







 本文介绍了k近邻(k-NN)算法的基本原理和步骤,包括计算距离、排序、选择最近邻及确定分类。在实际应用中,作者在实现k-NN算法时遇到TypeError问题,主要是由于使用了不可哈希的numpy.ndarray。通过尝试修改变量名和转换为numpy数组来解决问题,但仍然面临挑战,文章提供了部分源代码供读者参考。
本文介绍了k近邻(k-NN)算法的基本原理和步骤,包括计算距离、排序、选择最近邻及确定分类。在实际应用中,作者在实现k-NN算法时遇到TypeError问题,主要是由于使用了不可哈希的numpy.ndarray。通过尝试修改变量名和转换为numpy数组来解决问题,但仍然面临挑战,文章提供了部分源代码供读者参考。
一.算法设计
k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
k-近邻算法步骤如下:
获取数据集,分析数据;
数据集划分;
使用KNN算法处理数据:
1.计算已知类别数据集中的点与当前点之间的距离;根据欧式距离公式
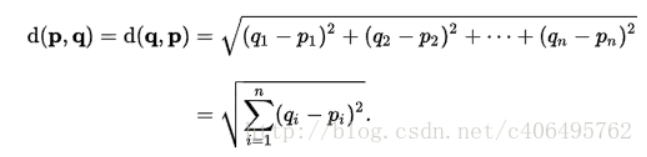
2.按照距离递增次序排序;
3.选取与当前点距离最小的k个点;
4.确定前k个点所在类别的出现次数;
5.返回前k个点所出现次数最高的类别作为当前点的预测分类。
二.有注释的源代码
def knn(x_test,x_data,y_data,k):
# 计算样本数量
x_data_size=x_data.shape[0]
# 复制x_test
np.tile(x_test,(x_data_size,1))
# 计算x_test与每一个样本的差值
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3199
3199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









