







 本文介绍了TabNet,一个针对表格数据的深度学习模型,对比了其与xgboost和lightgbm等传统算法的效果。通过官方提供的pytorch实现,展示了TabNet在单任务和多任务回归任务上的应用,强调了数据量越大,TabNet的表现越优。代码示例详细解释了如何预处理数据、训练模型以及保存和加载模型。
本文介绍了TabNet,一个针对表格数据的深度学习模型,对比了其与xgboost和lightgbm等传统算法的效果。通过官方提供的pytorch实现,展示了TabNet在单任务和多任务回归任务上的应用,强调了数据量越大,TabNet的表现越优。代码示例详细解释了如何预处理数据、训练模型以及保存和加载模型。
前言
比肩xgboost和lightgbm表格数据的最强神器tabnet,而2020年退出的tabnet神经网络专门针对表格数据而诞生的神器。
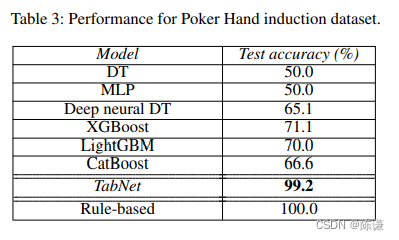
上图是官网的论文给出的效果,我们可以看出来,catnet效果还是不错的,而且数据量越大效果比机器学习的更好。
`
一、官网的实战案例
1.pytorch版的回归任务
from pytorch_tabnet.tab_model import TabNetRegressor
import torch
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
import pandas as pd
import numpy as np
import os
import wget
from pathlib import Path
np.random.seed(0)
"导入数据"
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
dataset_name = 'census-income'
out = Path(os.getcwd()+'/data/'+dataset_name+'.csv')
out.parent.mkdir(parents=True, exist_ok=True)
if out.exists():
print("File already exists.")
else:
print("Downloading file...")
wget.download(url, out.as_posix())
train = pd.read_csv(out)
target = ' <=50K'
if "Set" not in train.columns:
train["Set"] = np.random.choice(["train", "valid", "test"], p =[.8, .1, .1], size=(train.shape[0],))
train_indices = train[train.Set=="train"].index
valid_indices = train[train.Set=="valid"].index
test_indices = train[train.Set=="test"].index
categorical_columns = []
categorical_dims = {
}
for col in train.columns[train.dtypes == object]:
print(col, train[col].nunique())
l_enc = LabelEncoder()
train[col] = train[col].fillna("VV_likely")
train[col] = l_enc.fit_transform(train[col].values)
categorical_columns.append(col)
categorical_dims[col] = len(< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









