为Namenode又作为了Datanode,所以是2。

至此搭建完毕,还有一些奇奇怪怪的问题,欢迎留言。
别人的教程里边说了要关闭防火墙,但是我装了CENTOS8.2+Hadoop3.2.2,目前正常运行,没有出现问题,为了安全起见,我暂时不关闭了。以后如果有问题,再关吧。被木马吓到了。
CentOS系统需要关闭防火墙
CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。
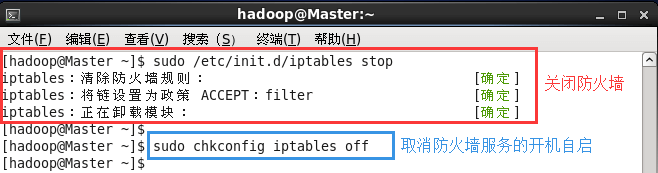
在 CentOS 6.x 中,可以通过如下命令关闭防火墙:
sudo service iptables stop # 关闭防火墙服务 sudo chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了若用是 CentOS 7,需通过如下命令关闭(防火墙服务改成了 firewall):
systemctl stop firewalld.service # 关闭firewall systemctl disable firewalld.service # 禁止firewall开机启动如下图,是在 CentOS 6.x 中关闭防火墙:
CentOS6.x系统关闭防火墙
最后还有一个小插曲,我在下午出去吃个饭的过程中,我的服务器就被黑了,植入了一个木马(IP地址为荷兰),具体表现为cpu占用率100%,我猜测的原因是我用户密码强度太低(腾讯云充分暴露在外网中,其实网络环境真的很可怕!),我去百度搜了一下发现腾讯云服务器不少都被植入过这个木马,大家一定要提高密码强度,不要怕麻烦。实在麻烦用秘钥登录SSH。(2021.9.14更新: 是我太天真,人家这个木马就是利用SSH秘钥进行集群感染的……emmm网络安全还需要上一课。)
引用文章:(文章中部分需要更改为Hadoop3.x版本的内容,注意区分。)Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS_厦大数据库实验室博客 (xmu.edu.cn)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









